# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国产AI,正式把视频生成拉进了有声电影时代。
自从Sora引爆视频生成之后,基本上所有AI生成的视频都属于“默片”的效果,也就是没有对应的音效(注意不是配乐)。
但现在,音效是可以直接自带了!而且还是4K、60帧高清画质的那种。
那么AI视频生成现在能到什么水平?
我们直接拿这个国产AI做了个微电影,请看VCR:

如何?是不是已经有电影的那个feel了?
这个国产AI,正是智谱刚升级的新清影,总体来看有三大特点:
如此一来,AI已经具备了制作像上面这样微电影(或短视频)的全要素,而且在操作上也是非常简单。
我们先把一个主题“喂给”智谱清言的GLM 4 Plus,让它帮我们生成微电影的脚本:
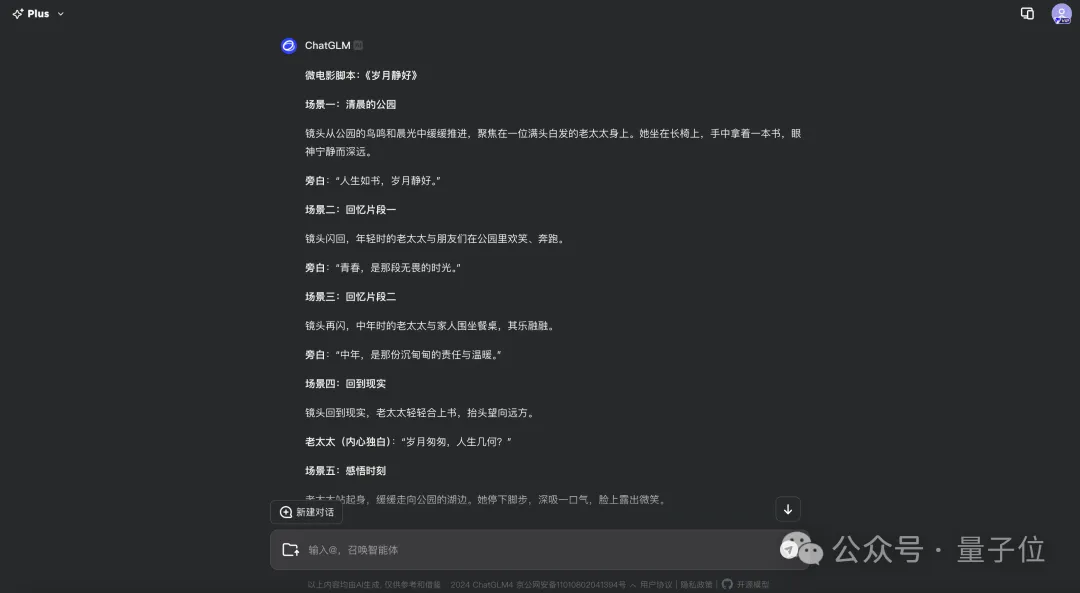
然后我们再用文生图的AI,生成几张高清大图,以开头片段为例,Prompt是这样的:
镜头从公园的鸟鸣和晨光中缓缓推进,聚焦在一位满头白发的老太太身上。她坐在长椅上,手中拿着一本书,眼神宁静而深远。

再进入新清影的图生视频界面,把这张图像传上去,并填写想要效果的prompt:
镜头从公园的鸟鸣和晨光中缓缓推进,聚焦在一位满头白发的老太太身上。她坐在长椅上,缓缓把书合上,望向远方陷入深思。
接着在下方面选择基础参数即可:
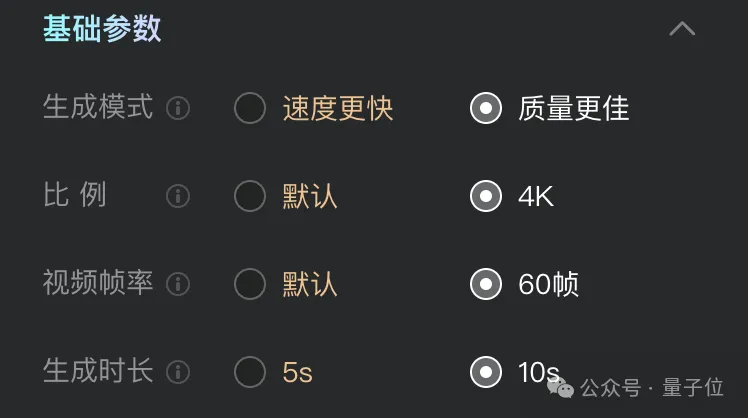
在静候片刻之后,一段电影级别、自带音效的高清视频片段就这么水灵灵的诞生了。
重复上面的方法,我们便可以得到后边的那些视频片段。
至于旁白部分,采用的则是智谱在前不久刚发布的GLM-4-Voice情感语音模型,可以做到宛如真人配音。
嗯,打得就是一套智谱的AI组合拳。
而联想人类从第一部无声电影(1895年)到第一部有声电影(1927年),足足花费了32年。
若是从Sora算起,那么AI生成的视频从无声到有声,耗时仅仅9个月。
此时此刻,“AI一天,人间一年”这句话,是真真儿的具象化了。
那么智谱的CogSound模型还能hold住什么样的音效?
我们这就来一波实测。
实测方法也是非常简单,我们会截取电影中的视频片段作为输入,考验的就是它能否对视频内容深入理解,并生成没有违和感的音效。
我们先取一段雨天傍晚房间里的一个视频,把它“喂”给CogSound模型(注:以下原视频都是无声的),生成出来的音效是这样的:

CogSound精准地get到了“下雨”这个关键元素,从音效上来看也是毫无违和感。
再来欣赏一段由清影生成、CogSound加音效的视频片段:

我们再来试试CogSound能否看视频识别出动物的声音:

CogSound不仅生成出了狮子妈妈低沉的叫声,也发觉到了它们处于自然环境之下,还配上了鸟鸣的声音。
接下来,我们上个难度,输入一段有多个乐器演奏的视频频段:

可以看到,从视频一开始的画面来看,萨克斯这个乐器应当是“主角”,所以在乐器混合的音效中,萨克斯的声音是最大的。
而当萨克斯手用力吹奏的时候,CogSound配的音效竟也有了音乐上的起伏,说实话,这一点确实是有点令人意外。
但要非挑个问题的话,或许镜头在转向钢琴的时候,乐器的音效上,钢琴声音变大一些会更好些。
最后,我们再“喂”一个超级复杂的视频片段——《流浪地球》:

讲真,若不是知道这是CogSound生成的,很多人应该都会认为它是电影原声了吧。
由此可见,不论“喂”给CogSound模型什么类型的视频,它都可以做到对视频内容的精准理解,并且给出对应音效。
除此之外,在视频本身生成的能力上,智谱的CogVideo也有了大幅的提升。
例如生成的下面这位老爷爷,情绪和表情的变化,宛如在看一个电影片段:

还有像非常科幻的火焰老虎:

而从上面两个例子中,我们也不难发现,CogVideoX现在是可以支持多种比例视频的生成。
那么接下来的问题就是:
首先是CogVideo的升级,主要集中体现在了内容连贯性、可控性和训练效率等方面的能力提升。
其整体的模型框架如下图所示,是基于多个专家Transformer模块,通过文本编码器将输入的文本转化为潜在向量,再经由3D卷积和多层专家模块处理,生成连续的视频序列。
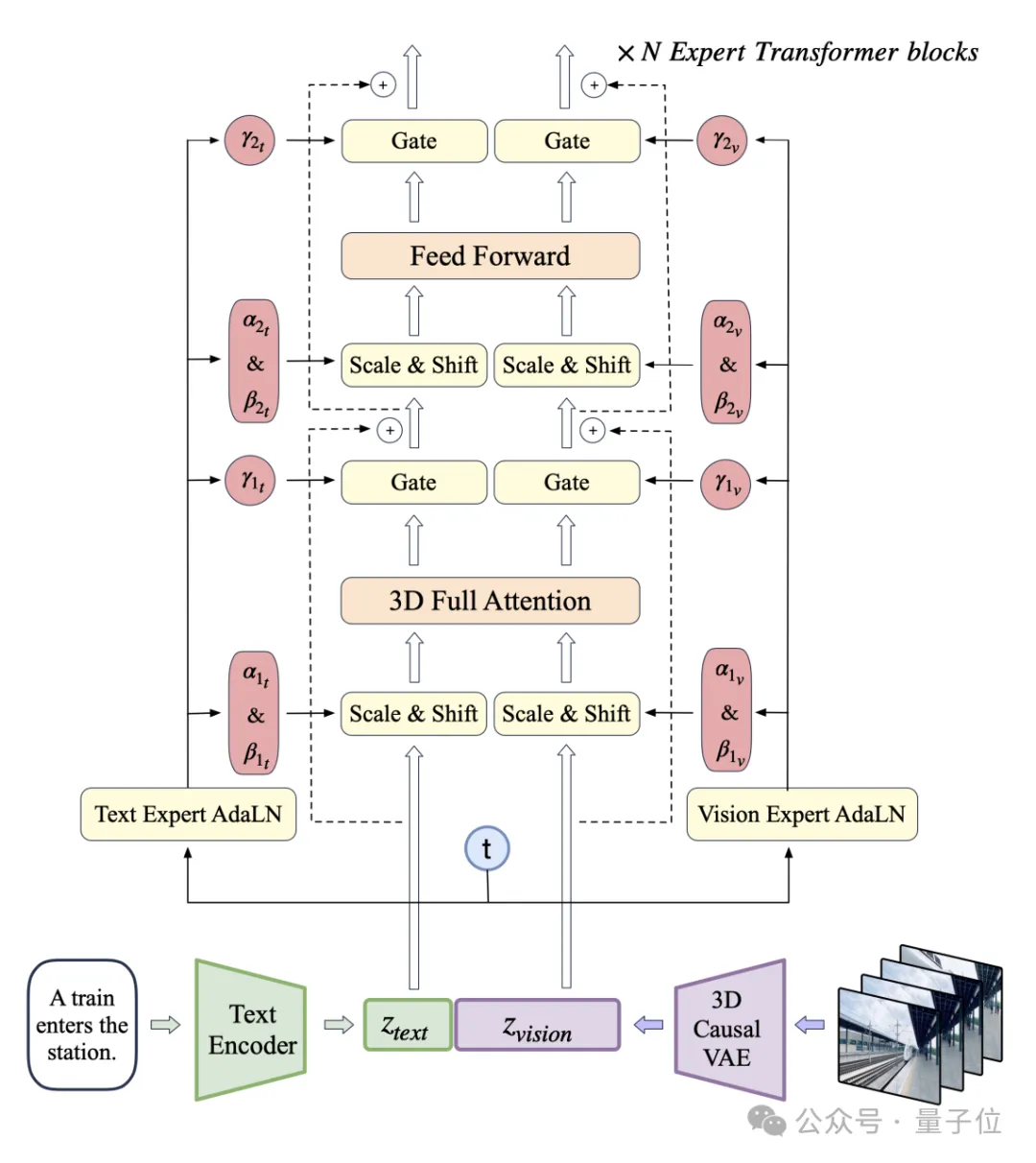
整个过程可视为将自然语言描述转化为动态视觉内容的复杂系统。
在模型架构设计中,CogVideoX特别采用了因果3D卷积(Causal 3D Convolution),以高效捕捉时空维度上的复杂变化,使得模型能够更加精确地理解和生成富有细节的场景。
同时,该模型引入了专家自适应层归一化(AdaLN),通过动态调整不同模块的特性,从而在视觉表现上实现更自然、更具连贯性的视频生成。
为了应对视频压缩与计算效率的挑战,CogVideoX采用了3D VAE结构,通过对视频特征在空间和时间上的下采样,大幅降低了视频存储与计算开销。
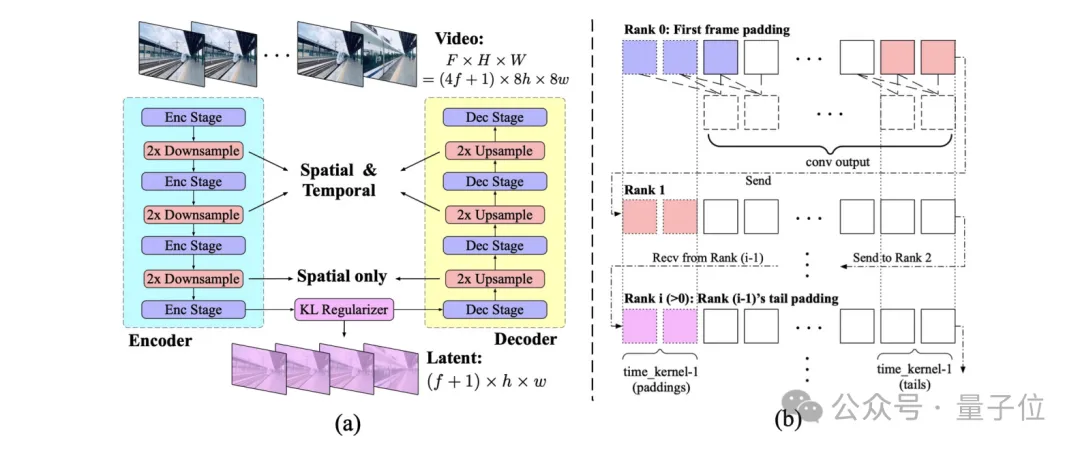
这意味着即便在资源有限的计算环境下,CogVideoX仍能生成高质量的视频内容,显著提升了其应用的可行性。
如果说CogVideoX负责生成可视的动态内容,那么CogSound则赋予这些画面以听觉上的生命。
CogSound是一种为无声视频自动生成音效的模型,能够基于视频内容智能合成背景音乐、对话音频及环境音效,其架构如下图所示:
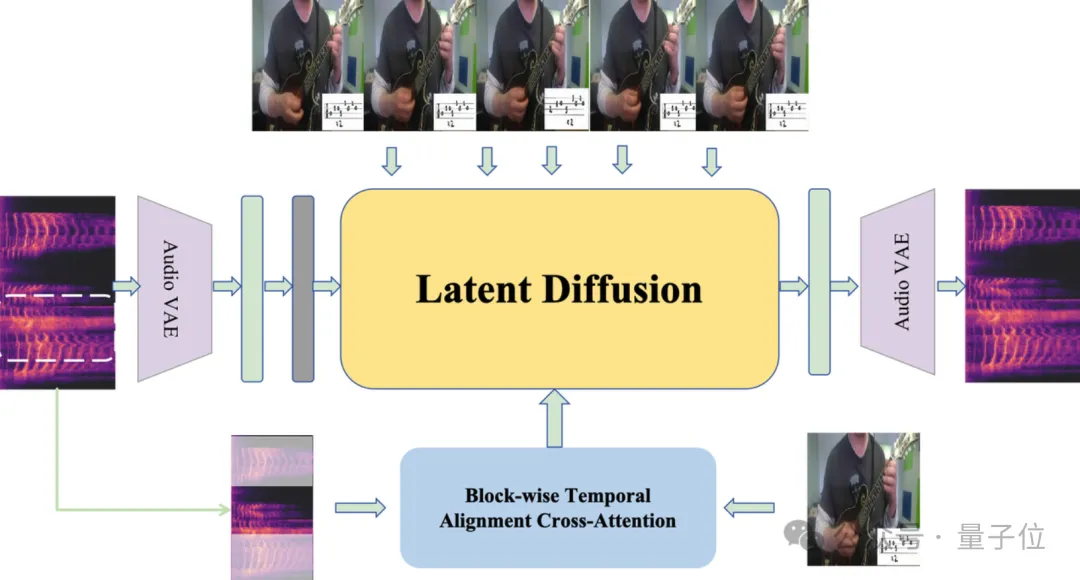
CogSound的核心技术依托于GLM-4V的多模态理解能力,能够精确解析视频中的语义和情感,并生成匹配的音效。
例如,在展示森林景观的视频中,CogSound能够生成鸟鸣和风吹树叶的声音;而在城市街景中,则会生成车流与人群的背景噪音。
为实现这一目标,CogSound利用了潜空间扩散模型(Latent Diffusion Model),通过将音频特征从高维空间进行压缩并再扩展,从而有效地生成复杂音效。
此外,CogSound通过块级时间对齐交叉注意力(Block-wise Temporal Alignment Cross-attention)机制,确保生成的音频在时间维度和语义上与视频内容高度一致,避免了传统音画合成中常见的错位和不协调问题。
这便是智谱CogVideoX能力提升和CogSound背后的技术秘笈了。
多模态是通往AGI的必经之路。
这是智谱在很早之前便提出的一个认知,而随着此次CogSound的发布,其多模态的矩阵可谓是再添一块拼图。
而它的多模态之路,可以追溯到2021年,具体到细节领域分别是:
文本生成(GLM)、图像生成(CogView)、视频生成(CogVideoX)、音效生成(CogSound)、音乐生成(CogMusic)、端对端语音(GLM-4-Voice)、自主代理(AutoGLM)。
若问这一步步走来,对现在的技术和行业带来了哪些改变,答案或许是——
起码在短视频制作领域,是时候可以迈入AI时代了。
首先就是更高质量、更符合物理世界规则的生成视频,在内容逻辑和视觉上基本上可以够到短视频制作的门槛。
加之CogVideoX还支持非常多的尺寸,更符合用户在各种场景下的制作需求。
而最为关键的一点,随着CogSound把视频生成拉进“有声电影”时代,使得输出的结果不仅满足了视觉的要求,更是符合了真实物理世界中的听觉要求。
正如智谱所言:
真正的智能一定是多模态的,听觉、视觉、触觉等共同参与了人脑认知能力的形成。
据悉,CogSound即将在智谱清言上线,而且智谱还将发布音乐模型CogMusic。
加之此前已经发布的GLM-4-Voice人声模型,智谱可以说是把视频生成中的“音”这块全面hold住。
总而言之,现在做短视频,或许就成了有想法就能实现的事儿了。
文章来自于微信公众号 “量子位”,作者“金磊”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
