# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型的记忆限制被打破了,变相实现“无限长”上下文。
最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。

LLMxMapReduce技术通过将长上下文切分为多个片段,可以让模型并行处理多个片段,并从不同片段中提取关键信息,然后汇总成为最终的答案。
特别地,团队提出结构化通信协议和上下文置信度校准机制,实现对跨片段信息更有效的处理。这项技术可以打破大模型的记忆限制,实现上下文长度无限稳定拓展。
LLMxMapReduce技术可作为大模型的长文本上分神器——它对大模型长文本能力具有普遍增强作用,且在文本不断加长的情况下,仍能保持稳定性能、减少长文本的掉分情况。
比如结合了LLMxMapReduce框架之后的Llama3-70B-Instruct x MapReduce模型得分超越了包含Kimi、GPT-4在内的知名闭源和开源模型以及其他基于Llama3-70B-Instruct的分治方法(即LongAgent和Chain-of-Agents)。
此外,LLMxMapReduce框架展现出较强的通用性,结合Qwen2-72B和MiniCPM3也取得了优异的成绩。
在大数据领域,MapReduce是一种分布式并行编程框架,具有横向扩展的数据处理能力。受到MapReduce所体现的“分而治之”思想的启发,研究人员设计了一种面向大模型的采用分治策略的长文本处理框架,称为LLMxMapReduce。
通过将长上下文切分为多个片段,LLMxMapReduce让模型并行处理多个片段,并从不同片段中提取关键信息,然后汇总成为最终的答案,从而实现无限长文本。这一技术对模型长文本能力具有普遍增强作用,且在文本不断加长的情况下,仍能保持稳定性能、减少长文本的掉分情况。
最近,也有一些同类型的分治式长文本处理方法,比如LongAgent和Chain-of-Agents。相比于模型一次处理完整长文档,这类分治式长文本处理既有优势,也有不足。
优势主要在于:长度可扩展,不受限于模型本身的窗口大小,理论上可以支持任意长度输入。
劣势主要在于:将一个完整的长文档切分为多个片段,可能会破坏跨片段的关键信息,导致模型根据某个片段“断章取义”,产生错误结论。团队分析,会被切分片段影响的信息有两类:
为了解决这两类问题,LLMxMapReduce分别设计了以下方案:
{ Extracted Information: XXX # 与问题相关的关键信息 Rationale: XXX # 得出中间结果的推理过程 Answer: XXX # 根据当前片段的中间结果 Confidence Score: XXX # 模型对当前片段的结果的置信度,范围为1到5之间}
LLMxMapReduce方法的流程图如下所示:整体分为Map、Collapse和Reduce三个阶段。
首先要将长文本切分成多个小片段,这些片段可以并行处理,从而提高效率。
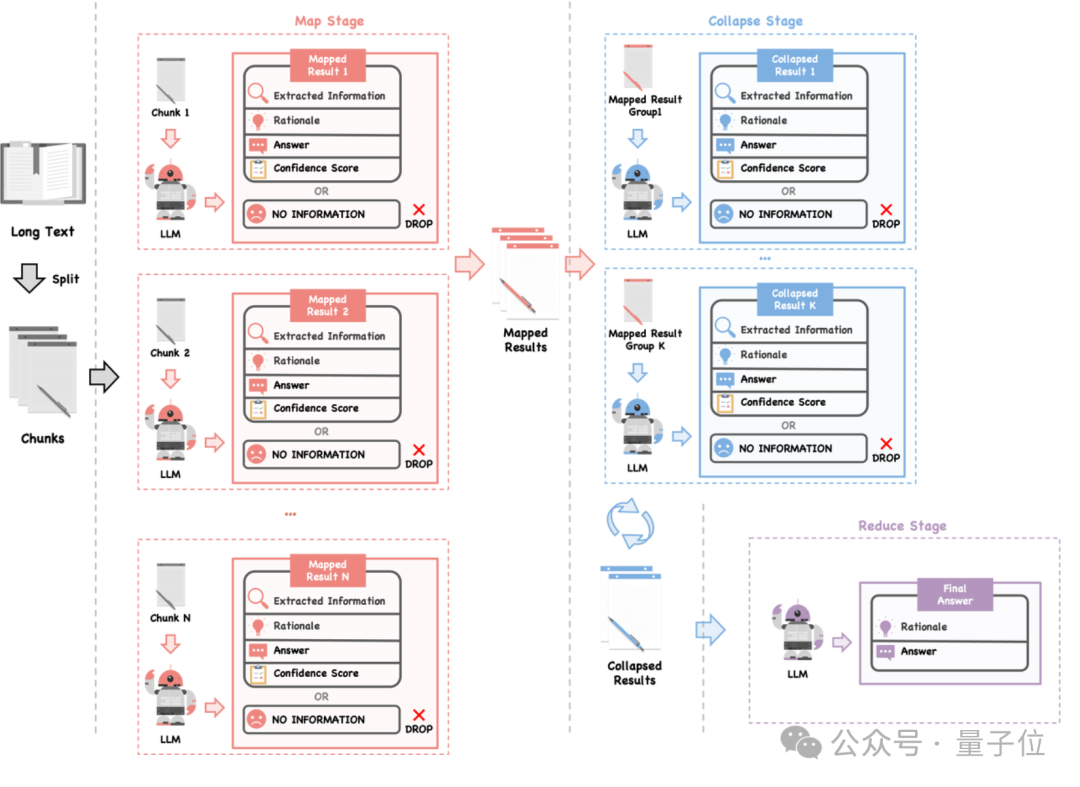
然后在Map阶段,使用大模型对每个片段进行分析,然后应用上文所述的结构化通信协议,将提取的信息整合成结构体形式,以便后续处理。
接下来,在Collapse阶段,如果所有片段的结果总长度超过模型的最大处理限制,模型将多个结构体压缩为一个结构体,以减少上下文长度。在处理冲突信息时,模型会考虑置信度进行整合。
最后,在Reduce阶段,模型根据压缩后的信息汇总出最终的答案。它会优先考虑置信度较高的结果,从而确保得到的答案准确无误。
通过以上工作流程,LLMxMapReduce能够更有效地处理长文本,避免因切分导致的信息丢失或错误结论,从而提高最终结果的准确性。
为了验证LLMxMapReduce技术的有效性,研究人员在业内权威的长文本评测InfiniteBench榜单上对不同模型进行了评测,InfiniteBench是一个综合性榜单,最长长度超过2000k token。
研究人员和很多方法进行了对比,其中对比的基线共有三类:
闭源模型:
包括GPT-4、Claude 2、Kimi-Chat,其中GPT-4和Claude 2的得分参照InfiniteBench原文,Kimi-Chat为重新测量的得分;
开源模型:
包括YaRN-Mistral、Yi-6B-200K、Yi-34B-200K和Qwen2-72B-Instruct,其中YaRN-Mistral、Yi-6B-200K、Yi-34B-200K的得分参照InfiniteBench原文,Qwen2-72B-Instruct是自行测量的得分;
其他基于分治的长文本处理框架:
包括LongAgent和Chain-of-Agents。这两个分治框架的不同点在于处理跨片段信息的方式不同。
LongAgent构建了一个Leader Agent来处理跨片段冲突。当不同的Chunk得出的答案不同时,Leader Agent会组织重新阅读冲突的片段,得出最终答案。
这种重复阅读的机制带来较大的时间开销,并且LongAgent的通信内容比较单一,Leader Agent处理冲突的能力有限。相比之下,LLMxMapReduce的结构化通信协议包含的信息更为丰富。
Chain-of-Agents通过顺序逐一读取各个Chunk来阅读全文。
由于没有显式地处理冲突信息,可能会导致后续Chunk的信息覆盖历史Chunk中的关键信息。相比之下,LLMxMapReduce利用校准后的置信度来更好的处理跨片段冲突。
具体实验结果如下:
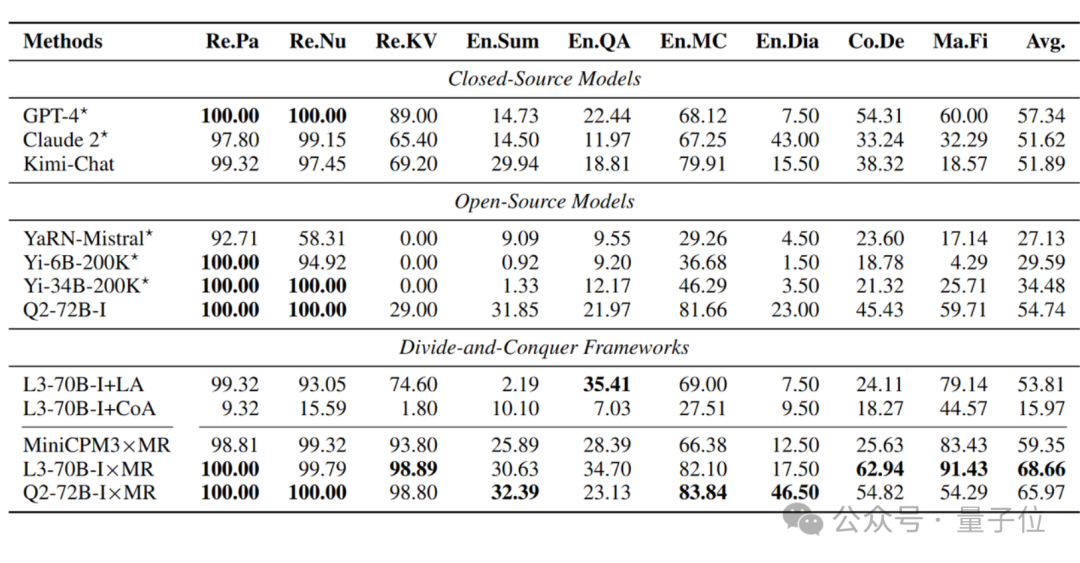
可以看到,结合 LLMxMapReduce 框架之后,Llama3-70B-Instruct x MapReduce 以 68.66 的最高平均分数,超越了闭源、开源模型以及其他基于 Llama3-70B-Instruct 的分治策略(即LongAgent和Chain-of-Agents)。
此外,LLMxMapReduce 框架展现出较强的通用性,结合 Qwen2-72B 和 MiniCPM3 也取得了优异的成绩。
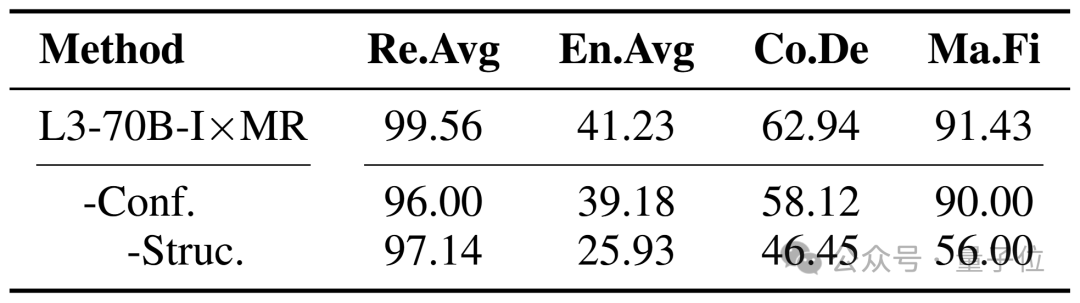
研究人员同样分析上下文置信度校准和结构化通信协议对框架性能的影响,在实验中逐步将这两个机制移除。实验结果显示,去除上下文置信度校准机制导致所有任务的性能下降。如果没有这两个机制,性能将会显著下降。这些结果证明了这两个机制在 LLMxMapReduce 框架中的关键作用。
大海捞针(Needle-in-a-haystack ) 是一个在大模型领域广泛应用的测试,用于评估大语言模型在处理长文本时识别特定事实的能力。为了评估LLMxMapReduce 框架在处理极长文本方面的表现,研究人员将大海捞针测试的文本长度扩展至1280K个token。
测试结果显示全绿:
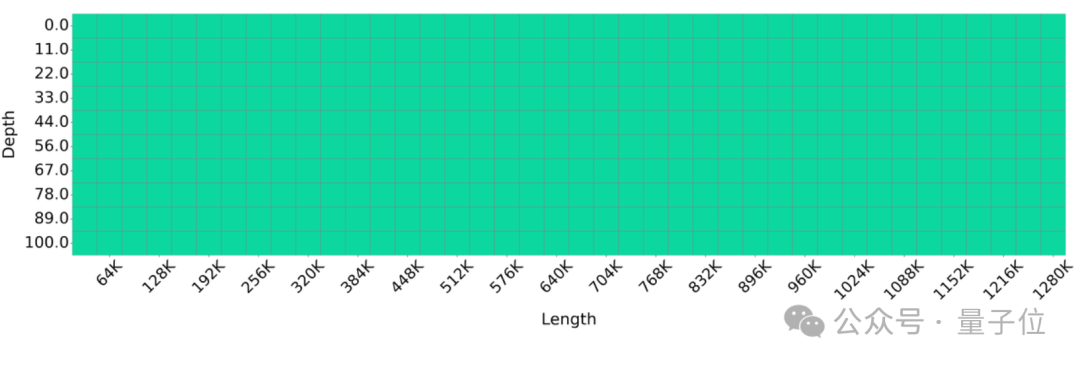
实验结果表明,采用 LLMxMapReduce 方法的 Llama3-70B-Instruct 能够有效处理长度达到 1280K token 的序列,展示了该框架在处理超长序列时的卓越能力。
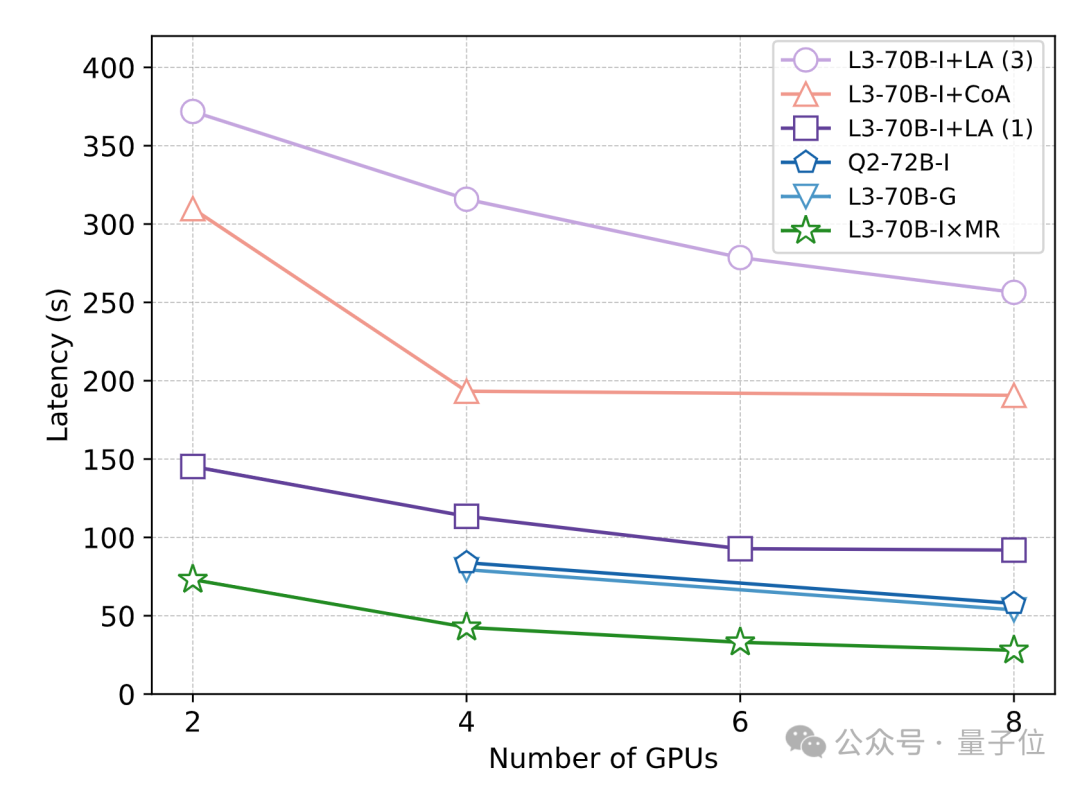
为了评估不同方法在处理长文本时的响应速度,研究人员进行了一项速度实验,使用 20 个测试示例,每个示例包含128K个token。实验结果显示,因为更好地利用了分段并行,LLMxMapReduce 的处理速度比 128K 模型标准解码更快。
而且,由于结构化通信协议和上下文置信度校准机制不影响框架的并行推理,相比于LongAgent 和 Chain-of-Agents 这两个同类型的分治框架,LLMxMapReduce 也具有明显的速度优势。
论文链接:https://arxiv.org/pdf/2410.09342
Github链接:https://github.com/thunlp/LLMxMapReduce
InfiniteBench:https://github.com/OpenBMB/InfiniteBench?tab=readme-ov-file
文章来自于微信公众号“量子位”,作者“LLMxMapReduce团队”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
