# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
数学为评估复杂推理提供了一个独特而合适的测试平台。它需要一定的创造力和精确的逻辑链条——通常涉及复杂的证明,这些证明必须缜密地筹划和执行。同时,数学还允许对结果进行客观验证。
在铺天盖地的宣传中,LLM看起来已经攻破了数学大关。但果真如此吗?
不久前,来自苹果的研究院团队证明,就算是在数学这些基础科学方面最先进的o1模型,其卓越的表现也是来源于对特定数据集针对性的持续优化。
所以为了更好的检验模型对于数学问题的理解与解决能力,我们需要一个更加全面而行之有效的数学测试基准。
近日,Epoch AI联合六十余位全世界的数学家,其中包括教授、IMO命题人、菲尔兹奖获得者,共同推出了全新的数学基准FrontierMath。其包括数百个原创的、格外具有挑战性的数学问题,旨在评估AI系统中的高级推理能力。
研究团队基于这个测试基准评估了六个前沿的模型,它们的成功率竟然都低于2%!

论文地址:https://arxiv.org/abs/2411.04872
论文特意致谢了陶哲轩为FrontierMath基准贡献了一些问题
具体来说,这些数学问题从奥赛难度到当今的数学前沿,包含了目前数学研究的所有主要分支——从数论和实数分析中的计算密集型问题到代数几何和群论中的抽象问题,而它们也通常需要数小时或数天的时间才能被专业数学家解决。
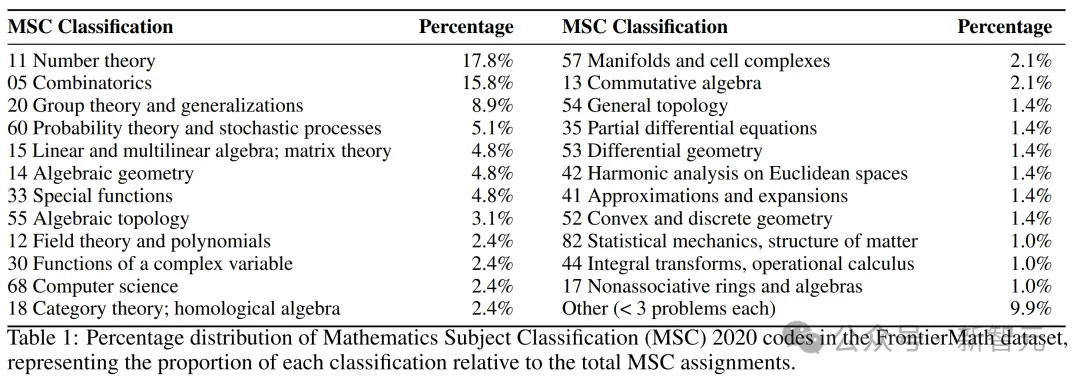
FrontierMath涉及的数学领域
这一测试集的发布一下炸出了不少AI大佬。

OpenAI研究员Clive Chan

德扑之父,OpenAI研究科学家Noam Brown
Anthropic联创Jack Clark
知名AI大牛Andrej Karpathy还发了一篇长帖「Moravec悖论在大语言模型评估中的体现」:

我对这个新的前沿数学基准测试感到惊讶,因为大语言模型在其中仅能解决2%的问题。引入这个基准测试的原因是大语言模型在现有数学基准测试中表现得越来越出色。有趣的问题在于,尽管从许多评估来看,大语言模型在数学和编程等领域已经逐渐接近顶级专家的水平,但你还是不会选择它们来完成对人类本身来讲最容易的工作。它们可以解决复杂的封闭问题,只要你在提示词中恰当地呈现问题描述,但它们在自主且连贯地解决长问题序列方面却很艰难,而这对人类来说是非常容易的。
这就是Moravec悖论的隐性体现,他在30多年前观察到,人类认为简单或困难的事情,对于计算机来说可能却恰恰相反。例如,人类对计算机下棋感到非常惊讶,但下棋对计算机来说却很简单,因为这是一个封闭的、确定性的系统,具有离散的动作空间、完全可观测性等等。反过来,人类可以系鞋带或折叠衬衫,并不觉得这有什么了不起,但这实际上是一个极其复杂的传感运动任务,对硬件和软件的最先进技术也还是一个挑战。这就像OpenAI前段时间发布的魔方项目,大多数人关注的是解魔方本身(这很简单),却不是让机器人用手去扭合一面魔方这种其实极其困难的任务。
所以我非常喜欢这个FrontierMath基准测试,我们应该多做一些这样的测试。但我也认为这是一个有趣的挑战,我们如何为所有那些「简单」但实际上很难的事情创建评估。非常长的上下文窗口、连贯性、自主性、常识、有效的多模态输入输出……我们如何构建好的「简单工作」评估?这些是你期望团队中任何入门级实习生都能完成的事情。
除了AI大佬们在纷纷讨论,网友们也炸了锅——
网友「Chubby」表达了自己的兴奋与期待!
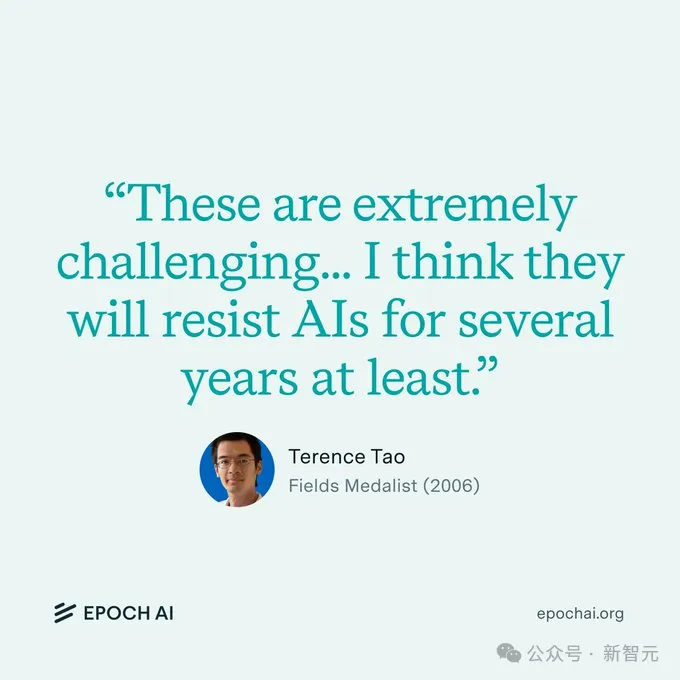
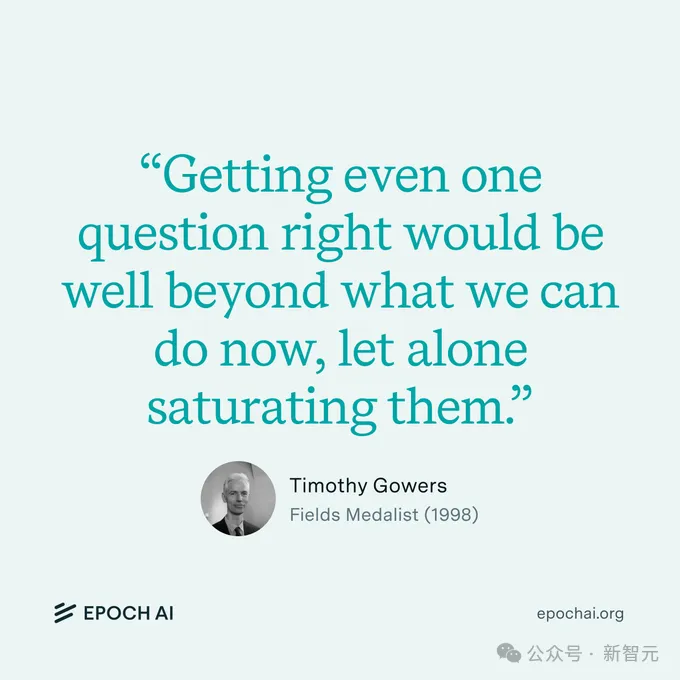
同时,Epoch AI也采访了菲尔兹奖得主陶哲轩(2006年)、蒂莫西·高尔斯(1998年)、理查德·博赫兹(1998年)以及国际数学奥赛教练陈谊廷。
他们一致认为,FrontierMath的研究问题极具挑战性,需要深厚的领域专长。

FrontierMath支持模型在评估中拥有充足的思考时间以及实验和迭代能力。并且还可以在Python 环境中交互式地编写和执行代码来测试假设、验证中间结果,并根据即时反馈改进方法。
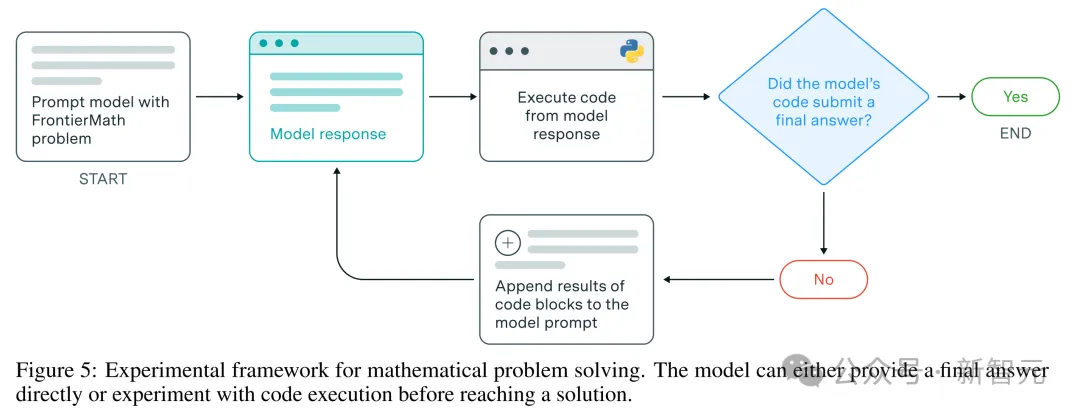
FrontierMath的模型评估流程框架
研究团队基于这个测试基准评估了六个前沿的模型,包括Claude 3.5 Sonnet、o1-preview和Gemini 1.5 Pro。
即便在延长思考时间(10000个token)、提供Python访问权限以及允许运行实验的条件下,它们的成功率仍然低于2%!
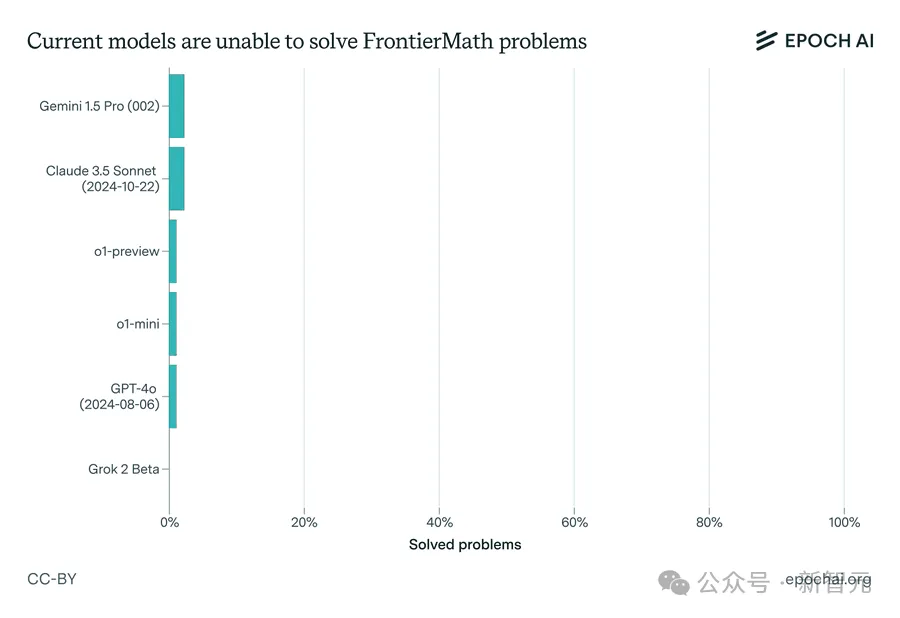
这与GSM-8K和MATH等其他流行的数学基准形成鲜明对比,在这些仅包含高中到本科数学难度的基准测试中,顶级模型现在的准确率都已经超过 90%。
当然,这在一定程度上是由于数据污染——训练数据中无意或有意地包含了测试数据的内容,或包含了与测试数据非常相似的数据。
这种现象会导致模型在测试时表现优异,但并非因为它真正学会了新知识或推理能力,而是因为它在训练中「见过」测试题或其相似题。
以至于模型的测试分数表现虚高,无法真实反映其在新数据上的表现能力。
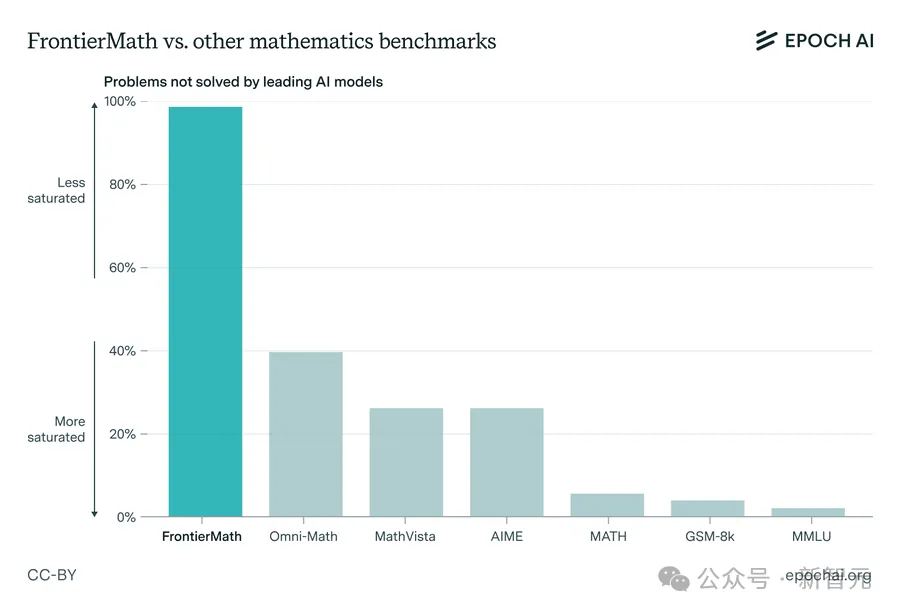
也就是说,原来的这些基准测试达到高分已经不值得吹嘘了,大模型又有了新的数学大关需要攻破!
对于这个新的数学大关,FrontierMath有三个关键设计原则:
1. 所有问题都是全新且未公开的,防止数据污染。
2. 模型的解答支持自动验证,从而实现高效评估。无论是精确的整数,还是如矩阵或符号表达式(在SymPy中),一个验证脚本可以通过将模型确认提交的答案与已知解决方案来精确匹配以对提交的答案进行检查验证。
3. 问题具有「防猜测」特性,问题的答案是大数值或复杂的数学对象,若没有数学推理,模型猜对的几率低于1%。
这些设计原则,每一条都非常具有针对性,弥补了现有基准测试的不足。
值得欣喜的是,模型在这个测试中几乎没办法「作弊」了,这将有效杜绝一些「名不副实」的现象。

由于FrontierMath中的问题是具有封闭形式答案(例如整数)的,所以它们可以让模型去自动进行验证与评估。
例如下图中的构造一个符合条件的19次多项式问题,问题给定的答案是非常大数值的整数,所以几乎不可能通过预测和精巧的模式匹配来解决这个问题。

模型必须有涉及数论、群论、代数几何这些方面的专业数学逻辑能力才可以得到正确的答案。
涉及到阿廷原始根猜想则更为复杂,模型需要求解计算的甚至是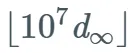 。
。

而数百道题目皆为如此,所以FrontierMath足以作为一个标杆性的数学基准,去检验AI模型是否具备了真正的复杂逻辑推理能力。
参考资料:
https://x.com/EpochAIResearch/status/1854996368814936250
https://x.com/karpathy/status/1855659091877937385
https://epochai.org/frontiermath/the-benchmark
https://epochai.org/frontiermath/benchmark-problems
文章来自于微信公众号“新智元”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
