
GPT-5被吐槽没进步?Epoch年终报告打脸:AI在飞速狂飙,ASI更近了!
GPT-5被吐槽没进步?Epoch年终报告打脸:AI在飞速狂飙,ASI更近了!Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。
来自主题: AI技术研报
8422 点击 2025-12-25 10:49
 搜索
搜索
Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。
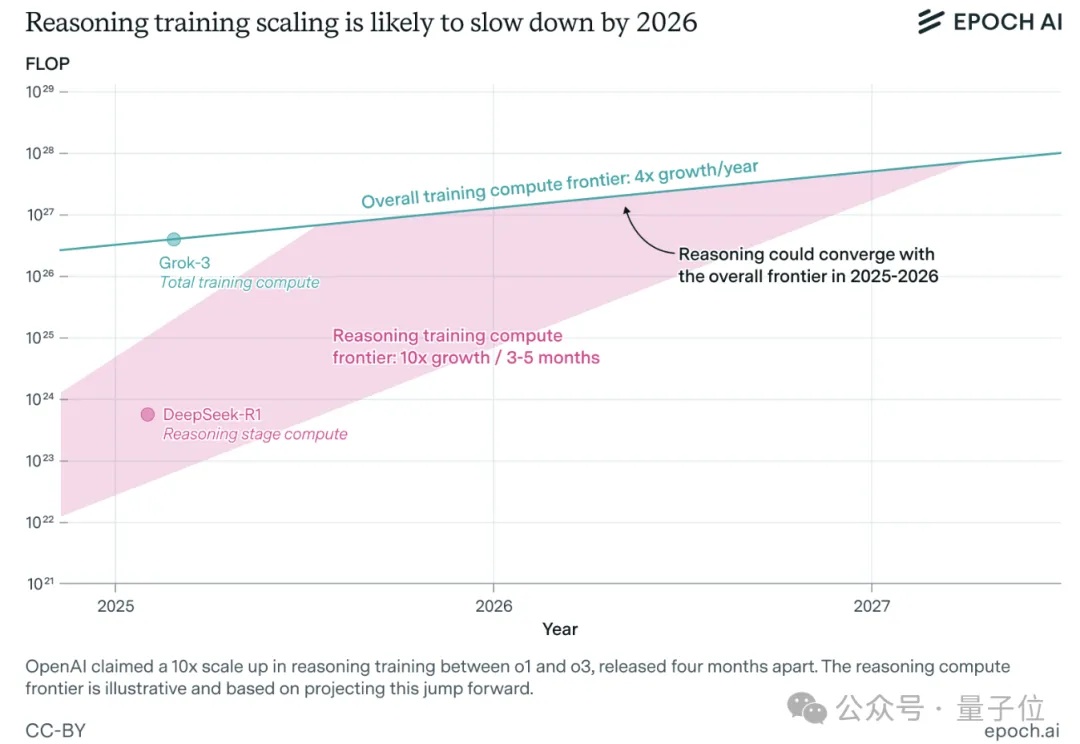
一年之内,大模型推理训练可能就会撞墙。
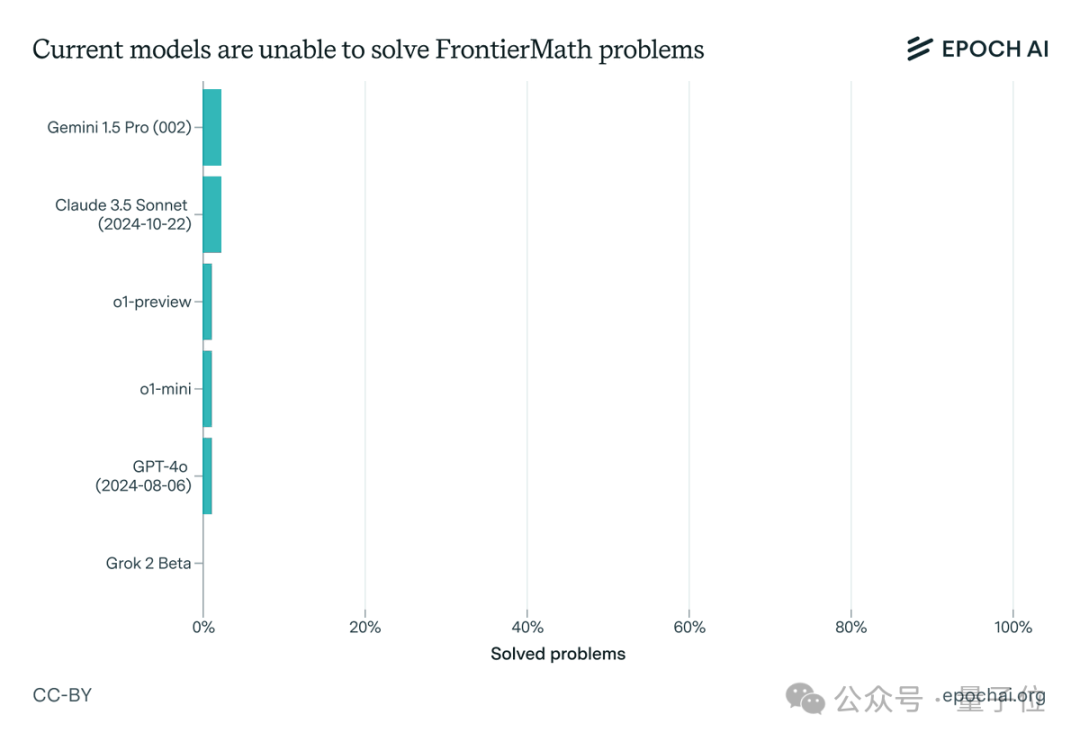
让大模型集体吃瘪,数学题正确率通通不到2%!

Epoch AI推出数学基准FrontierMath,目前前沿模型测试成功率均低于2%!OpenAI研究科学家Noam Brown说道:「我喜欢看到新评估的前沿模型通过率如此之低。这种感觉就像一觉醒来,外面是一片崭新的雪地,完全没有人迹。」或许,FrontierMath测试成功率突破的那一天,会是AI发展过程中一个全新的里程碑。
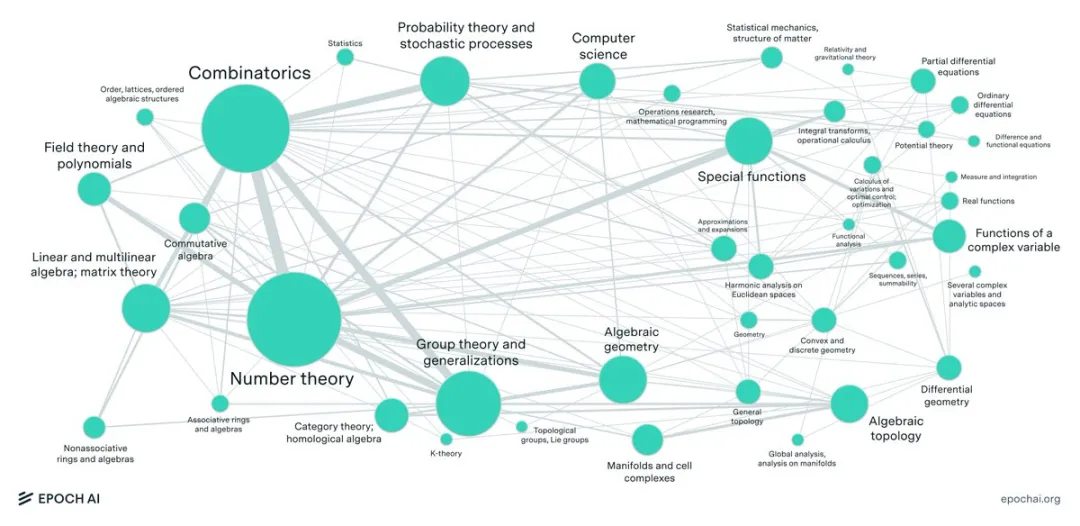
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!