# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!
FrontierMath是一个用于评估人工智能高级数学推理能力的基准测试。Epoch AI与60多位顶尖数学家合作,创建了数百道原创的、极具挑战性的数学问题,FrontierMath涵盖了现代数学的大多数主要分支——从数论中计算密集型问题到代数几何和范畴论中的抽象问题,目标是捕捉当代数学的概貌,即使是经验丰富的数学专家,也得绞尽脑汁,花费数小时甚至数天才能解出来
FrontierMath具有三个关键的设计原则:1)所有问题都是新的且未发表的,以防止数据污染;2)解决方案是自动可验证的,从而实现高效的评估;3)问题是“防猜测”的,在没有正确推理的情况下解决的可能性很低
评估了六个领先的模型,包括o1 ,Claude 3.5 Sonnet、GPT-4o,Grok和Gemini 1.5 Pro。即使有延长的思考时间(10,000个token)、Python访问权限以及运行实验的能力,成功率仍然低于2%——相比之下,在传统基准测试中,成功率超过90%
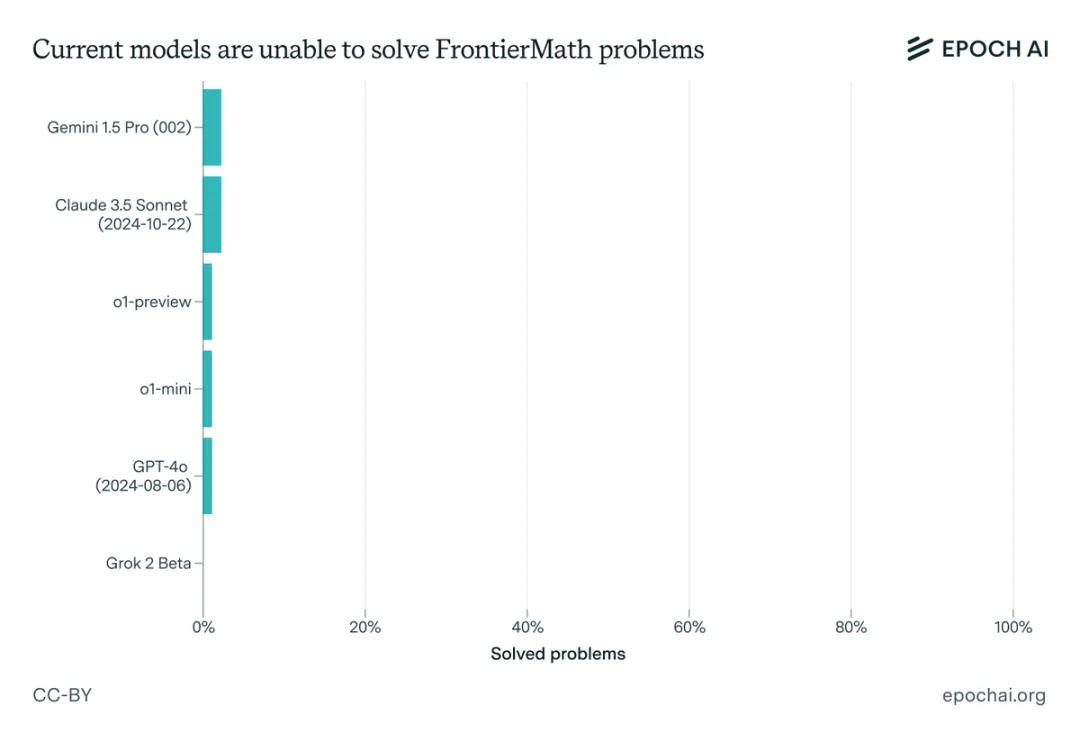
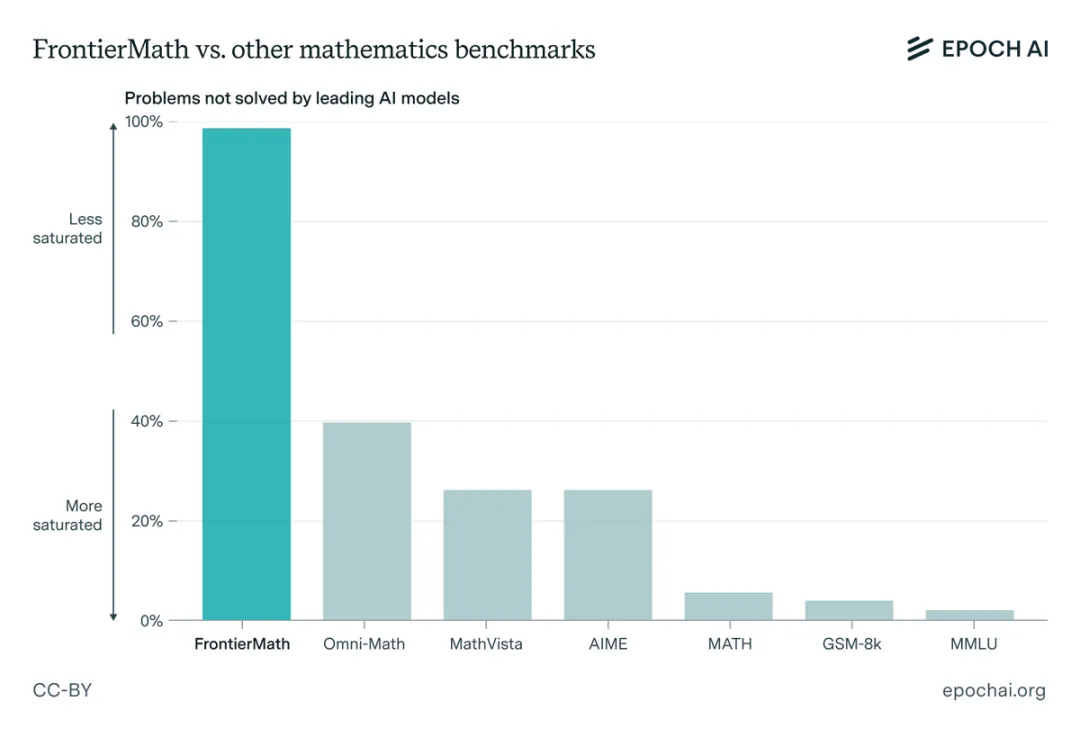
Epoch AI指出,现有的数学benchmark,例如GSM8K和MATH,早就被LLM们刷烂了,高分的原因很大程度上是因为数据污染——说白了,就是LLM通过记忆大量的“考古题”来提高分数,真正考试的时候,当然容易!而FrontierMath则完全不同,所有题目都是全新的、未公开的,LLM想作弊都没门!这下LLM们,自然就暴露了它们的真实水平
为了进一步验证FrontierMath的难度,Epoch AI还特意采访了多位菲尔兹奖(数学界的最高荣誉)得主,包括陶哲轩 (2006)、蒂莫西·高尔斯 (1998)、理查德·博赫兹 (1998),以及国际数学奥林匹克竞赛 (IMO) 教练陈谊廷 (Evan Chen)。这些大佬们一致认为,FrontierMath的题目非常具有挑战性,需要深厚的专业知识和强大的推理能力才能解决

Andrej Karpathy对这个新的前沿数学基准测试(LLM仅解决了2%)的反应:
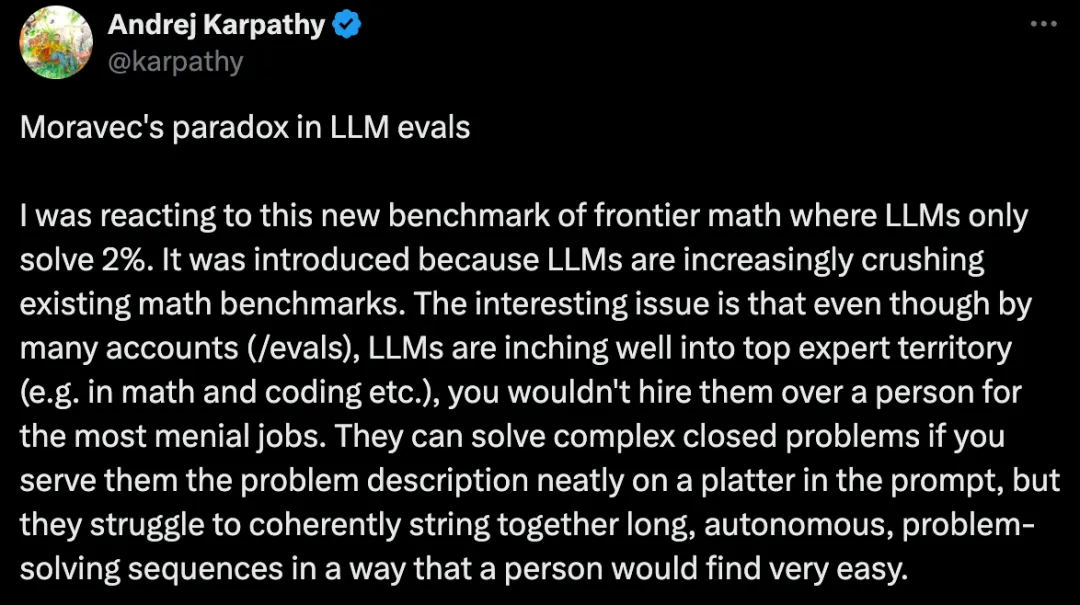
之所以引入这个基准,是因为大模型越来越多地碾压现有的数学基准。有趣的问题是,尽管从许多方面(/evals)来看,大模型正逐步跻身顶级专家行列(如数学和编码等),但你不会雇用他们而不是让他们从事最琐碎的工作。如果你把问题描述整齐地放在盘子里,他们就能解决复杂的封闭式问题,但他们很难连贯地把长长的、自主的、解决问题的序列串联起来,而人却会觉得非常容易
这是莫拉维克悖论的变相,他在 30 多年前就观察到,对人类来说容易/困难的事情,与对计算机来说容易/困难的事情,在非直觉上可能大相径庭。例如,人类对计算机下国际象棋印象深刻,但国际象棋对计算机来说却很容易,因为它是一个封闭的、确定性的系统,具有离散的行动空间、完全的可观测性等等。反之亦然,人类可以系好鞋带或叠好衬衫,而且根本不需要考虑太多,但这是一项极其复杂的传感运动任务,对硬件和软件的技术水平都是挑战。这就像不久前 OpenAI 发布的魔方一样,大多数人都把注意力集中在解魔方本身(这是微不足道的),而不是用机器人的手转动魔方的一个面这一实际难度极高的任务
因此,我非常喜欢这个 FrontierMath 基准,我们应该制作更多的基准。但我也认为,如何为所有 "容易 "但其实很难的东西创建评估是一个有趣的挑战。很长的语境窗口、连贯性、自主性、常识、有效的多模态输入/输出...... 我们如何建立良好的 "初级工作 "评估?你对团队中任何初级实习生的期望
不管怎么说,数学为评估复杂推理提供了一个独特的理想环境。它需要创造力和 extended chains of precise logic——通常涉及复杂的证明——这些证明必须经过精心计划和执行,但允许对结果进行客观验证
衡量人工智能在创造性问题解决和在多个步骤中保持精确推理方面的能力,可能有助于深入了解在系统性、创新性思维(科学研究所需)方面的进展
探索FrontierMath:

https://epochai.org/frontiermath发布了带有详细解答、专家评论和研究论文的示例问题
文章来自于微信公众号“AI寒武纪”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
