# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文作者张杰是苏黎世联邦理工大学的二年级的博士生,导师是 Florian Tramèr。本文发表在 CCS 2024 上, 第一单位是 ETH Zurich,主要探讨如何严格的衡量某个机器学习算法的隐私保护能力。

1. 前言
机器学习模型往往容易受到隐私攻击。如果你的个人数据被用于训练模型,你可能希望得到一种保障,确保攻击者无法泄露你的数据。更进一步,你或许希望确保没有人能够判断你的数据是否曾被使用过,这就是成员推理攻击(membership inference attack, MIA)所关注的问题。
差分隐私(Differential Privacy, DP)确实可以提供这种理论上可证明的保护。然而,这种强有力的保障往往以牺牲模型的性能为代价,原因可能在于现有的隐私分析方法(如 DP-SGD)在实际应用中显得过于保守。因此,许多非理论保证的防御手段(empirical defenses)应运而生,这些方法通常承诺在实际应用中实现更好的隐私与实用性之间的平衡。然而,由于这些方法并没有提供严格的理论保证,我们需要通过严谨的评估方式来验证它们的可信度。
遗憾的是,我们发现,许多 empirical defenses 在衡量隐私泄露的时候存在一些常见的误区:
1.关注的是群体层面的平均隐私,但对最「脆弱」数据的隐私却关注甚少。但 privacy 并不应该是一个平均的指标!
2.使用很弱的、 非自适应的攻击。没有针对具体防御,做适应性攻击。
3.与模型性能过差的 DP 差分隐私方法进行相比,这种比较方式不够公平,容易误导人们对模型隐私保护效果的判断。
为了解决这些问题,我们提出了一种严格的衡量方法,可以准确评估某个机器学习算法的隐私泄露程度。我们建议应该与差分隐私(Differential Privacy)方法进行公平对比,并进行适应性攻击,最后汇报「脆弱」数据上的隐私泄露。
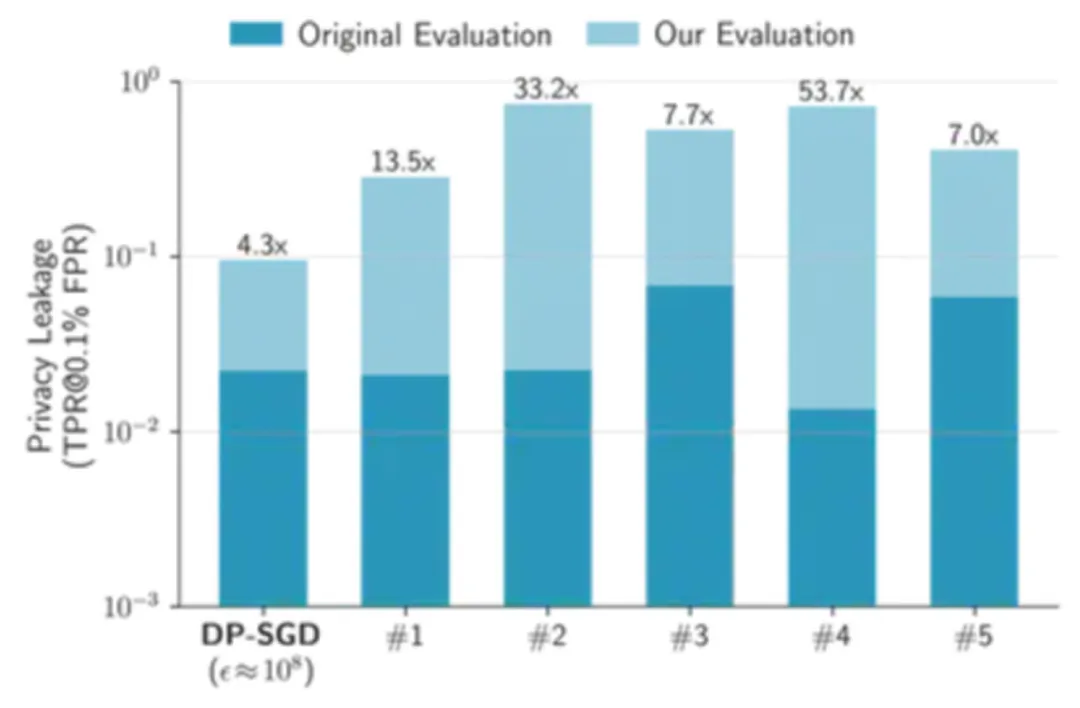
我们应用此方法研究了五种 empirical defenses。这些防御方法各不相同,包括蒸馏、合成数据、损失扰动以及自监督训练等。然而,我们的研究发现,这些防御所导致的隐私泄露程度远超其原始评估所显示的水平。
事实上,所有这些防御方法都未能超越经过适当调整的最基本的差分隐私方法 ——DP-SGD。例如,当我们将 CIFAR-10 数据集上的所有防御措施(包括 DP-SGD)调整至至少达到 88% 的测试准确率,同时尽量保证隐私时,现有评估可能严重低估隐私泄露的程度,误差高达五十倍之多!
2. 隐私评估为何应关注个体隐私泄露程度
而非群体的平均情况?
虽然整体平均隐私泄露看似可接受,但个别用户的隐私可能面临严重威胁。在机器学习中,隐私保护措施需要确保即便整体隐私保护水平达标,仍能为每位个体提供足够的隐私保障。以 CIFAR-10 数据集为例,每个样本的隐私泄露程度如下:
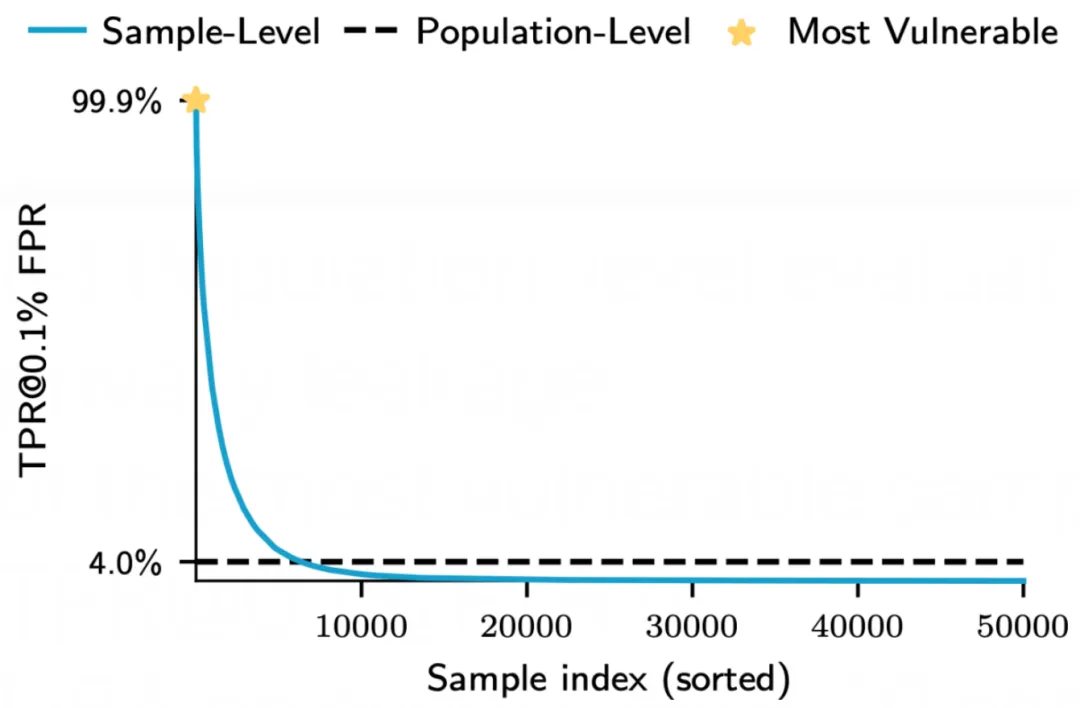
通过分析,我们可以发现,少数样本的隐私泄露程度几乎达到了 100%。然而,如果仅关注群体的平均隐私泄露,这一数值仅为 4%,这容易导致对该方法隐私保护能力的误解。实际上,这种看似低的平均值掩盖了部分个体的严重隐私风险,使得整体评估显得不够准确。因此,在隐私保护的研究与实践中,关注个体隐私泄露的情况显得尤为重要。
3. 使用金丝雀(canary)进行高效的样本级隐私评估
因此,我们的论文认为,严格的隐私评估应该能够衡量攻击者是否可靠地猜测数据集中最脆弱样本的隐私。具体来说,就是在低假阳性率(FPR)下实现高真实阳性率(TPR)。
然而,这种样本级评估的成本显著高于现有的群体级评估。估计攻击的真实阳性率(TPR)和假阳性率(FPR)通常采用蒙特卡罗抽样的方法:通过模拟多个独立的训练过程,每次随机重新采样训练数据,并计算每个模型结果中攻击者成功的次数。
不过,要在 FPR 为 0.1% 时估计个体级别的 TPR,我们可能需要对每个样本进行数千次训练,才能排序并找出最容易受到攻击的样本及其隐私泄露程度。这种开销显然是相当庞大的 (例如上图 CIFAR-10,我们训练了 20000 个模型才能精准描绘每个样本的隐私泄露)。
为此,我们提出了一种有效的近似方法:针对一小部分金丝雀(canary)样本进行攻击评估。直观来看,金丝雀样本应能够代表在特定防御策略和数据集下最容易受到攻击的样本。因此,我们只需在有限的金丝雀样本上进行隐私评估。这种方法不仅降低了评估的成本,同时也确保了隐私评估的准确性和有效性。
在我们的论文中,我们详细说明了如何针对五种具体的防御方法设计相应的金丝雀样本。至关重要的是,金丝雀的选择必须依据防御策略和数据集的特性进行调整。某些样本可能对特定防御方法来说是有效的金丝雀,但对其他防御方法却并不适用。作为一般准则,异常数据,例如被错误标记的样本或与训练数据分布不一致的样本(即 OOD 数据),通常是一个良好的起点,因为这些样本往往最容易受到攻击。
例如,下面是来自 CIFAR-10 数据集的一些高度脆弱的样本,这些样本用于简单的(未防御的)ResNet 模型。其中一些样本被错误标记(例如,人类的图片被标记为「卡车」),而另一些样本则是不太「正常」的情况(例如,陆地上的一艘船或一架粉色的飞机)。

4. DP-SGD 仍是一种强大的 empirical defense
我们采用高效的样本级评估(结合适应性攻击)来测试是否存在经验上优于差分隐私(DP)方法的 empirical defense。许多 empirical defense 声称能够在现实环境中实现合理的隐私保护,同时提供比 DP-SGD 等具有强大可证明保证的方法更好的实用性。
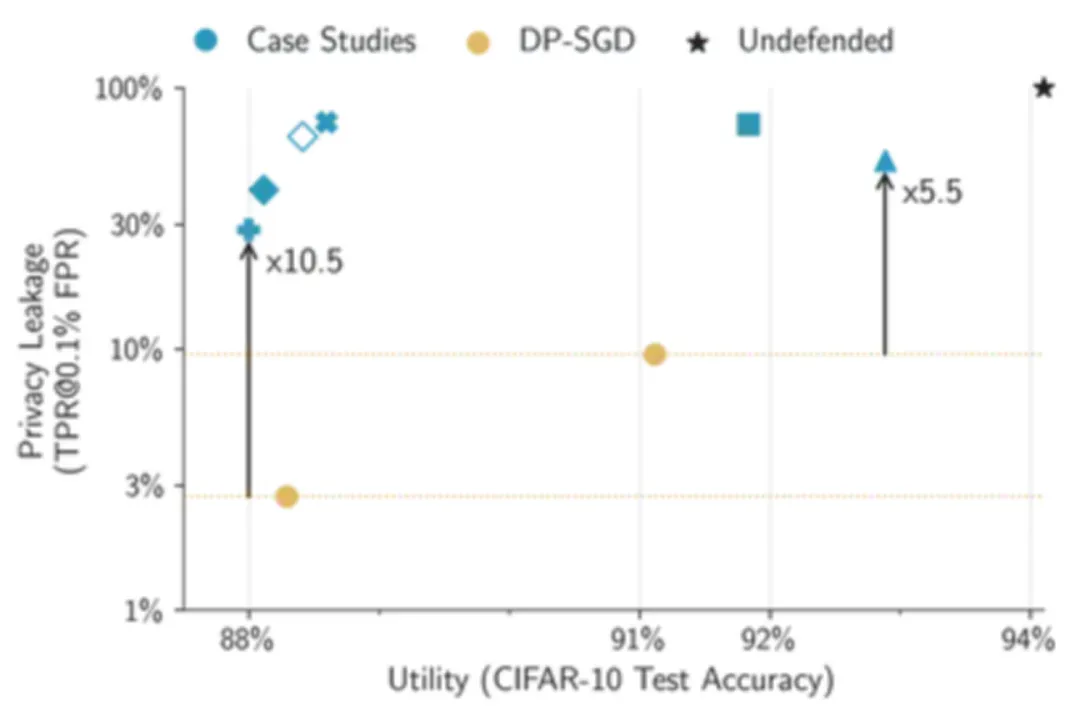
然而,DP-SGD 的 privacy-utilty 是可调节的。如果 empirical defense 无论如何都会放弃可证明的保证,那么我们为何不对 DP-SGD 采取同样的策略呢?因此,我们对 DP-SGD 进行了调整,以达到较高的 CIFAR-10 测试准确率(比如从 88% 提升到 91%),即将 empirical defense 和 DP-SGD 方法的性能调整到相似水平,再进行公平的隐私泄露比较。
令人惊讶的是,我们在案例研究中发现,简单调整后的 DP-SGD 性能优于所有其他 empirical defenses。具体来说,在 CIFAR-10 数据集上,我们的方法达到了与所有其他 empirical defense 相当的测试准确率,但却为最易受到攻击的样本提供了更强大的经验隐私保护。因此,DP-SGD 不仅仅是理论上有保证的防御手段,同时也可以成为一种强有力的 empirical defense。
5. 结论
我们论文的主要结论是,隐私评估的具体方式至关重要!Empirical 隐私攻击和防御的文献考虑了多种指标,但往往未能准确描述这些指标的隐私语义(即某个指标捕获了哪种隐私)。
在论文中,我们提倡在个体样本层面上进行隐私评估,报告防御方法对数据分布中最脆弱样本的隐私泄露程度。为了高效地进行这样的评估,我们明确设计了一小部分审计子群体,这些样本具有最坏情况的特征,称为金丝雀样本。
在我们的评估中,我们发现 DP-SGD 是一种难以超越的防御方法 —— 即使在当前分析技术无法提供任何有意义保证的情况下!一个根本性的问题是,可证明隐私与 empirical 隐私之间的差距究竟是由于隐私分析不充分,还是由于 empirical 攻击手段的不足。换句话说,我们的 empirical DP-SGD 方法在 CIFAR-10 等自然数据集上是否真的具备隐私保护(我们只是尚未找到证明的方法),还是说还有更强大的潜在攻击(我们尚未发现)?
文章来自于微信公众号 “ 机器之心 ”



