# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从文字生成三维世界的场景有多难?
试想一下,如果我们要 “生成复活节岛的摩艾石像”,AI 怎么才能理解我们的需求,然后生成一个精美的三维场景?
斯坦福的研究团队提出了一个创新性解决方案:就像人类使用自然语言(natural language)进行交流,三维场景的构建需要场景语言(Scene Language)。

这个新语言不仅能让 AI 理解我们的需求,更让它能够细致地将人类的描述转化为三维世界的场景。同时,它还具备编辑功能,一句简单指令就能改变场景中的元素!物体的位置、风格,现在都可以随意调整。

再比如,输入 “初始状态的国际象棋盘”,模型可以自动识别并生成如下特征:
最终生成的 3D 场景完美还原了这些细节。

这个方法支持多种渲染方式,能适应不同的应用场景:
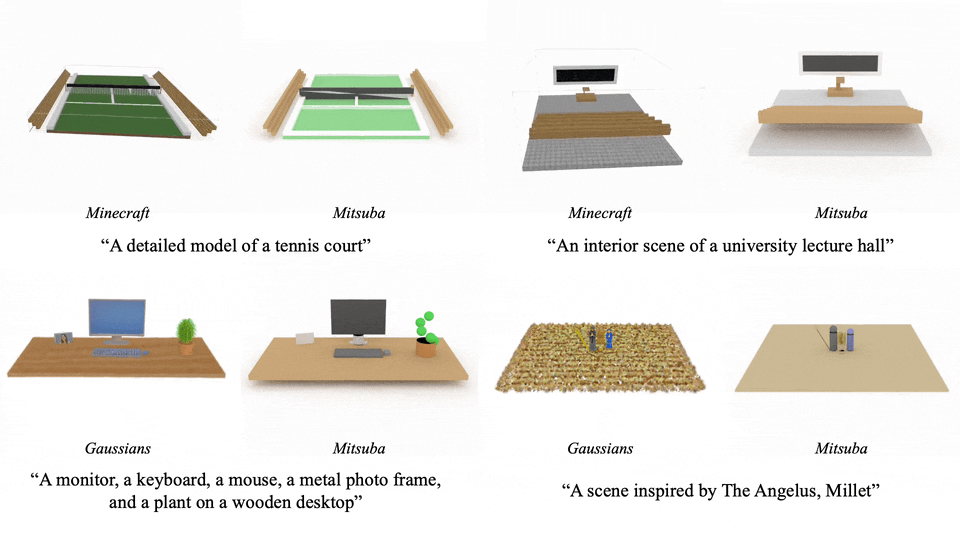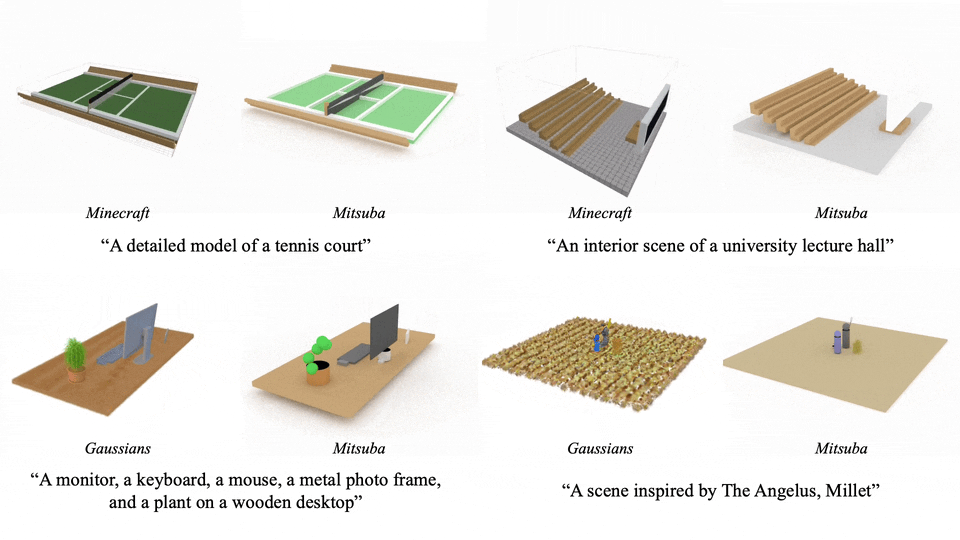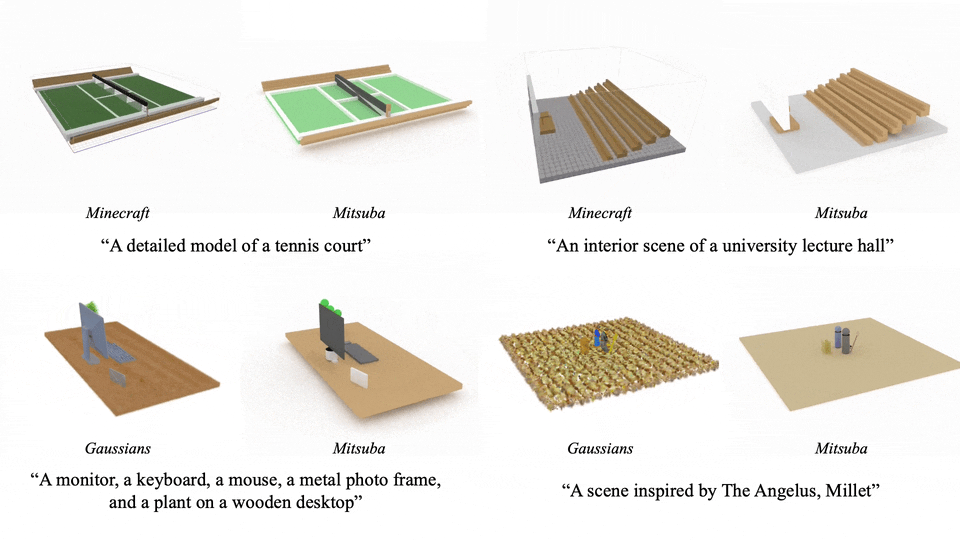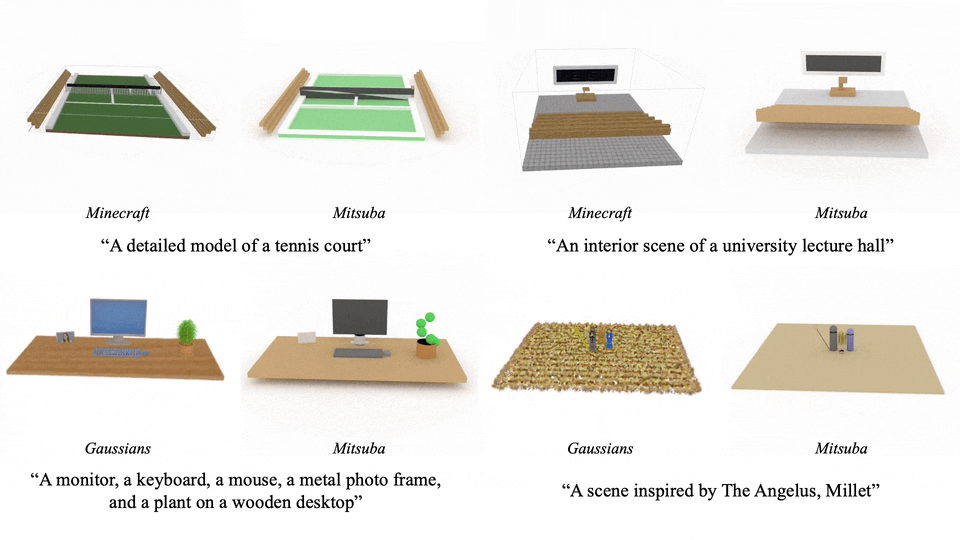
更具吸引力的是其编辑能力:只需一句指令,就能调整场景中的元素:


动态生成
不仅限于静态,Scene Language 还能生成动态场景,让 3D 世界生动起来。
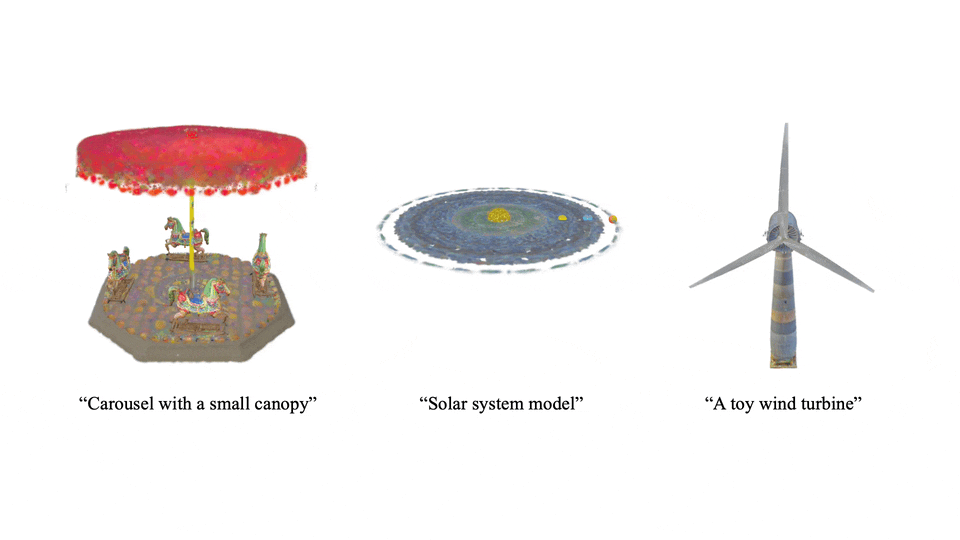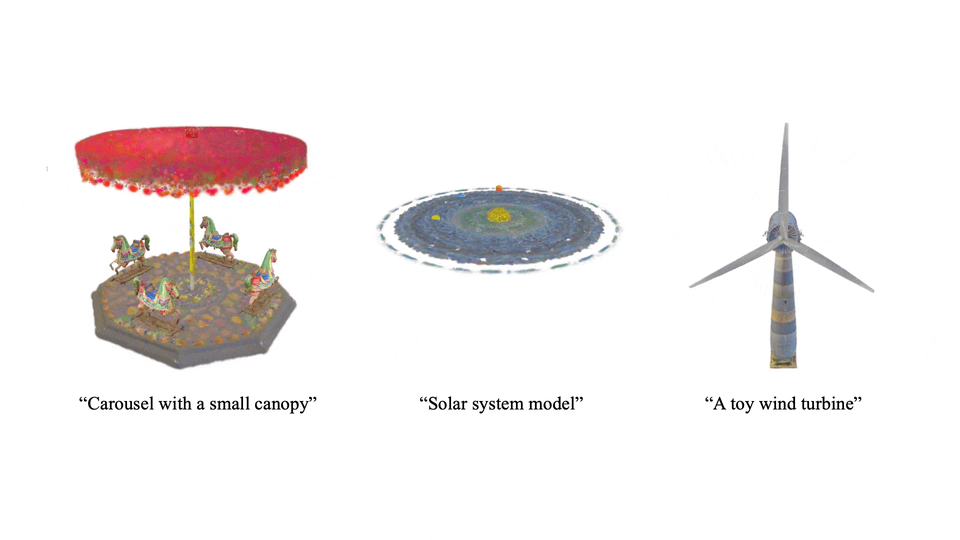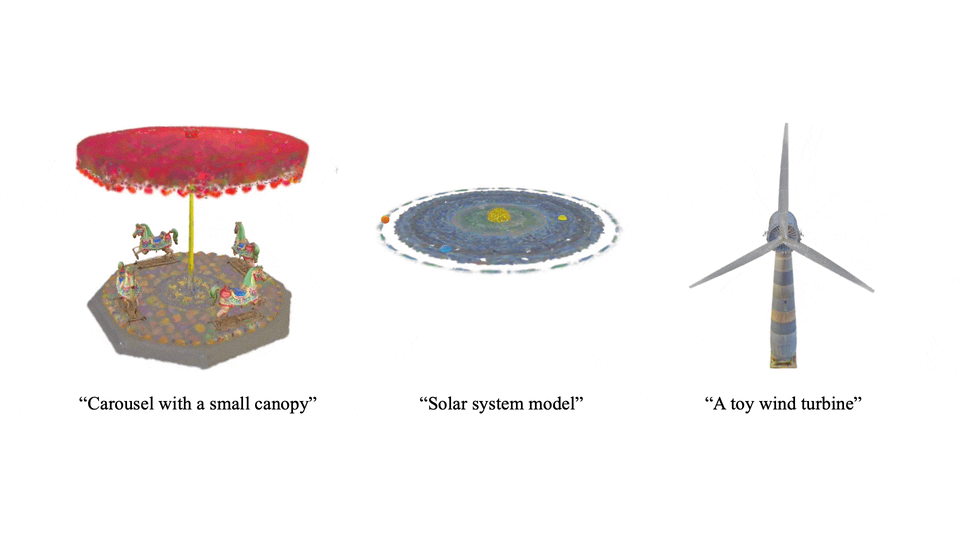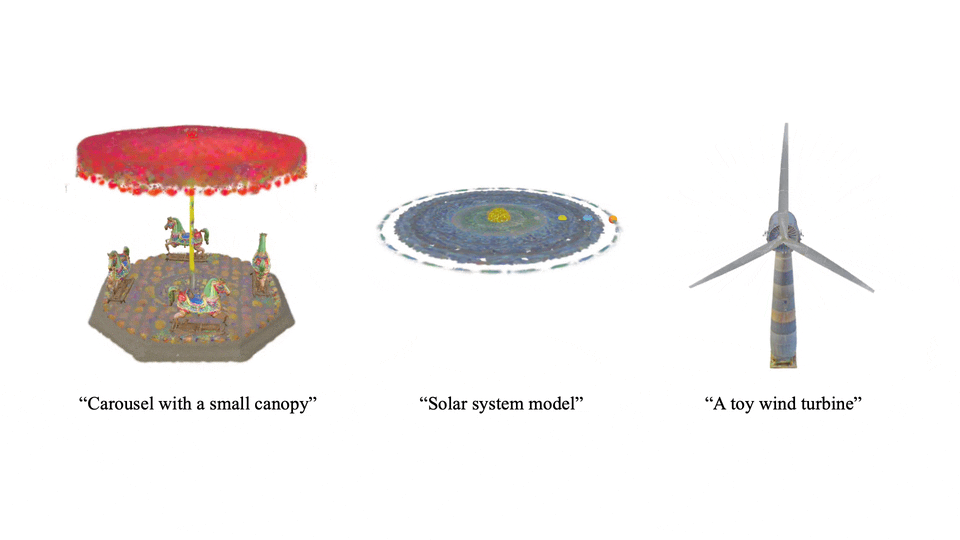
技术亮点

Scene Language 的核心在于三大组件的融合:
1. 程序语言(program):用于精确描述场景结构,包括物体间的重复、层次关系;
2. 自然语言(word):定义场景中的物体类别,提供语义层面的信息;
3. 神经网络表征(embedding):捕捉物体的内在视觉细节。
这种组合就像给 AI 配备了一套完整的 “建筑工具”,既能整体规划,又能雕琢细节。
对比传统方法的优势
与现有技术相比,Scene Language 展现出显著优势:
这一研究展示了 AI 理解和创造 3D 世界的全新可能性,期待它在游戏开发、建筑设计等领域引领新一轮的创新!
作者简介
该篇论文主要作者来自斯坦福大学吴佳俊团队。
论文一作张蕴之,斯坦福大学博士生。主要研究为视觉表征及生成。

吴佳俊,现任斯坦福大学助理教授。在麻省理工学院完成博士学位,本科毕业于清华大学姚班。
文章来自于“机器之心”,作者“张蕴之、吴佳俊”。




