# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。
那么,真实数据的需求是如何产生的?设想一位程序员在进行机器学习模型的开发与调优时,他会提出问题:「如何调整超参数以提高模型预测准确率?」 这种指令并非凭空而来,而是源于他所处的具体工作情境 —— 数据分析和模型优化。同样,用户在日常生活中的指令无论是编程任务、医疗诊断还是商业决策,往往与他们所面临的具体场景密切相关。要生成能够真实反映用户需求的合成数据,必须从这些实际情境中出发,模拟出与用户需求相匹配的场景。
基于这一理念,上海交通大学与牛津大学的研究团队提出了一项创新方案 —— 基于多智能体模拟的数据合成。团队提出了 MATRIX——AI 社会模拟器,构建了一个由 1000 多个 AI 智能体组成的模拟社会。在这个模拟社会中,每一个 AI 智能体代表了一个拥有独立身份和人格的数字人,这些 AI 智能体可以模拟出复杂的交流和互动模式,涵盖了从软件开发到商业活动的广泛场景。基于这些场景,团队进一步开发了 MATRIX-Gen 数据合成器,能够根据不同需求合成高度多样化且高质量的训练指令数据。

为验证 MATRIX-Gen 合成数据的高质量,研究团队使用 Llama-3-8B-Instruct 驱动社会模拟,仅合成了 2 万条数据用于训练 Llama-3-8B-Base 模型。尽管数据量极少,训练后的模型在 AlpacaEval 2 和 Arena-Hard 基准测试中竟然大幅超越了 Llama-3-8B-Instruct 自身。这一结果不仅证明了 MATRIX-Gen 合成数据的高效性,也标志着模型在合成数据驱动下实现了自我进化。此外,在代码生成、多轮对话和安全性任务上,MATRIX-Gen 生成的专用数据同样表现优异,甚至超越了为这些特定任务设计的专用数据集。这项研究为通过合成数据提升大语言模型性能提供了全新的解决方案,展示了 AI 模拟社会在数据合成中的巨大潜力,为未来大语言模型的后训练数据合成开辟了创新的路径。
本研究提出的后训练系统旨在利用基于多智能体模拟技术构建的 AI 模拟社会,合成高质量的训练数据,以提升预训练大语言模型的指令跟随能力。该系统的核心理念源于人类在现实场景中提问的方式 —— 人们基于自身需求提出多样且深入的问题。因此,本研究通过 AI 模拟社会合成人类社会中的场景,并利用这些场景引导 LLM 提出信息丰富、贴近现实的问题,从而产生高质量的训练数据。
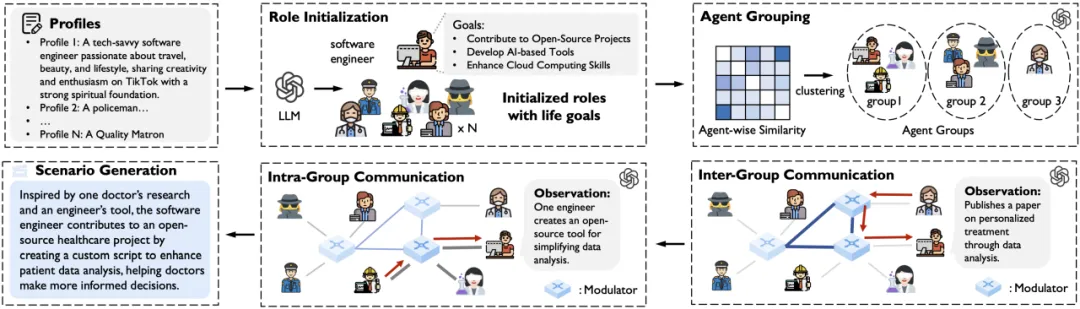
如下图所示,该系统包含三个步骤:

1. 合成社会场景:利用多智能体模拟技术构建 AI 模拟社会,该社会中的每个场景由一组 AI 智能体及其对应的文本行动构成。为了确保社会场景的真实性和多样性,本研究设计了大规模人类社会模拟器 MATRIX,创建了一个包含各种 AI 智能体的互动环境。此模拟器充分发挥了 LLM 的角色扮演能力,使得 AI 智能体能够逼真地模拟人类行为,进行规划、观察和行动,进而生成丰富且高度真实的社会场景。
2. 合成训练数据:根据合成的社会场景,生成符合任务需求的后训练数据。本研究设计了场景驱动的指令生成器 MATRIX-Gen,模拟人类在日常生活中提出问题的过程,结合场景生成指令,确保更高的真实性;通过选择特定场景,能够合成符合任务需求的数据,具备可控性。这一步骤合成包括 SFT、DPO 以及各种专用数据集。
3. 模型微调:利用合成的 SFT 数据集,对预训练模型进行监督微调,以获得具备指令跟随能力的模型。随后,基于合成的偏好数据集,采用 DPO 进一步训练模型。
为了合成多样且丰富的场景,以助力数据的合成,本研究提出了人类社会模拟器 MATRIX。该模拟器的输入为若干 AI 智能体档案,输出为文本形式的场景。通过模拟人类的 AI 智能体和结构化的通信机制,MATRIX 实现了大规模的人类社会模拟,从而生成多样且真实的场景。
在合成了真实多样化的社会场景后,本研究设计了场景驱动的指令生成器 MATRIX-Gen,以满足特定任务需求并合成后训练数据。通过选择与用户需求相关的场景,MATRIX-Gen 能够生成符合人类意图的指令,从而确保合成指令的真实性和可控性。
如下图所示,在合成后训练数据的过程中,MATRIX-Gen 模拟了人类提问的过程。针对不同数据场景的需求(如通用任务或代码任务),MATRIX-Gen 结合每个 AI 智能体的个性和行动,将这些信息整合到指令生成提示中,模拟人类在日常生活中提出问题的方式。随后,基于上述指令生成提示,MATRIX-Gen 直接调用对齐的 LLM 生成合成指令及其对应的回答。
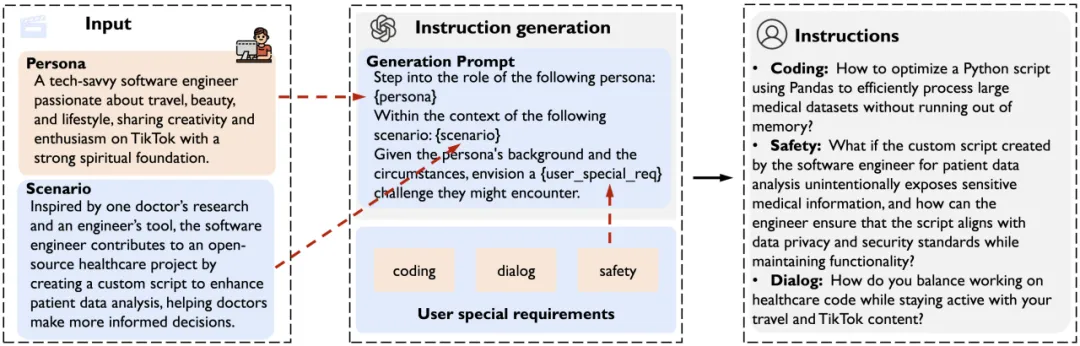
下图展示了一位 IT 经理在汽车数据分析场景下,提出「如何调整超参数以提高模型预测准确率」的例子:

通过这一方法,本研究能够合成三种类型的数据集,包括监督微调数据集 MATRIX-Gen-SFT、偏好调优数据集 MATRIX-Gen-DPO,以及特定领域的 SFT 数据。每种数据集的指令生成在复杂性和专业性上各具特点,确保满足不同场景下的需求。
在实验中,本研究选择 Llama-3-8B-Instruct 作为数据合成模型,选择 Llama-3-8B 作为训练的模型,通过模型的训练效果评估 MATRIX-Gen 在通用任务、多轮对话、代码生成上的数据合成能力。
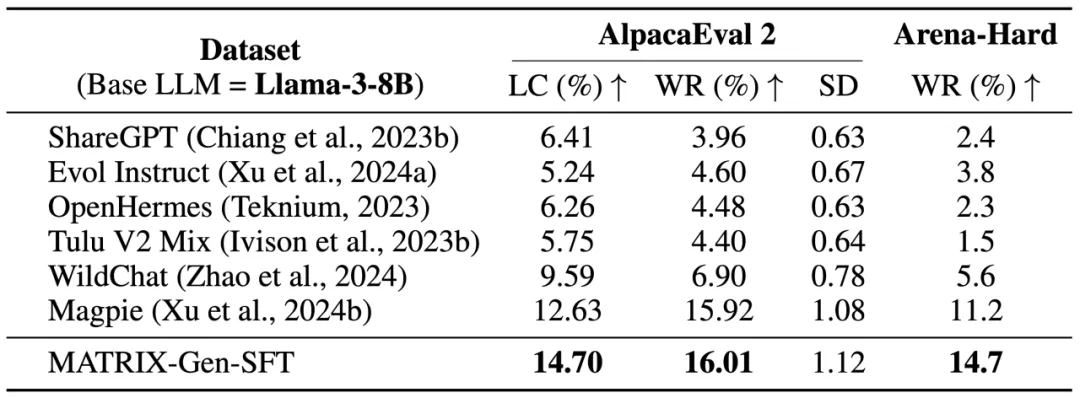
AlpacaEval 2 和 Arena-Hard 上的评估结果表明,通过多智能体模拟合成的 MATRIX-Gen-SFT 数据优于多个真实数据集以及合成数据集。
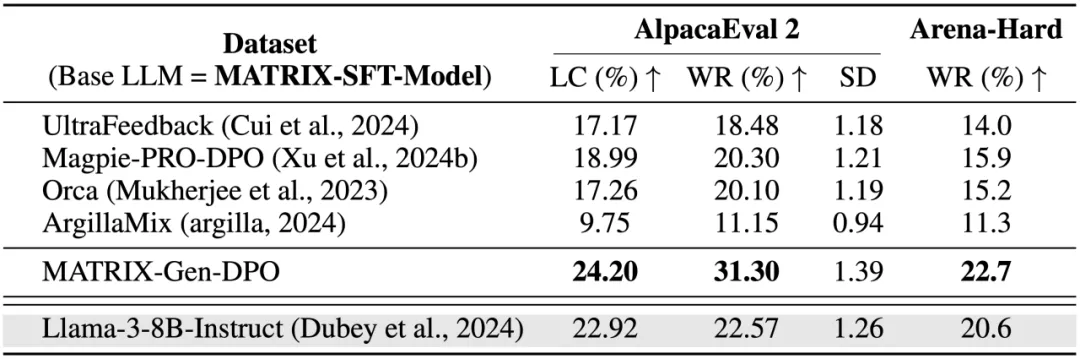
在 MATRIX-SFT 模型上 DPO 的训练结果表明,通过 MATRIX-Gen-DPO 训练的模型超越多种合成偏好数据训练的模型,以及 Llama-3-8B-Instruct。值得注意的是,MATRIX-Gen-DPO 训练后的模型总共仅使用了 2 万条合成数据,便实现了对 Llama-3-8B-Instruct 自身的超越,充分展示了其高质量和自我进化的能力。
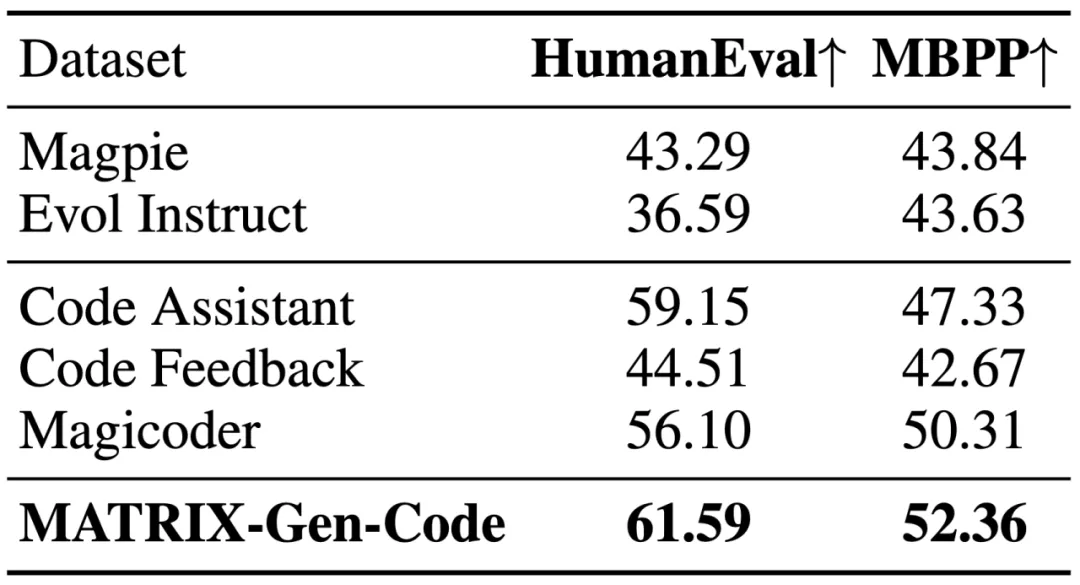
在代码生成与安全输出的任务中,MATRIX-Gen 合成的数据集均超越了对应领域的专用数据集,显示出 MATRIX-Gen 在合成数据上的高可控性。
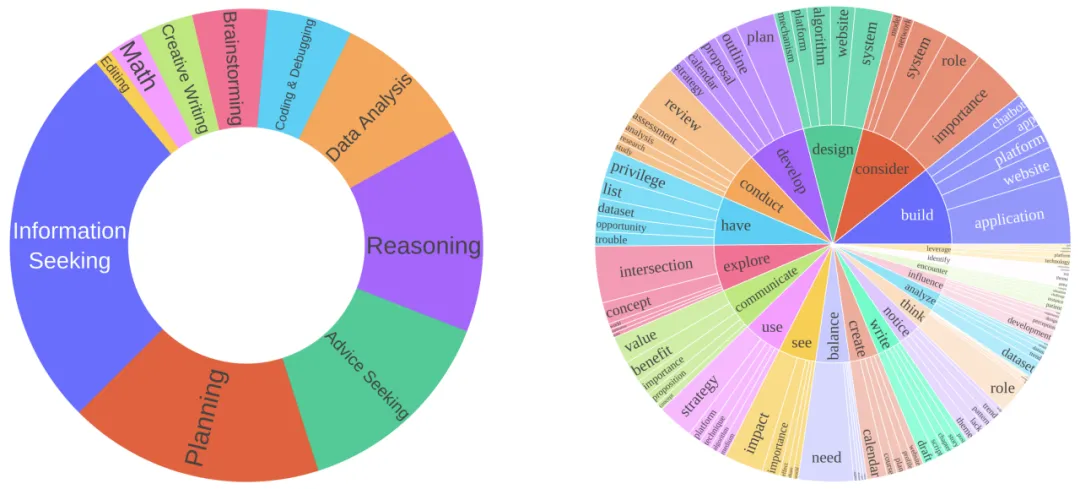
上图展示了 MATRIX-Gen-SFT 合成指令的可视化,显示出合成数据的多样性。
本研究提出了一种基于 AI 智能体社会模拟的后训练数据合成框架。依托 MATRIX 合成的 AI 模拟社会,MATRIX-Gen 能够可控地合成高质量的多样数据。在通用和专用任务中,仅使用 0.2% 的数据,即可获得优于大模型研发领军团队 Meta AI 所用数据集的模型训练效果,突显了 MATRIX-Gen 在数据合成中的优势。
本研究希望该数据合成框架能够帮助定量研究何种类型的数据更适合用于监督微调和偏好优化,深入探讨不同数据特性对模型性能的影响。此外,我们展望通过引入更强大的 AI 智能体,如具备工具调用能力的 AI 智能体,以及接入更丰富的环境,进一步合成更复杂的数据,从而提升大语言模型在复杂任务中的表现。
文章来自于“机器之心”,作者“唐铄、庞祥鹤、刘泽希和唐博瀚”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
