# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
传统的训练方法通常依赖于大量人工标注的数据和外部奖励模型,这些方法往往受到成本、质量控制和泛化能力的限制。因此,如何减少对人工标注的依赖,并提高模型在复杂推理任务中的表现,成为了当前的主要挑战之一。

Meta的研究团队提出了 自一致性首选项优化(Self-Consistency Preference Optimization,SCPO) 这一创新方法,为解决这一问题提供了新的思路。SCPO通过一种独特的训练机制,利用模型自身的推理一致性来优化其能力,而无需依赖人工标注的答案或外部奖励模型。这个方法特别适用于数学推理、逻辑推理等多步骤的复杂任务,并能在没有金标准标签的情况下,显著提高模型的推理准确性。

图片由修猫制作
1.人工标注的局限性
标注成本高昂,特别是复杂推理任务的标注需要专家参与。
标注质量难以保证,尤其是在规模扩展时,数据质量的控制成为瓶颈。
人工标注的扩展性受限,无法快速应对任务需求的变化。
2.外部奖励模型的问题
在分布外(OOD)问题上表现不佳,无法处理超出训练数据分布的新类型问题。
需要额外的训练成本,包括对奖励模型本身进行调优和标注。
奖励模型可能引入新的偏差,使得训练过程更为复杂。
3.自评估方法的不可靠性
模型难以准确评估自己的答案,特别是在多步骤推理中,模型往往难以判断其每一步的合理性。
自我确认偏差可能导致模型陷入错误的答案路径中,无法自我纠正。
缺乏客观的评判标准,自评估结果的可靠性较低。
SCPO的核心思想源于一个简单而深刻的观察:当模型多次回答同一个问题时,出现频率最高的答案往往更可能是正确的。这种方法依赖以下几个理论基础:
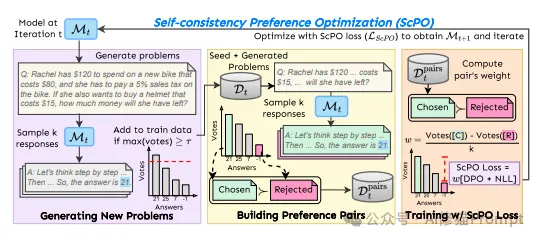
如图中左侧部分所示,SCPO首先通过少样本提示(few-shot prompting)生成新问题。初始的种子问题会被用作模板,通过模型生成新的类似问题。这些新问题会经过一致性验证,即模型对同一问题生成多次回答并进行投票。只有那些模型在回答中一致性较高的问题,才会被保留并添加到训练数据中,以此不断扩展数据集。
在图的中间部分,SCPO通过对每个生成的问题多次采样,得到多个不同的回答。这些回答通过投票机制进行评估,最终选出投票次数最多的答案作为“优选答案”,投票次数最少的作为“被拒绝答案”。这些答案对被称为首选项对(Preference Pairs),在训练过程中会用来优化模型,使模型更倾向于输出一致性高的答案。
如图右侧部分所示,SCPO通过一个创新的加权损失函数来训练模型。在每个首选项对中,“优选答案”和“被拒绝答案”根据其在投票中的表现赋予不同的权重。损失函数结合了直接偏好优化(DPO)和负对数似然(NLL),以确保模型不仅倾向于选择自一致性高的回答,同时逐步减少不一致性。这一迭代训练过程使得模型在每次迭代中都朝着更加精确、稳健的方向演化。
SCPO使用了一个创新的加权损失函数,结合了直接偏好优化(DPO)和负对数似然(NLL)损失,以确保模型不仅在选择答案上更偏好一致性高的选项,而且在生成过程中减少不一致性。
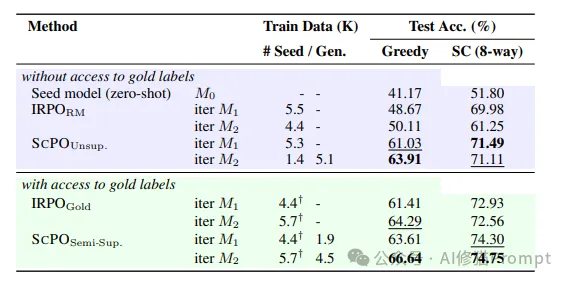
实验结果表明,在GSM8K和MATH数据集上,SCPO方法在没有使用任何金标准答案的情况下显著提升了模型的零样本推理能力。在GSM8K数据集上,经过两轮SCPO训练,模型的准确率从基础模型的41.17%提升至63.91%,几乎达到了使用全量监督学习训练模型的表现(64.29%)。在MATH数据集上,SCPO的效果也非常显著,准确率从基础模型的14.46%提高到19.72%。
此外,研究者还发现,当SCPO与标准的监督学习结合使用时,模型的性能得到了进一步的提升。例如,在有监督的数据集上,使用半监督SCPO的模型在GSM8K数据集上的准确率比仅使用监督学习的基线模型提高了2.35%(从64.29%提高到66.64%)。
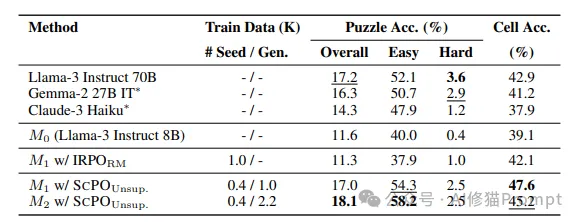
在更具挑战性的逻辑推理任务ZebraLogic上,SCPO的效果尤为显著。经过两轮SCPO训练,模型在ZebraLogic测试集上的整体解谜准确率从基础模型的11.6%提升至18.1%,甚至超越了一些更大规模的语言模型,如Llama-3 70B(17.2%)和Claude-3 Haiku(14.3%),展示了SCPO在逻辑推理任务中的强大能力。
对比实验表明,SCPO即使在完全无监督的情况下,其推理性能几乎可以媲美使用全量标注数据进行监督训练的模型。而当SCPO结合部分标注数据进行半监督训练时,模型在多个任务上的表现甚至超过了传统的全监督训练方法。例如,在MATH数据集上,SCPO的半监督模型准确率达到了20.48%,超过了仅使用外部奖励模型的18.08%。这些结果进一步验证了SCPO的有效性和实用性。
实验还表明,SCPO的加权损失函数对于模型的训练至关重要。与未加权的损失函数相比,加权的SCPO损失函数能够更有效地引导模型向正确答案学习,特别是在训练的早期阶段,准确率显著提升。在GSM8K数据集上,加权损失函数的模型在第一轮训练后的准确率比未加权的版本高出2.5%,这表明考虑答案的自信度是优化模型推理能力的重要因素。
SCPO通过投票机制衡量模型对某个回答的自信度。在多轮训练后,模型在推理任务上的一致性显著提高,不仅提升了答案的稳定性,也增强了整体推理性能。研究者还发现,自一致性与模型的推理准确率密切相关,这进一步支持了SCPO在推理任务中的有效性。
为了进一步评估SCPO的有效性,研究者将其与依赖外部奖励模型的IRPO方法进行了比较。结果显示,SCPO在各项任务中的表现均优于IRPO,尤其是在逻辑推理任务中,SCPO的方法更加稳定且泛化性更强。与依赖于外部奖励模型不同,SCPO不依赖于外部的金标准标签,从而能够更好地处理不同分布外的新类型推理任务。
SCPO特别适用于以下几个应用场景:

Slide left and right to see more
SCPO方法为Prompt工程师提供了一个全新的视角,展示了如何通过巧妙的机制设计来提升模型能力。这种方法不仅降低了对人工标注的依赖,还提供了一条可扩展的模型能力提升路径,尤其是在标注困难的复杂推理任务中,SCPO的方法展示了强大的潜力和实践价值。它的出现,代表了LLM从“被动学习”向“主动自我优化”迈出的重要一步,为AI领域的自我对齐和自我改进提供了新的可能性。
文章来自于微信公众号“AI修猫Prompt”,作者“ AI修猫Prompt”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
