# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,谷歌官方宣布了一条重磅消息:
Keras之父François Chollet,正式离职。

这篇文章由谷歌两位VP(包括谷歌刚挖来的华人Bill Jia)共同撰写,表达了对这位在谷歌长达9年零3个月的AI大佬,在工作上的认可及离职的惋惜。
从内容上来看,谷歌先是肯定了Keras这个深度学习框架目前取得的成绩——
已经成为人工智能发展的基石,用户数量超过200万,简化了复杂的工作流程,让尖端技术变得唾手可得。
并且这项技术已然得到了广泛地应用,从Waymo的自动驾驶,到YouTube、Netflix和Spotify的推荐等。
不过虽然François已离职,但他承诺将继续参与Keras未来的发展,还将继续支持JAX、TensorFlow和PyTorch上的工作。
而谷歌的Keras团队,则将继续与François的开源社区保持合作。

至于François最新的动向,谷歌和其本人截至目前并没有透露。
而网友们对于François的离职却展开了一番激烈的讨论。
例如从Keras的发展现状来看,有人认为它在谷歌已经不香了:
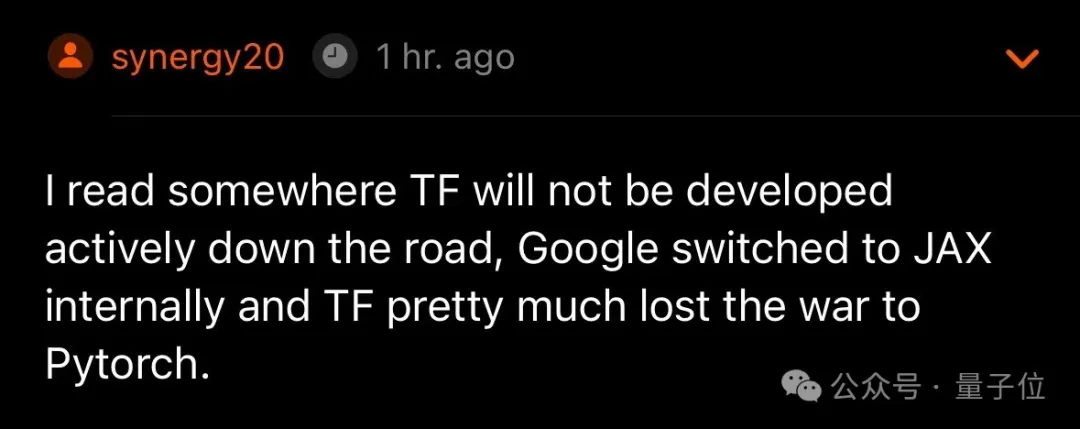
我曾在某处看到,未来TensorFlow可能不会得到积极开发,谷歌内部转向了JAX;TensorFlow几乎已经输给了 PyTorch。
针对谷歌在官宣中对Keras给出的评价,有网友表示:
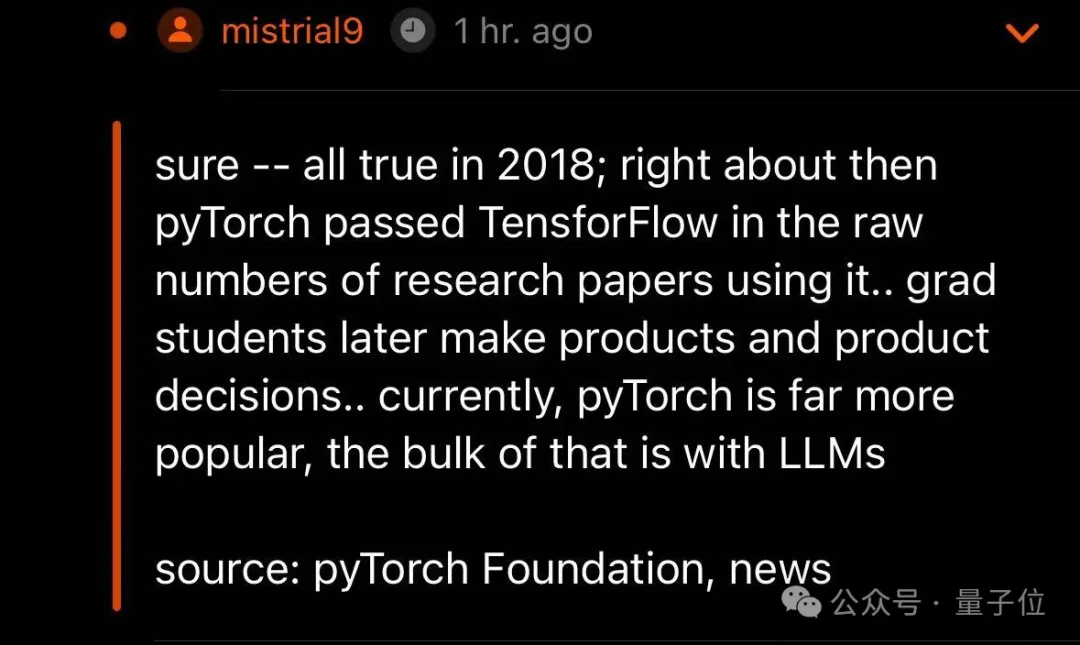
若是在2018年,这是事实;但现在,PyTorch的受欢迎程度远高于TensorFlow,其中很大一部分原因与LLM有关。
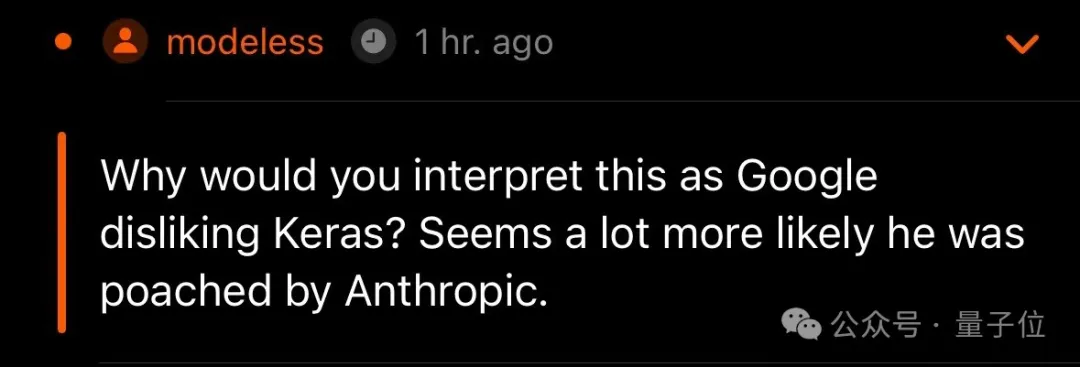
而从François个人动向方面来看,有网友猜测他可能被Anthropic挖了墙角……
Keras最早可以追溯到2015年,是由François发布的一个开源神经网络库。
它最初的目的是提供一个高级深度学习API,用来简化深度学习模型的构建和实验过程。
因为在Keras出现之前,深度学习开发通常需要直接使用底层库(如Theano),用户需要编写大量复杂代码才能构建一个基础的神经网络模型。
而Keras的出现可谓是改变了这一局面。
它通过模块化和直观的API让深度学习的构建流程大大简化,极大地降低了进入深度学习领域的门槛。
正如它官方给自己的定位那般:
为人类设计的深度学习。
Keras一开始是独立于具体计算引擎的高级库,支持Theano、Microsoft CNTK和TensorFlow作为其底层后端。
在技术上,Keras采用模块化的设计,用户可以通过组合不同类型的层(如全连接层、卷积层、循环层)来快速搭建复杂的模型。
模型的训练、验证和测试过程通过统一的接口实现,开发过程可以说是非常顺畅。
Keras提供了Sequential API用于线性堆叠模型层,后来又引入了Functional API,来支持复杂的非线性网络结构和多输入多输出模型的构建。
这些特性让Keras不仅适合简单的原型设计,还能够应对实际生产中的复杂需求。
但随着TensorFlow的快速发展,二者之间的关系变得越来越紧密。
到了2017年,Keras被谷歌选择成为TensorFlow官方的高级API。
在TensorFlow 2.0于2019年发布之后,Keras完全集成到了TensorFlow中,成为其默认的模型构建工具。
这标志着Keras从一个独立的高级库转变为TensorFlow的一部分。
这样做的好处当然是有的。
首先,Keras可以无缝调用TensorFlow的底层功能,从而提供更高的性能和可扩展性。
其次,TensorFlow提供了诸如GPU加速、TPU支持、分布式训练等高性能特性,整合后的Keras也能够轻松利用这些特性。
这种转变不仅增强了Keras的功能,还使得它更适用于生产环境的大规模应用。
然而,随着整合的推进,Keras作为独立库的角色逐渐淡化,tf.keras成为TensorFlow官方高级 API,也成为深度学习社区的标准选择之一。
除此之外,作为深度学习框架演变的缩影——TensorFlow和PyTorch之间的竞争,也一定程度上波及到了Keras的发展。
PyTorch是由Facebook AI Research在2016年推出。
它的核心优势在于动态计算图(Dynamic Computational Graph),可以让代码执行得更加灵活,开发者可以像编写普通Python代码一样进行模型的构建和调试。
相比之下,早期的TensorFlow采用静态计算图(Static Computational Graph),尽管执行效率较高,但在模型开发阶段的灵活性和调试便利性方面逊色于PyTorch。
这种技术差异使得PyTorch特别受到研究人员的青睐,尤其是在实验和快速迭代等工作中。
为了缩小与PyTorch在灵活性方面的差距,TensorFlow 2.0引入了与其类似的动态图功能,通过Eager Execution和 tf.function 提供了更为灵活的开发体验。
这一演变使得TensorFlow在保持高性能优化的同时,也具备了PyTorch式的开发灵活性。
但此举似乎并未完全弥补与PyTorch在用户体验上的差距。

当然,Keras这边也是在不断迭代优化。
例如在去年年底,Keras发布了3.0版本,被誉为改变了机器学习游戏规则。
不仅支持TensorFlow、PyTorch、Jax三大框架作为后端,还能在它们之间无缝切换,甚至混合使用。
François当时在自己的社交账号中概述了这样做的四大好处,包括:
不过即便如此,像Cohere机器学习总监Nils Reimers也给Keras敲了个警钟:
希望历史不要重演。
Reimers认为,Keras最初从支持单个后端(Theano)开始,陆续添加了Tensorflow、MXNet和CNTK等多后端。
这引发了一系列问题:
随着时间推移,这些问题愈发严重:某些模块只能在 Theano 上运行良好,某些只适用于Tensorflow,还有一些模块可以在MXNet上进行推理,但无法训练…
我希望这一次的多后端能有更好的表现,但这无疑仍是一个挑战。
提到Keras之父,François Chollet这个名字在AI圈里可以说是家喻户晓。
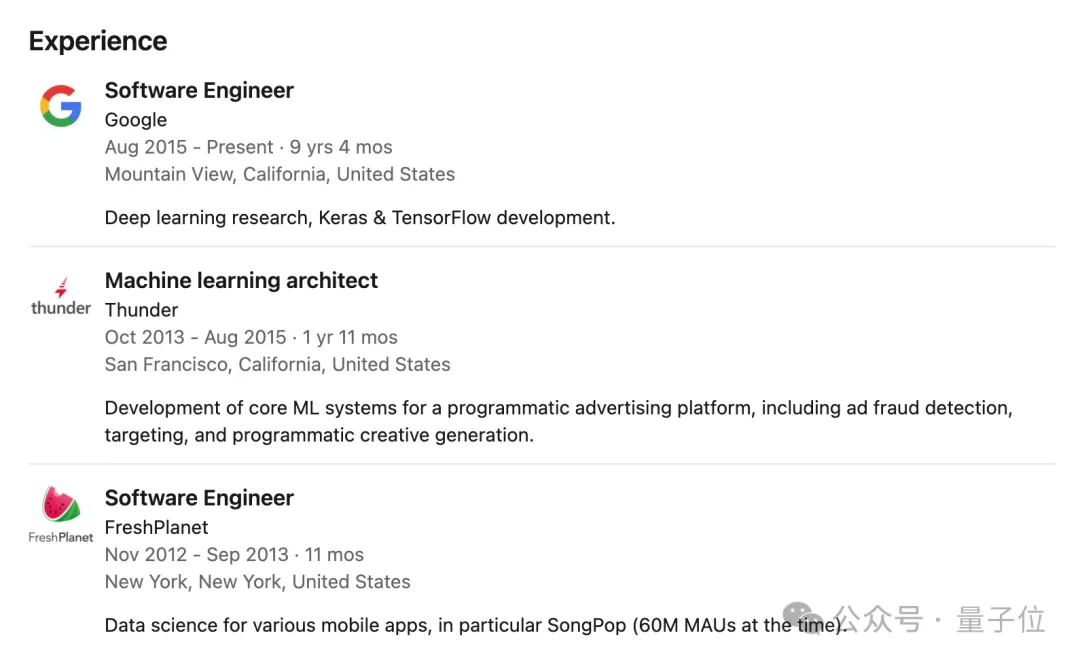
他出生于1989年10月20日,从履历上来看,他在2012年取得巴黎综合理工学院工程硕士学位之后,并没有选择继续深造,而是前往美国就职。
François先后分别在FreshPlanet和Thunder分别担任软件工程师和机器学习架构师;最后于2015年加入谷歌,直至今天。
在与国外知名访谈博主Lex Fridman交流过程中,François也回顾了Keras诞生的故事。
在2014年,那时候最受欢迎的深度学习库还是用C++编写的Caffe(贾扬清出品),当时Caffe要比Theano更受欢迎。
而到了年底,François突然对循环神经网络产生了浓厚的兴趣。
当时,这还是一个相对小众的领域,于是他便开始寻找适合的工具进行探索。
在参与Kaggle比赛期间,François尝试了诸如Torch7和Theano等工具,也使用过Caffe,但当时Caffe并没有提供理想的循环神经网络解决方案,例如缺少可重复使用的开源LSTM实现。
于是乎,François便有了一个想法,自己动手构建一个框架。
他最初的想法是主要集中在LSTM和RNN的实现上,且使用Python来编写。
期间一个非常重要的决定是——模型将通过Python代码来定义。
这可以说是与当时的主流想法是背道而驰,因为像Caffe、Theano这样的库通常使用YAML等静态配置文件来定义模型。
但其实有些库是用代码定义模型的,例如Torch7(但不是Python)。
而在François此前的工作实践中,scikit-learn这个开源深度学习库深得他的心意,因此他从中获取了大量的灵感。
用他的话来说就是,Keras几乎就是为神经网络打造的scikit-learn。

有意思的是,Keras这个名字,还是François他在发布当天临时定下来的。
并且François还坦言:
几个月后我加入谷歌,其实跟Keras没有任何关系。
我当时加入了一个研究团队,专注于图像分类和计算机视觉领域,因此最初在谷歌的工作主要是进行计算机视觉研究。
刚加入谷歌时,我接触到了TensorFlow的早期内部版本,它吸引我的原因在于它是Theano的改进版。那一刻,我就意识到必须把Keras移植到这个全新的TensorFlow上。
而后,也就是有了Keras与TensorFlow集成的故事。

至于除了这次离职的动作之外,François上一次步入大众的视频,还是一次访谈。
在这次访谈中,他表示打算用100万美元搞AGI竞赛。
至于原因,是因为他觉得现有的AI技术,尤其是LLM,主要依赖于记忆和模仿人类数据中的模式,在新情境下的新推理和技能获取方面表现不佳。
其实早在2019年,François就提出了ARC-AGI ——唯一衡量AGI能否有效获取新技能并解决开放式问题的评估标准。
目前,最好的AI系统在ARC基准测试中的得分为34%,而人类包括儿童在内均能轻松得分85%。
因此ARC Prize鼓励开源合作,以提高新想法的产生率,增加发现AGI的机会,并确保这些新想法得到广泛传播。

至于François下一步的动向,量子位也将继续保持关注。
参考链接:
[1]https://developers.googleblog.com/en/farewell-and-thank-you-for-the-continued-partnership-francois-chollet/
[2]https://news.ycombinator.com/item?id=42130881
[3]https://time.com/7012823/francois-chollet/
[4]https://en.wikipedia.org/wiki/Fran%C3%A7ois_Chollet
[5]https://www.linkedin.com/in/fchollet/
[6]https://keras.io/keras_3/
文章来自于“量子位”,作者“金磊”。




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
