# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

继 OpenAI o1 成为首个达到 Kaggle 特级大师的人工智能(AI)模型后,另一个 Kaggle 大师级 AI 也诞生了。
根据 Kaggle 的晋级系统,由华为诺亚方舟实验室和伦敦大学学院团队联合推出的端到端自主数据科学智能体(agent)——Agent K v1.0,已经能够获得 6 枚金牌、3 枚银牌和 7 枚铜牌。

论文链接:https://arxiv.org/abs/2411.03562
据介绍,Agent K v1.0 具备动态、多步骤处理复杂问题的能力,通过动态管理记忆并从经验中持续学习,能够完全自动化数据科学流程,并在不依赖微调的情况下,通过环境反馈不断优化决策,实现对各种数据科学任务的自动化、优化和泛化。
当前,虽然 LLM 在自然语言交互方面展现优秀性能,但如何使 LLM 能够基于智能体处理具有序列或并行任务模块的系统性数据科学任务,构建能对各种数据科学任务进行自动化、优化和泛化的LLM 智能体,从而实现动态、多步骤的问题解决仍然是个挑战。
为解决这个问题,研究团队提出了一个灵活的基于经验学习推理的替代框架,借鉴了强化学习中的马尔可夫决策过程(MDP)概念,不过其独特性在于引入了结构化推理和长期记忆机制。这一创新举措避免了传统思维链或思维图方法对反向传播和微调的依赖,使得智能体能够在不更改 LLM 核心参数的情况下,实现动态学习与适应。
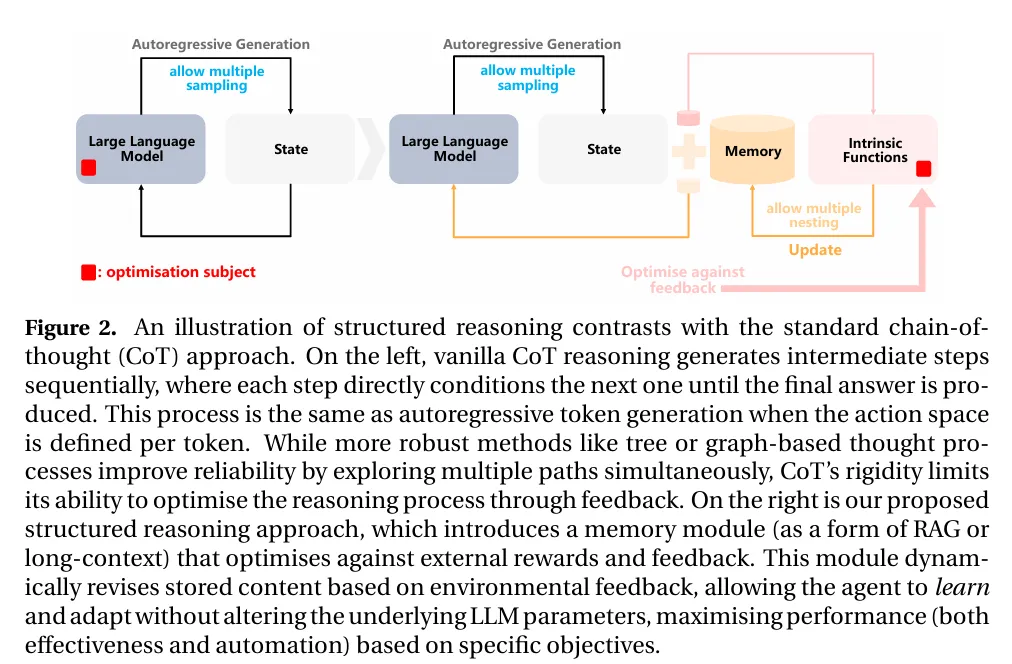
图|结构化推理的示意图与标准的思维链(CoT)方法形成对比。
在 Agent K v1.0 的框架体系中,智能体具备三种类型的动作,分别为长期记忆动作、内部动作以及外部动作。长期记忆动作用于对外部数据库的内容进行管理,将过往经验转化为指导当下决策的珍贵信息;内部动作则旨在更新工作记忆,塑造智能体的推理过程;外部动作直接与环境进行交互,执行任务并获取奖励。
智能体通过与环境的互动,收集状态、工作记忆以及外部数据库的轨迹信息。随后,利用 LLM 的内部策略来更新工作记忆和长期记忆。这些策略能够依据环境反馈,动态调整智能体的推理过程,使其可以根据具体情况做出最优决策,从而最大限度地实现回报。
总体而言,Agent K v1.0 的学习框架凭借结构化推理和长期记忆机制,达成了 LLM 在复杂数据科学任务中的高效学习与适应,为构建自动化、高效且可扩展的数据科学智能体开辟了崭新的途径。
此外,Agent K v1.0 具有全新的自动化数据科学任务处理方式。
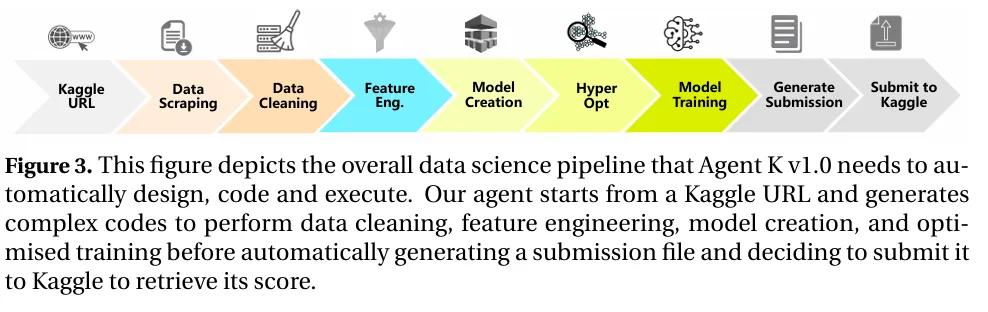
图|Agent K v1.0 自动设计、编码和执行的整体数据科学流程。
首先,在数据科学任务设置的自动化阶段,Agent K v1.0 能够将数据科学任务精细分解为多个阶段,如数据抓取、数据摘要、模态检测、数据预处理以及特征工程等。
同时,利用单元测试对每个阶段的正确性进行严格验证。而当单元测试失败时,Agent K v1.0 会利用 LLM 生成解释错误原因的思考,并依据这些思考重新执行之前步骤,直至找到并修复错误。
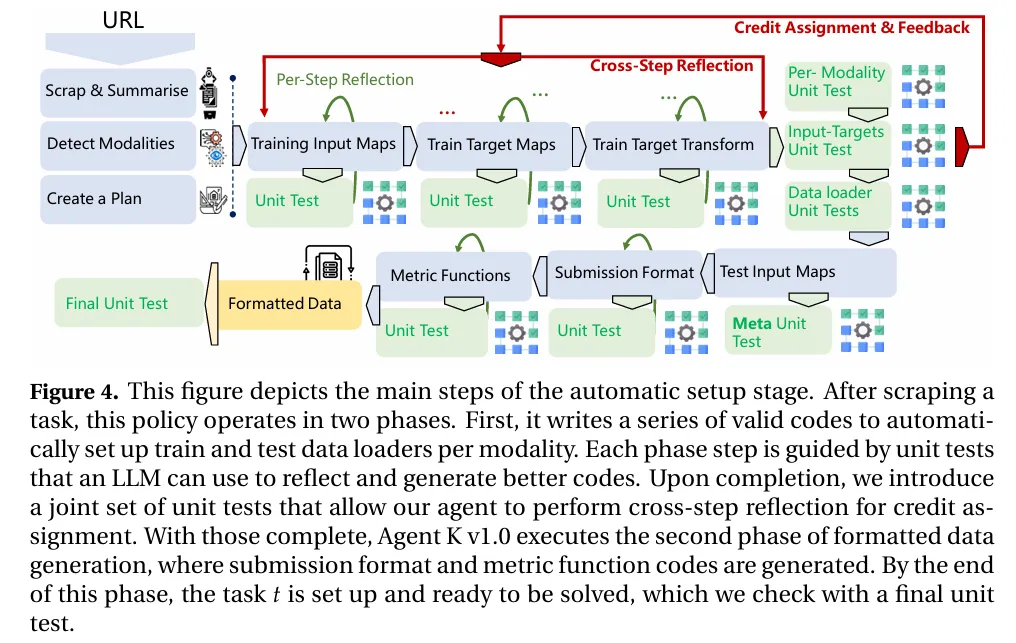
图|自动设置阶段的主要步骤。
之后,在数据科学任务解决的优化阶段,Agent K v1.0 根据任务所涉及的模态类型,选择不同的工具和方法生成解决方案。对于表格数据任务,它使用 AutoML 工具自动生成预测;对于计算机视觉、自然语言处理和跨模态任务,则采用深度神经网络模型。此外,它还集成了多种工具,如 HEBO 进行超参数优化,以及利用 HuggingFace 的 Torchvision 和 Torchtext 库处理不同模态的数据。
不仅如此,Agent K v1.0 在多任务和持续学习方面也表现出色。它可以处理多个不同领域的数据科学任务,通过共享长期记忆实现知识迁移。同时,它会根据之前的经验选择下一个任务,构建难度逐渐增加的课程,以实现持续学习和知识积累。
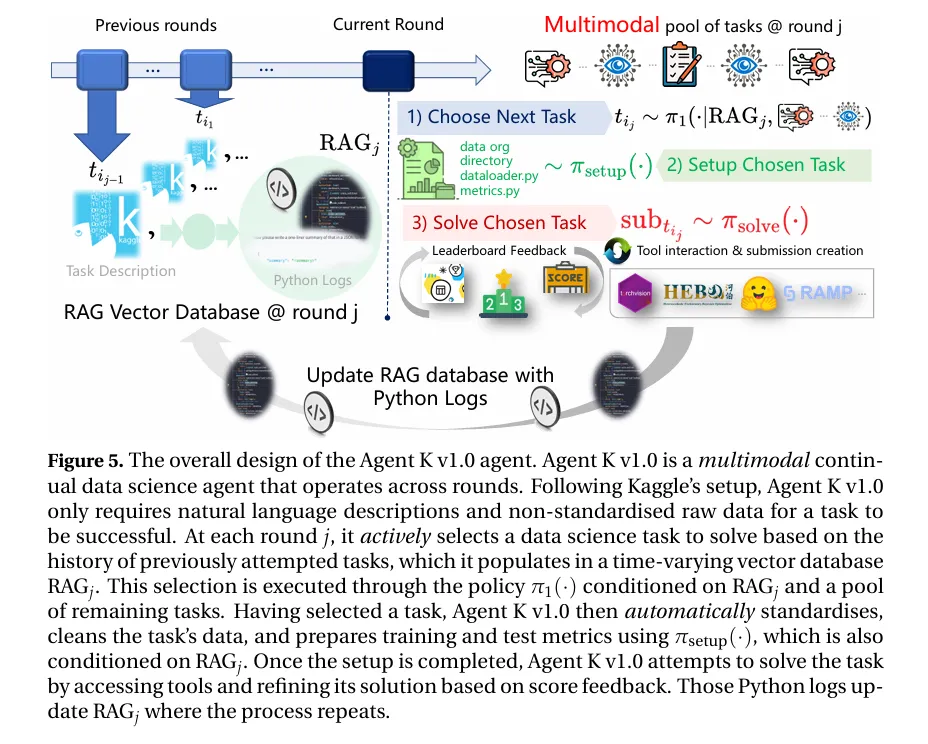
图|Agent K v1.0 作为一个多模态、持续学习的数据科学智能体,能够在多轮操作中进行任务。
为了客观评估 Agent K v1.0 的性能,研究团队构建了一个基于 Kaggle 竞赛的竞争性数据科学基准。该基准涵盖了 Kaggle 平台上多达 65 个多样化的数据科学任务,涵盖表格数据、计算机视觉、自然语言处理以及跨模态任务等多个领域。
此外,该基准还评估了 Agent K v1.0 自动设置数据科学任务的能力,涵盖数据抓取、数据预处理、特征工程和模型训练等步骤。并通过单元测试来验证每个阶段的正确性,并评估智能体在不同模态和任务类型上的自动化成功率。

图|基准测试中 Kaggle 任务的分布饼图。
在性能评估方面,该基准使用 Kaggle 平台的公开和私有分数来评估 Agent K v1.0 的性能。根据 Kaggle 的排名系统,将智能体的表现与其他 Kaggle 用户进行比较,并计算其 Elo-MMR 积分,以评估其在 Kaggle 用户群体中的相对位置。
为确保公平比较,该基准考虑了竞赛规模,不同竞赛的参与者和提交数量可能不同,因此需使用 Elo-MMR 积分来进行比较;以及竞赛类型,社区竞赛、练习场竞赛和特色竞赛的难度和竞争程度不同,因此需使用 Kaggle 的排名系统来进行评估。

图|该表格描述了Kaggle的晋升系统,遵循Kaggle的指南和风格。
研究团队还在 65 个 Kaggle 竞赛中对 Agent K v1.0 进行了测试。这些比赛可以由智能体自主设置,并且可以生成至少一个提交。与之前的工作不同,测试遵循了标准的 Kaggle 竞赛指南,其中智能体创建一个提交文件,并使用 Kaggle API 自动提交其解决方案。
智能体的解决方案在提交后被评估和排名在排行榜上,其性能将与参与者进行量化比较。为了确保公平性,这些量化指标基于可用的私人排行榜,并且仅使用公共排行榜结果来决定保留的提交,这反映了据科学家在 Kaggle 平台上的标准做法。
为了提高其性能,Agent K 使用基于内部训练数据拆分的验证损失。该损失和智能体内存中已有的代码帮助 LLM 反思并生成更成功的代码,最终提高其排名。
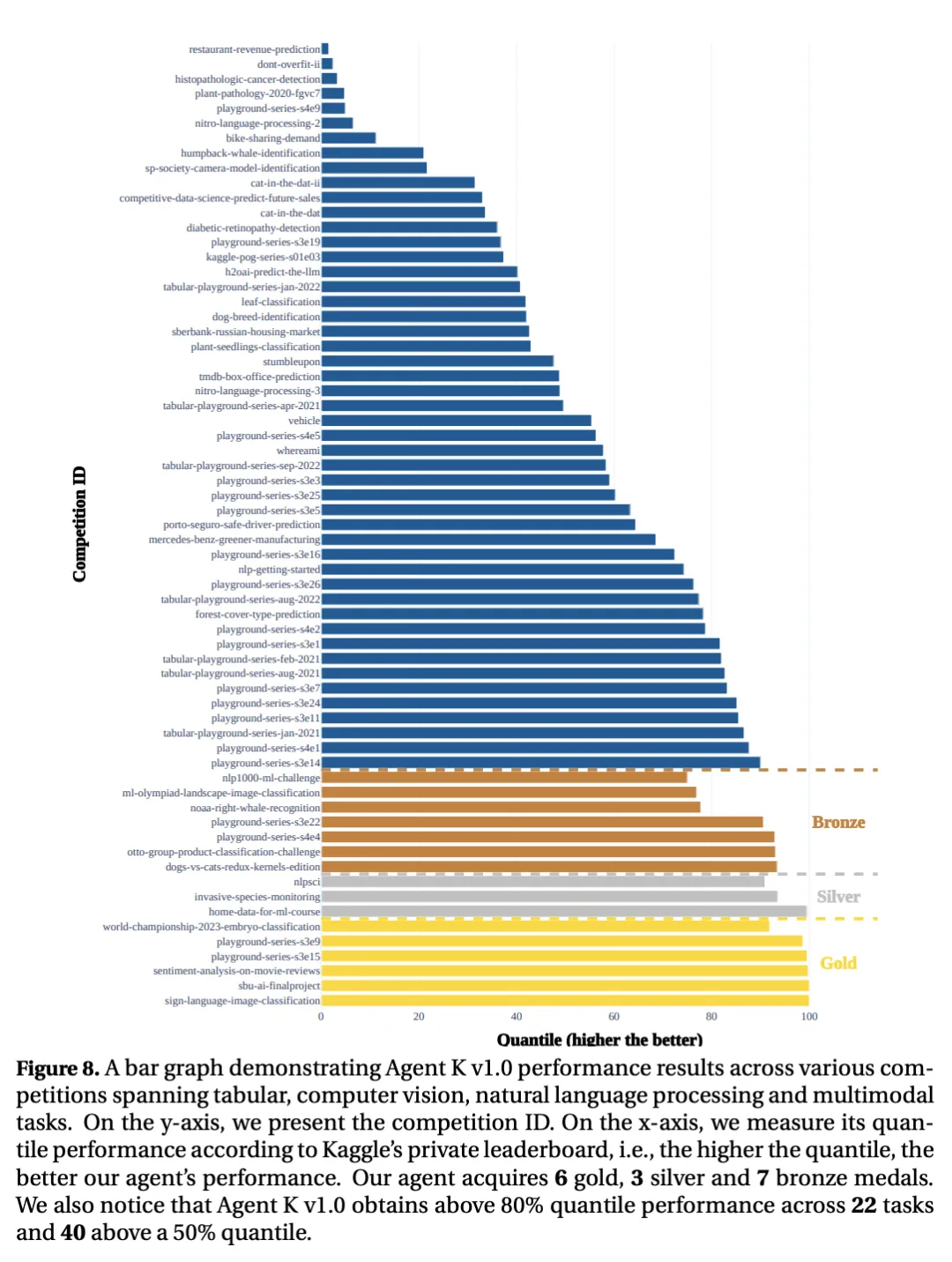
图|展示了 Agent Kv1.0 在各类比赛中的表现,涵盖了表格、计算机视觉、自然语言处理和多模态任务。y 轴为比赛的 ID;x 轴为根据 Kaggle 的私人排行榜衡量出的分位数表现,分位数越高,智能体表现越好。
根据 Kaggle 的评估方法,Agent K v1.0 获得了相当于 6 枚金牌、3 枚银牌和 7 枚铜牌的成绩。整体表现与 Kaggle 高级用户相当,甚至超过了部分顶级 Grandmaster 用户的水平。在 22 个任务中,Agent K v1.0 取得了超过 80% 的量化指标,在 62% 的竞赛中取得了超过 50% 的量化指标。
虽然 Agent K v1.0 在 Kaggle 数据科学竞赛中取得了令人瞩目的成绩,达到了 Kaggle 大师级水平,但其仍然存在一些不足之处。
第一,任务设置过程反馈单一。目前 Agent K v1.0 在设置任务时仅基于单元测试和元单元测试的反馈。未来将通过进一步引入反馈机制,识别哪些代码和数据预处理步骤能有效提升模型性能,从而优化任务设置的智能性。
第二,工具扩展与性能反馈机制依托工具简单。当前 Agent K 使用了一些现有工具(如 HEBO、RAMP 等)进行超参数优化和特征工程。未来计划引入更多工具,特别是能支持视频和音频处理的新模块,并研究更加有效的基于性能反馈的结构来优化 LLMs 的使用。
第三,目前的持续学习机制主要基于任务设置优化,后续计划将性能反馈融入任务选择的决策中,使 Agent K 能根据历史经验来评估任务难度及潜在表现,更好地利用知识积累来提升任务处理能力。
未来,研究团队计划进一步扩展现有的评估基准,不仅增加处理任务的数量,还将多模态挑战如音频和视频数据纳入其中,力求覆盖更广泛的真实场景,以提升系统的多样性和实用性。研究还将使 Agent K v1.0 更适应“可运行的notebook”竞赛要求,提升其在多种竞赛环境中的灵活性和适应性,并计划参与实时竞赛来更精准地验证系统的实际竞争力。
通过这些优化,Agent K v1.0 有望在多种任务和领域中进一步提升其自主数据科学能力,逐步向真正的 Kaggle 大师级目标迈进。
文章来自于“学术头条”,作者“阮文韵”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
