# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

文本到图像的生成模型让创作更加灵活,用户可以用自然语言引导生成图像。然而,要让这些模型在不同的提示下始终如一地描绘同一主题仍然很难。现有的方法通常是微调模型,教它一些新词来描述特定的用户提供的主题,或者在模型中加入图像条件。可这些方法通常需要很长时间来为每个主题进行优化,或者需要进行大规模的预训练。而且,它们在图像和文本匹配以及多个主题的生成上也存在困难。
因此,英伟达提出了一种全新的方法—ConsiStory,摆脱了繁琐的训练过程,直接利用预训练模型的内部激活来实现一致的主题生成,不需要任何优化步骤。ConsiStory还能够轻松适应多个主题的情况,甚至可以实现对普通物体的个性化生成。(链接在文章底部,可以在线体验)

ConsiStory不需要模型微调或个性化设置,因此在H100显卡上生成一张图像仅需约10秒,比之前的最佳方法快了20倍!为了提升生成效果,ConsiStory 引入了“主体驱动的共享注意力模块”和“基于对应关系的特征注入”。

这些新方法有助于在多张图像之间保持主体的一致性。同时,还设计了方法,确保在生成不同布局的图像时,主体依然保持一致。

架构概述(下图左侧):给定一组文本提示后,在每一个生成步骤中,会定位每张生成图像I_i中的主体。为此,利用交叉注意力图,生成到当前步骤的“主体掩码” M_i。接着,用“主体驱动的自注意力”层来替代 U-net 解码器中的标准自注意力层,以便在图像中的主体实例之间共享信息。同时,还引入“特征注入”来进一步优化。
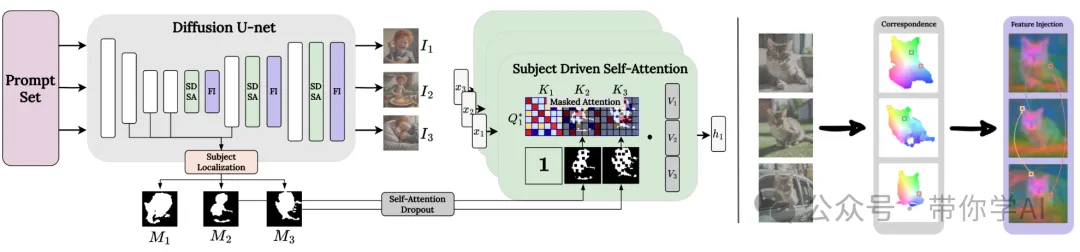
特征注入(上图右侧):为了进一步增强图像之间主体的身份一致性,引入了一种跨图像的特征混合机制。具体来说,在每对图像间生成一个“图块对应关系图”,然后基于这个图在图像间注入相应的特征,以此进一步统一主体形象。

主体驱动的自注意力:扩展了自注意力层,让每张生成图像I_i的查询(Query)可以访问批次中其他图像(I_j,其中 j≠i)的关键特征(Keys),但仅限于它们的主体区域 M_j。为了丰富生成的多样性,ConsiStory还进行了两项调整:(1) 使用“随机失活”(dropout)来弱化主体驱动的自注意力;(2) 将查询特征与非一致性采样步骤中的标准查询特征混合,从而得到 Q*。
将ConsiStory与 IP-Adapter、TI 和 DB-LoRA 进行了对比评估。部分方法未能保持一致性(如 TI),或者无法很好地跟随提示生成(如 IP-Adapter)。还有一些方法在保持一致性和跟随文本提示之间摇摆不定,无法同时做到这两点(如 DB-LoRA)。

ConsiStory 可以生成具有多个一致主题的图像集。

与 ControlNet 集成,以生成具有姿势控制的一致角色。

ConsiStory 根据不同的初始噪声生成一组风格一致的不同图像。

https://build.nvidia.com/nvidia/consistory
https://github.com/NVlabs/consistory
文章来自于微信公众号“带你学AI”,作者“ 弹贝斯的鱼”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
