# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Sora 的发布让广大研究者及开发者深刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型抛弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。
然而令人感到不解的是,U-Net 结构是之前最常用的扩散架构,在图像空间和隐空间的生成效果均表现不俗;可以说 U-Net 的 inductive bias 在扩散任务上已被广泛证实是有效的。因此,北大和华为的研究者们产生了一个疑问:能否重新拾起 U-Net,将 U-Net 架构和 Transformer 有机结合,使扩散模型效果更上一层楼?带着这个问题,他们提出了基于 U-Net 的 DiT 架构 U-DiT。

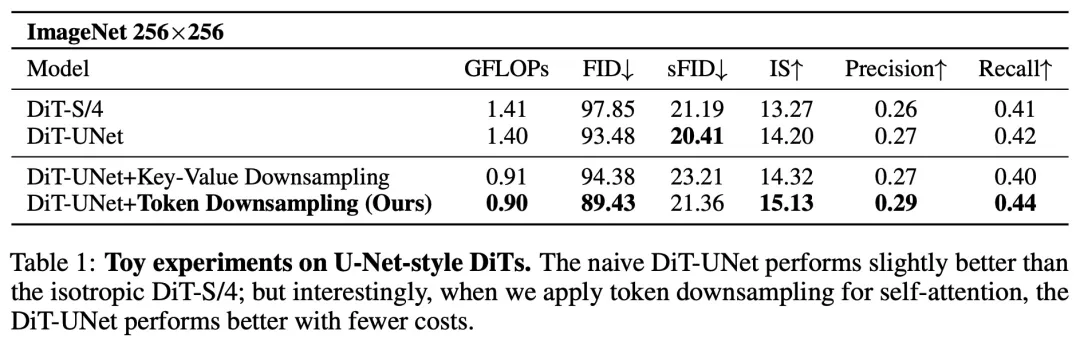
首先,研究者开展了一个小实验,在实验中尝试着将 U-Net 和 DiT 模块简单结合。然而,如表 1 所示,在相似的算力比较下,U-Net 的 DiT(DiT-UNet)仅仅比原始的 DiT 有略微的提升。
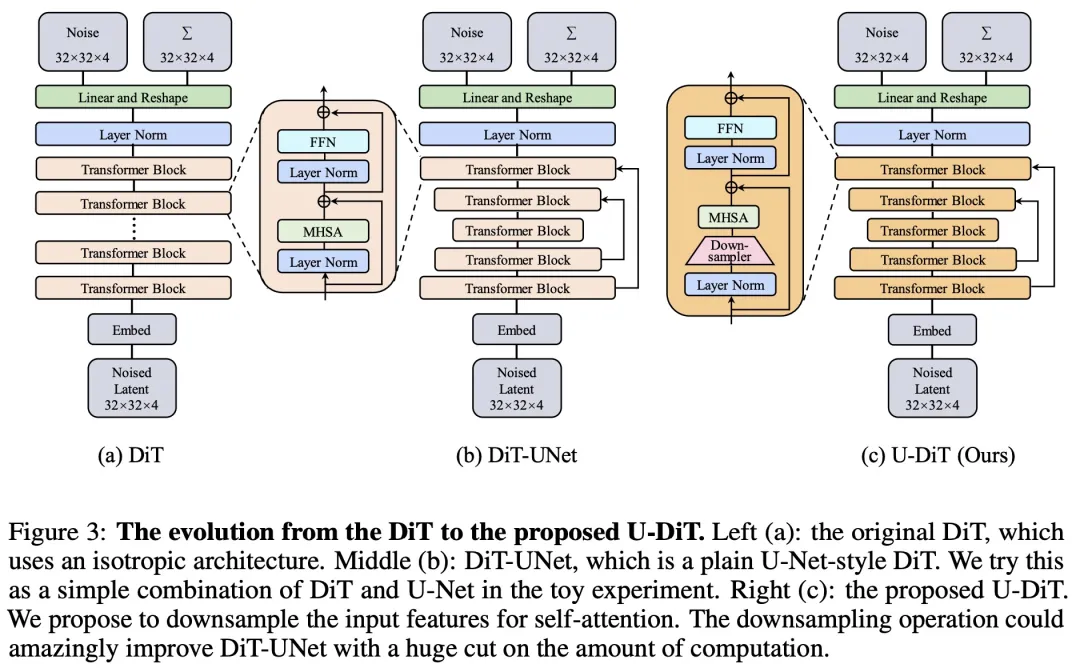
在图 3 中,作者们展示了从原始的直筒 DiT 模型一步步演化到 U-DiT 模型的过程。
根据先前的工作,在扩散中 U-Net 的主干结构特征图主要为低频信号。由于全局自注意力运算机制需要消耗大量算力,在 U-Net 的主干自注意力架构中可能存在冗余。这时作者注意到,简单的下采样可以自然地滤除噪声较多的高频,强调信息充沛的低频。既然如此,是否可以通过下采样来消除对特征图自注意力中的冗余?
由此,作者提出了下采样自注意力机制。在自注意力之前,首先需将特征图进行 2 倍下采样。为避免重要信息的损失,生成了四个维度完全相同的下采样图,以确保下采样前后的特征总维度相同。随后,在四个特征图上使用共用的 QKV 映射,并分别独立进行自注意力运算。最后,将四个 2 倍下采样的特征图重新融为一个完整特征图。和传统的全局自注意力相比,下采样自注意力可以使得自注意力所需算力降低 3/4。
令人惊讶的是,尽管加入下采样操作之后能够显著模型降低所需算力,但是却反而能获得比原来更好的效果(表 1)。
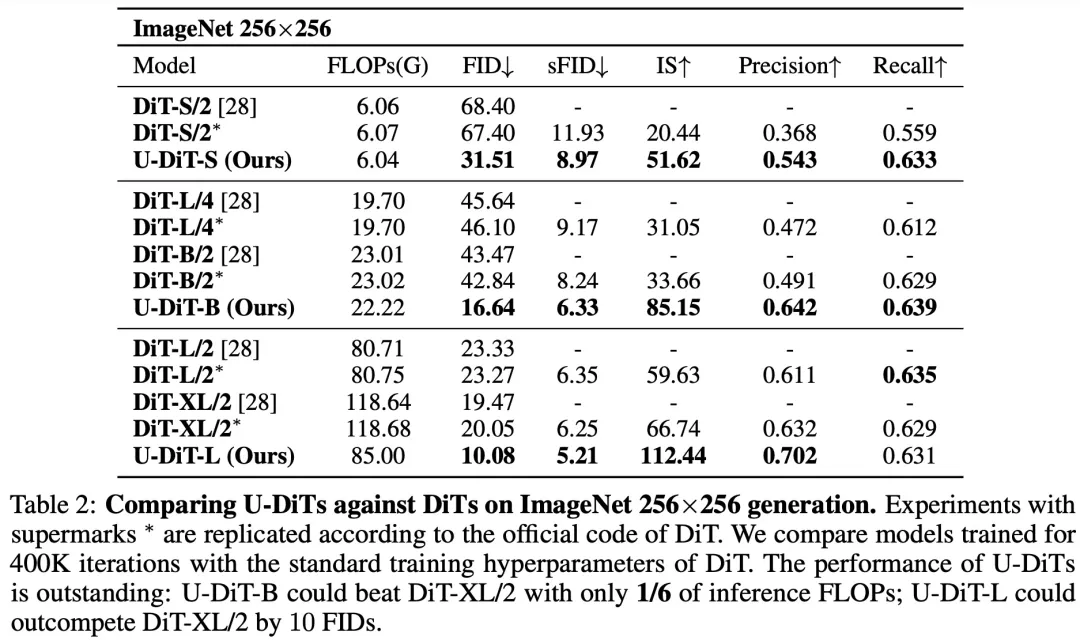
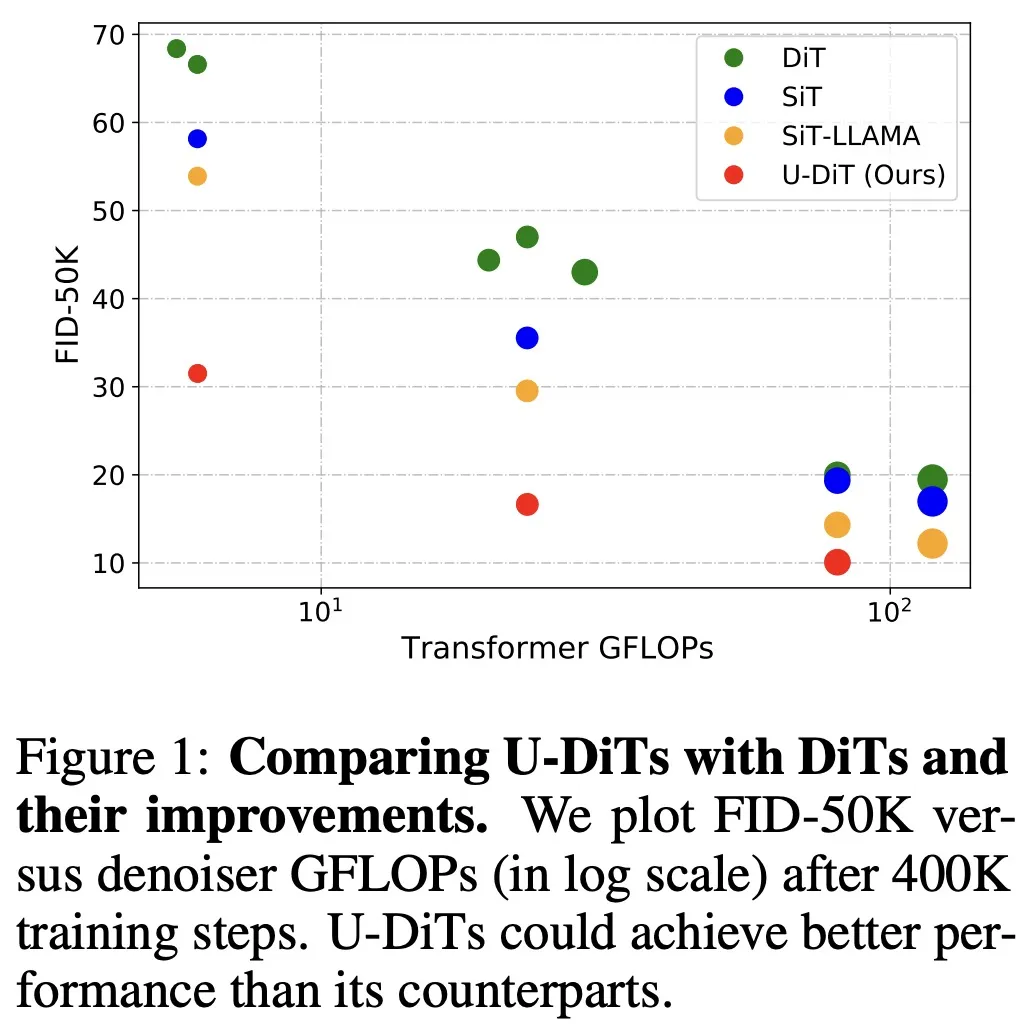
根据此发现,作者提出了基于下采样自注意力机制的 U 型扩散模型 U-DiT。对标 DiT 系列模型的算力,作者提出了三个 U-DiT 模型版本(S/B/L)。在完全相同的训练超参设定下,U-DiT 在 ImageNet 生成任务上取得了令人惊讶的生成效果。其中,U-DiT-L 在 400K 训练迭代下的表现比直筒型 DiT-XL 模型高约 10 FID,U-DiT-S/B 模型比同级直筒型 DiT 模型高约 30 FID;U-DiT-B 模型只需 DiT-XL/2 六分之一的算力便可达到更好的效果(表 2、图 1)。
在有条件生成任务(表 3)和大图(512*512)生成任务(表 5)上,U-DiT 模型相比于 DiT 模型的优势同样非常明显。
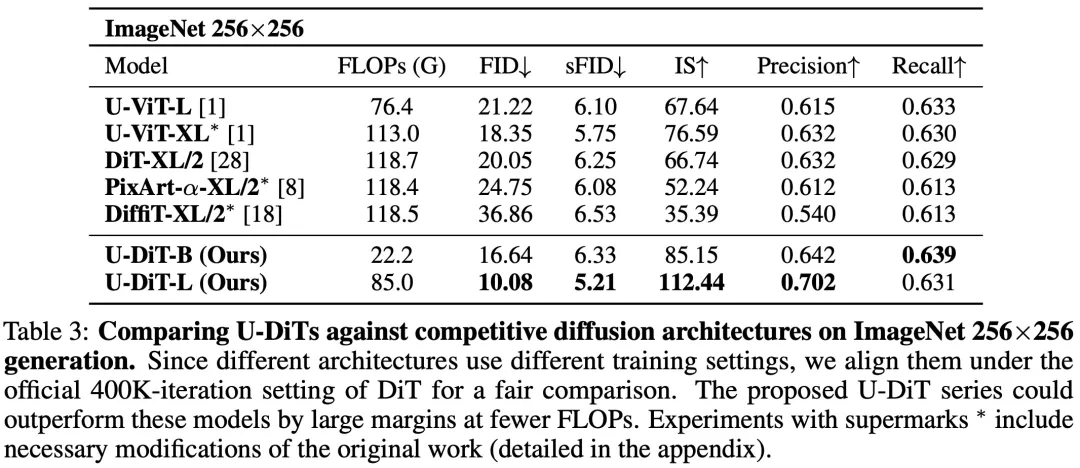
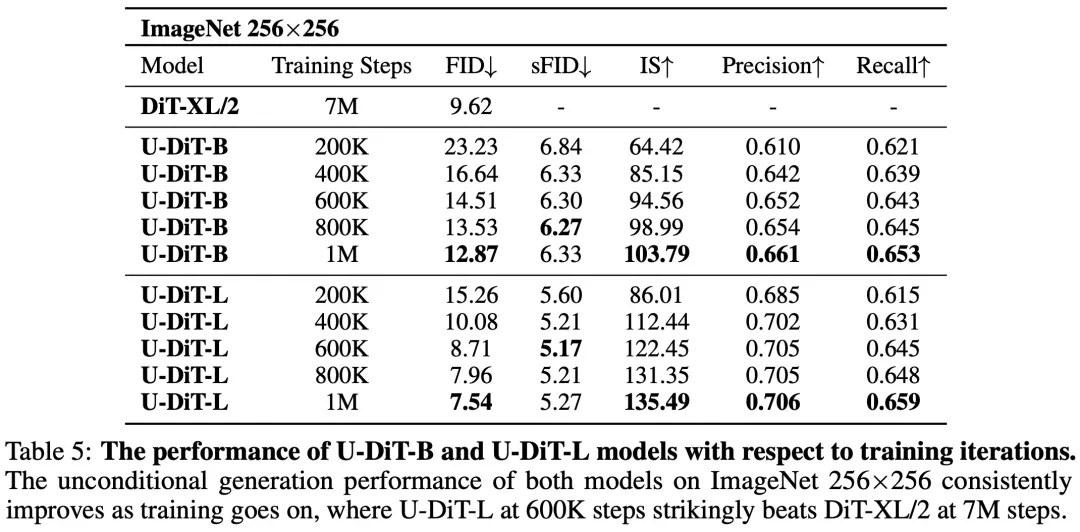
研究者们还进一步延长了训练的迭代次数,发现 U-DiT-L 在 600K 迭代时便能优于 DiT 在 7M 迭代时的无条件生成效果(表 4、图 2)。
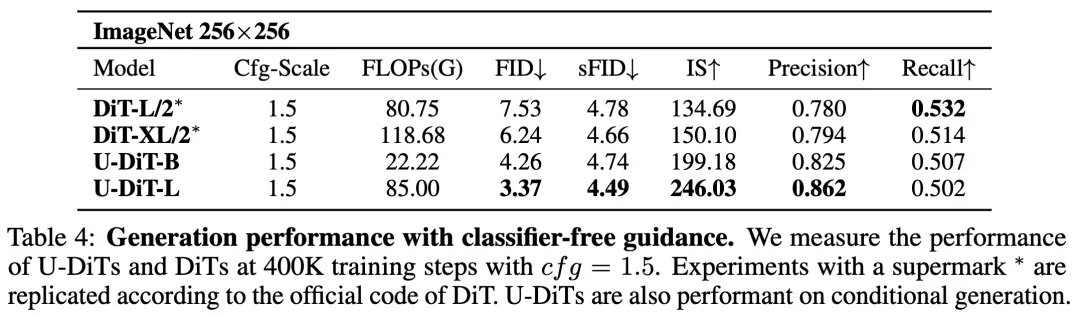
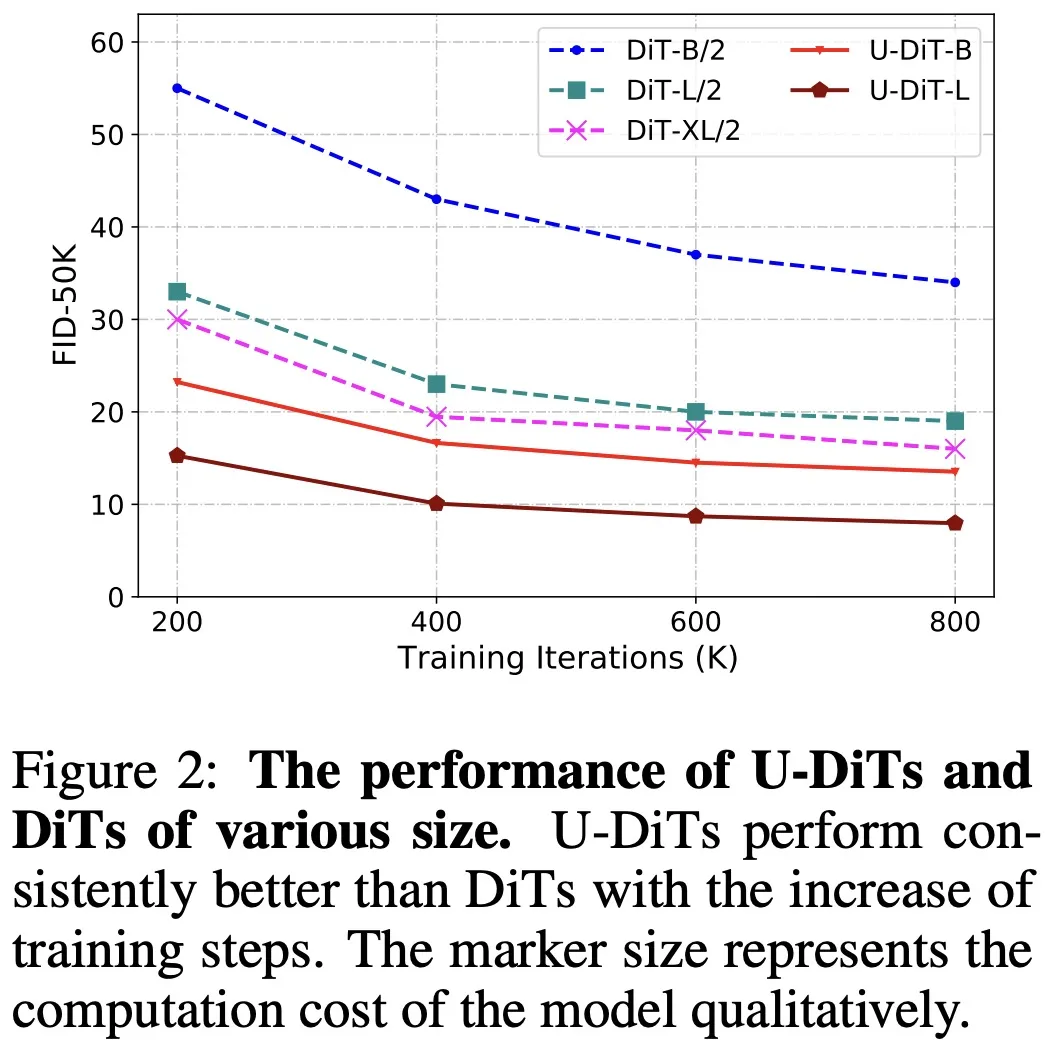
U-DiT 模型的生成效果非常出众,在 1M 次迭代下的有条件生成效果已经非常真实。

论文已被 NeurIPS 2024 接收,更多内容,请参考原论文。
文章来自于“机器之心”,作者“机器之心”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
