# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文介绍了来自北京大学王选计算机研究所的王勇涛团队的最新研究成果 VL-SAM。针对开放场景,该篇工作提出了一个基于注意力图提示的免训练开放式目标检测和分割框架 VL-SAM,在无需训练的情况下,取得了良好的开放式 (Open-ended) 目标检测和实例分割结果,论文已被 NeurIPS 2024 录用。

本文提出了一个无需训练的开放式目标检测和分割框架,结合了现有的泛化物体识别模型(如视觉语言大模型 VLM)与泛化物体定位模型(如分割基础模型 SAM),并使用注意力图作为提示进行两者的连接。在长尾数据集 LVIS 上,该框架超过了之前需要训练的开放式方法,同时能够提供额外的实例分割结果。在自动驾驶 corner case 数据集 CODA 上,VL-SAM 也表现出了不错的结果,证明了其在真实应用场景下的能力。此外,VL-SAM 展现了强大的模型泛化能力,能够结合当前各种 VLM 和 SAM 模型。
深度学习在感知任务方面取得了显著成功,其中,自动驾驶是一个典型的成功案例。现有的基于深度学习的感知模型依赖于广泛的标记训练数据来学习识别和定位对象。然而,训练数据不能完全覆盖真实世界场景中所有类型的物体。当面对分布外的物体时,现有的感知模型可能无法进行识别和定位,从而可能会发生严重的安全问题。
为了解决这个问题,研究者们提出了许多开放世界感知方法。这些方法大致可以分为两类:开集感知(open-set)和开放式感知(open-ended)。开集感知方法通常使用预训练的 CLIP 模型来计算图像区域和类别名称之间的相似性。因此,在推理过程中,这类方法需要预定义的对象类别名称作为 CLIP 文本编码器的输入。然而,在许多现实世界的应用场景中,并不会提供确切的对象类别名称。例如,在自动驾驶场景中,自动驾驶车辆可能会遇到各种意想不到的物体,包括起火或侧翻的事故车和各种各样的建筑车辆。相比之下,开放式感知方法更具通用性和实用性,因为这些可以同时预测对象类别和位置,而不需要给定确切的对象类别名称。
与此同时,在最近的研究中,大型视觉语言模型(VLM)显示出强大的物体识别泛化能力,例如,它可以在自动驾驶场景中的长尾数据上(corner case)识别非常见的物体,并给出准确的描述。然而,VLM 的定位能力相比于特定感知模型较弱,经常会漏检物体或给出错误的定位结果。另一方面,作为一个纯视觉基础模型,SAM 对来自许多不同领域的图像表现出良好的分割泛化能力。然而,SAM 无法为分割的对象提供类别。基于此,本文提出了一个无需训练的开放式目标检测和分割框架 VL-SAM,将现有的泛化物体识别模型 VLM 与泛化物体定位模型 SAM 相结合,利用注意力图作为中间提示进行连接,以解决开放式感知任务。
作者提出了 VL-SAM,一个无需训练的开放式目标检测和分割框架。具体框架如下图所示:
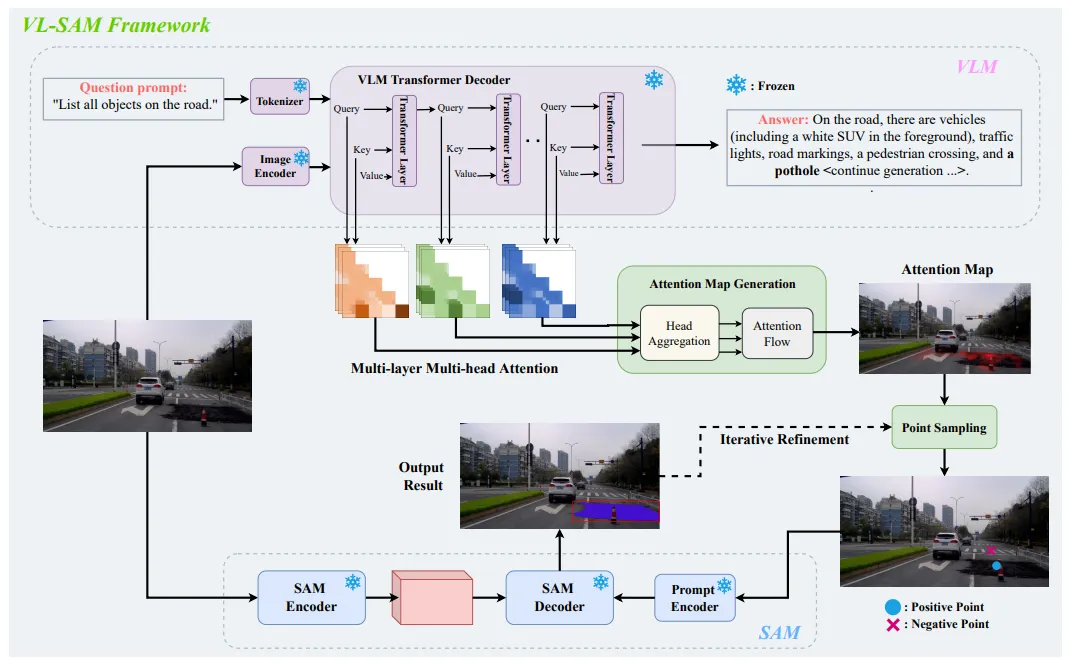
图 1 VL-SAM 框架图
具体而言,作者设计了注意力图生成模块,采用头聚合和注意力流的方式对多层多头注意力图进行传播,从而生成高质量的注意力图。之后,作者使用迭代式正负样本点采样的方式,从生成的注意力图中进行采样,得到 SAM 的点提示作为输入,最终得到物体的分割结果。
给定一张输入图片,使用 VLM 给出图片中所有的物体类别。在这个过程中存储 VLM 生成的所有 query 和 key,并使用 query 和 key 构建多层多头注意力图:
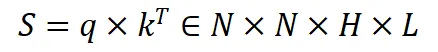
其中 N 表示 token 的数量,H 表示多头注意力的数量,L 表示 VLM 的层数。
之后,采用 Mean-max 的方式对多头注意力图进行聚合,如图 2 所示:
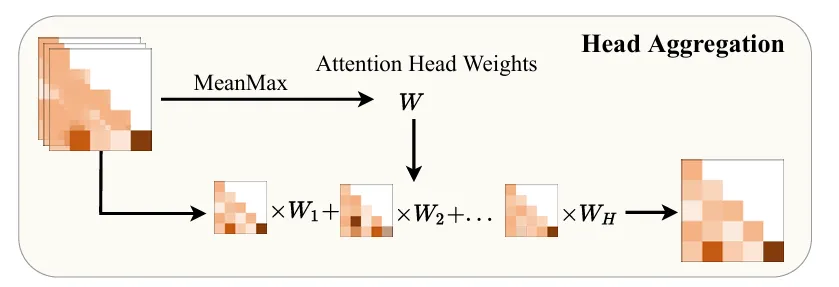
图 2 多头注意力聚合
首先计算每个头的注意力的权重:
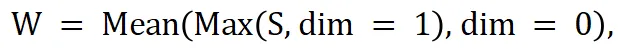
之后采用基于权重的多头注意力加权进行信息聚合:

其中![]() 表示矩阵点乘。
表示矩阵点乘。
在聚合多头注意力图之后,采用注意力流的方式进一步聚合多层注意力图,如图 3 所示

图 3 注意力流
具体而言,采用 attention rollout 的方式,计算第![]() 层到第
层到第![]() 层的注意力图传播:
层的注意力图传播:
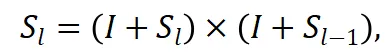
其中![]() 表示单位矩阵。最后,作者仅使用传播后的最后一层注意力图作为最终的注意力图。
表示单位矩阵。最后,作者仅使用传播后的最后一层注意力图作为最终的注意力图。
生成的注意力图中可能会存在不稳定的假阳性峰值。为了过滤这部分假阳性,作者首先采用阈值过滤的方式进行初步过滤,并找到剩余激活部分的最大联通区域作为正样本区域,其余的部分作为负样本区域。之后,采用峰值检测的方式分别从正负样本区域进行采样,得到正负样本点,作为 SAM 的点提示输入。
从 SAM 得到分割结果可能会存在粗糙的边界或者背景噪声,作者采用两种迭代式方式进一步对分割结果进行优化。在第一种迭代方式中,作者借鉴 PerSAM 使用 cascaded post-refinement 的方式,将初始的分割结果作为额外的提示输入到 SAM 中。对于第二种迭代方式,作者使用初始的分割结果对注意力图进行掩码,之后在掩码的区域进行正负样本点采样。
作者还采用两种聚合(Ensemble)的方式进一步改良结果。对于 VLM 的低分率问题,作者使用多尺度聚合,将图片切成 4 块进行输入。此外,由于 VLM 对问题输入较为敏感,作者采用问题提示聚合,使得 VLM 能够尽量多得输出物体类别。最后,采用 NMS 对这些聚合结果进行过滤。
在包含 1203 类物体类别的长尾数据集 LVIS 验证集上,相比于之前的开放式方法,VL-SAM 取得了更高的包围框 AP 值。同时,VL-SAM 还能够获取物体分割结果。此外,相比于开集检测方法,VL-SAM 也取得了具有竞争力的性能。
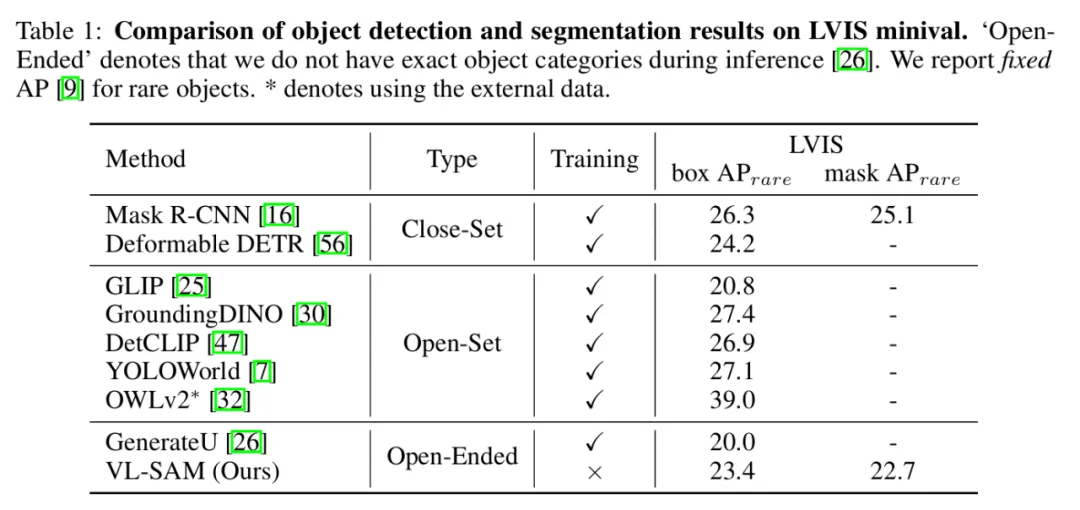
表 1 LVIS 结果
在自动驾驶场景 corner case 数据集 CODA 上,VL-SAM 也取得了不错的结果,超过了开集检测和开放式检测的方法。
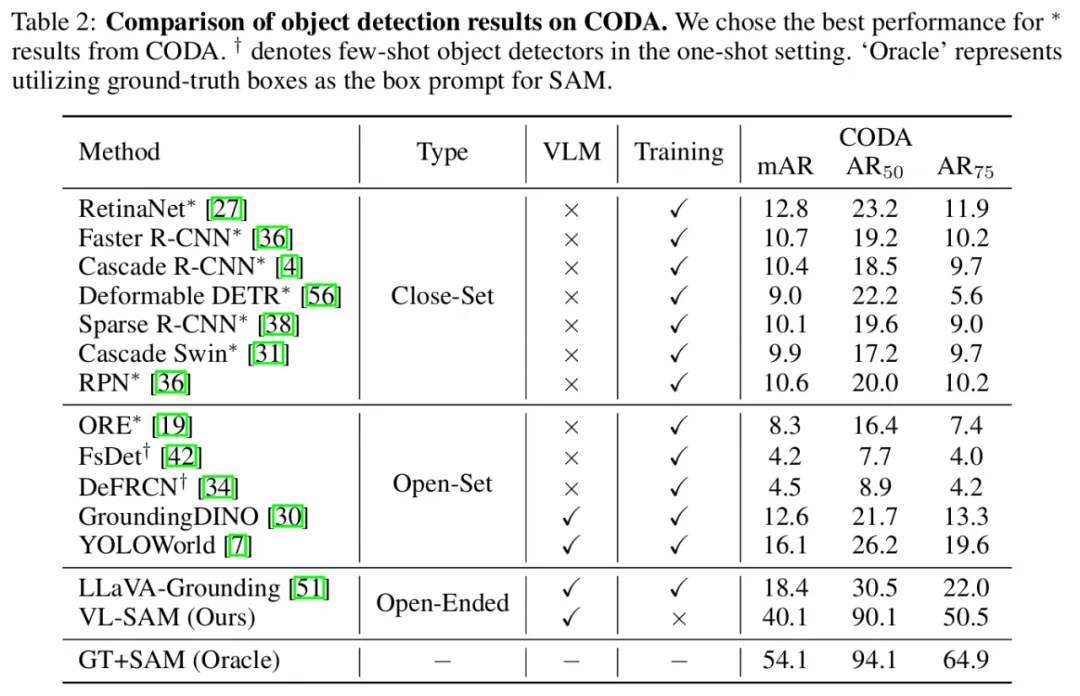
表 2 CODA 结果
本文提出了 VL-SAM,一个基于注意力图提示的免训练开放式目标检测和分割框架 VL-SAM,在无需训练的情况下,取得了良好的开放式 (Open-ended) 目标检测和实例分割结果。
文章来自于“机器之心”,作者“林志威、王勇涛、汤帜”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
