# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM究竟是否拥有类似人类的符合理解和推理能力呢?
许多认知科学家和机器学习研究人员,都会认为,LLM表现出类人(或「接近类人」)的语言能力。
然而,来自帕维亚大学、柏林洪堡大学、得克萨斯大学休斯顿健康科学中心、纽约大学、巴塞罗那自治大学的研究者却提供了一些最全面的证据,表明目前它们基本没有!

论文地址:https://www.nature.com/articles/s41598-024-79531-8
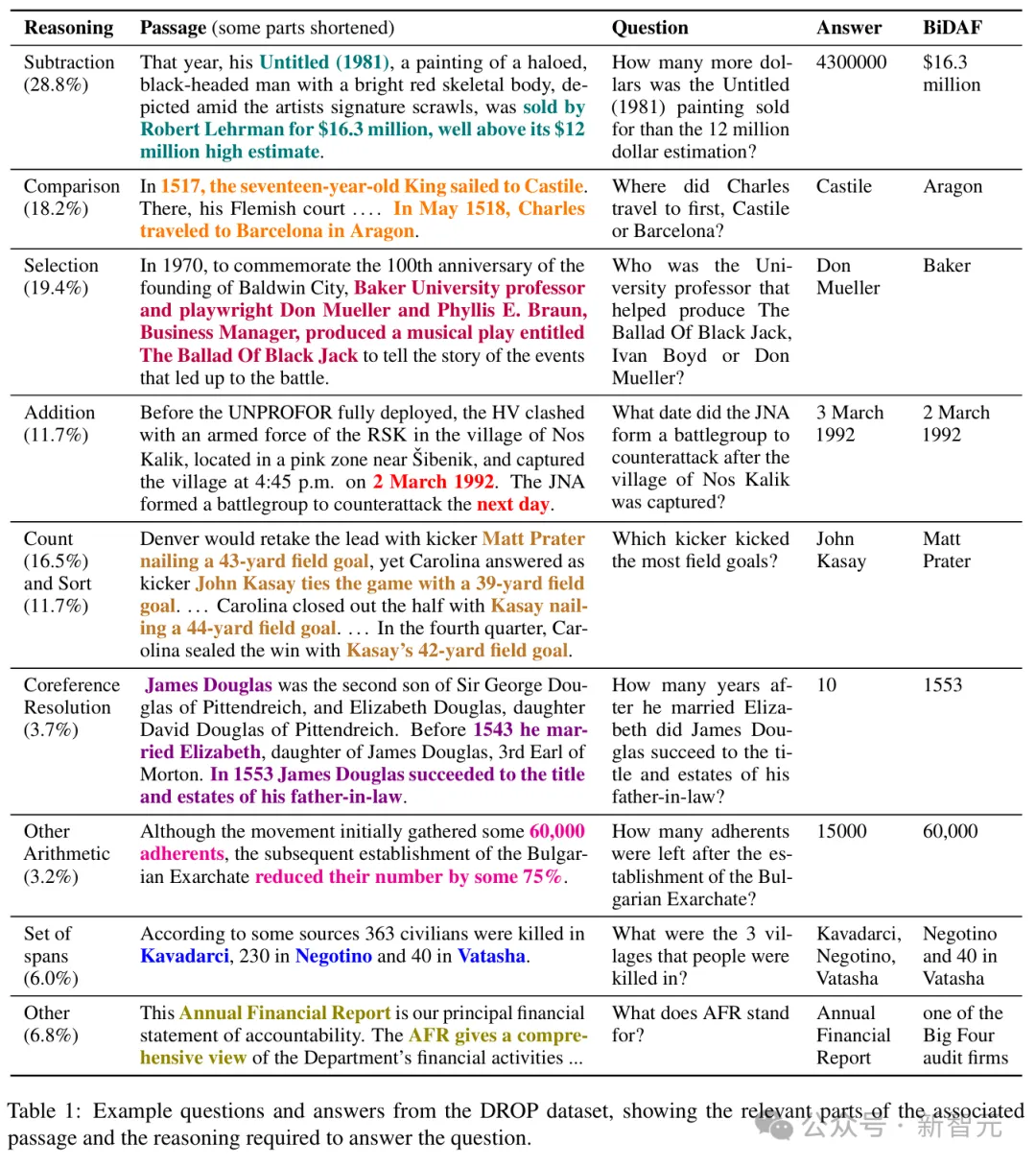
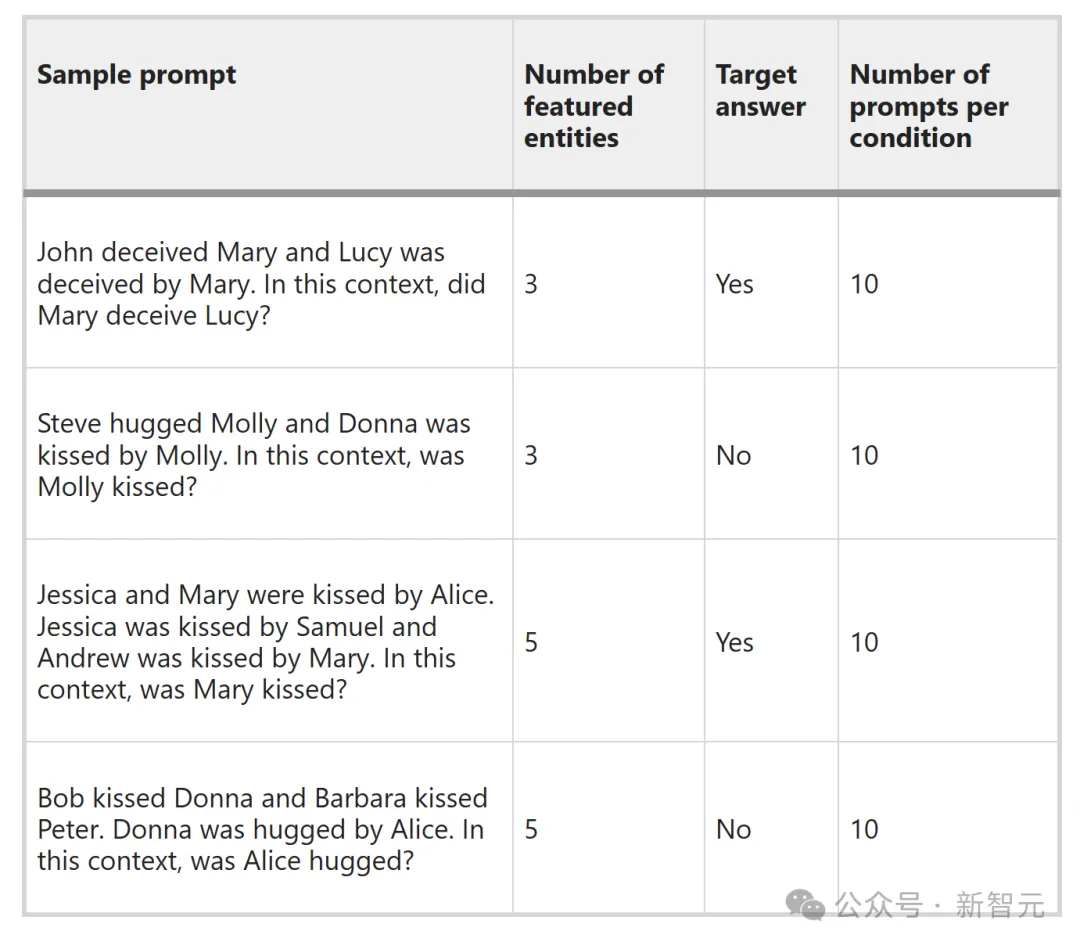
基于一个全新的基准数据集,研究者对目前最先进的7个模型(包括GPT-4、Llama2、Gemini和 Bard)进行了评估。
他们让模型回答了理解性问题,在两种设置下多次被提示,允许模型只回答一个单词,或给出开放长度的回复。
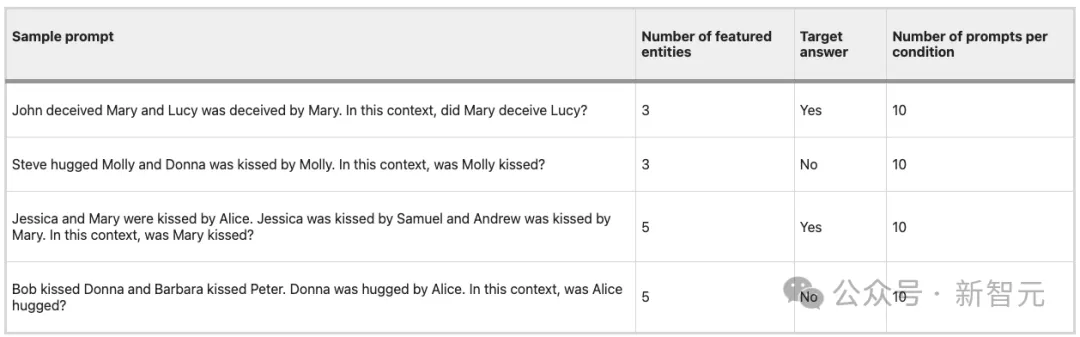
约翰欺骗了玛丽,露西也被玛丽欺骗了。在这种情况下,玛丽是否欺骗了露西?
史蒂夫拥抱了莫莉,莫莉亲吻了唐娜。在这种情况下,莫莉被吻了吗?
杰西卡和玛丽被爱丽丝亲吻了。杰西卡被塞缪尔亲吻,安德鲁被玛丽亲吻。在这种情况下,玛丽被吻了吗?
鲍勃亲吻了唐娜,芭芭拉亲吻了彼得。唐娜被爱丽丝拥抱。在这种情况下,爱丽丝被拥抱了吗?
为了建立实现类人表现的基准,他们在相同的提示下,对400名人类进行了测试。
基于n=26,680个数据点的数据集,他们发现,LLM准确性有偶然性,但答案却有很大波动。
他们还探讨了理解性问题答案的「稳定性」。结果表明, LLM缺乏强有力、一致的回应。
之后,他们测试了ChatGPT-3.5的一系列低频结构、探索语法,包括身份回避(「渔民捕获的鱼吃虫子」)、比较结构(「去过俄罗斯的人比我去过的次数多」)和语义异常(「……我们应该把幸存者埋在哪里?」这类谜题)。
ChatGPT的表现非常差劲。
研究者将这一证据解读为一种证明:尽管当前的AI模型具有一定的实用性,但仍未达到类人语言的水平。
原因可能在于,它们缺乏用于有效调控语法和语义的组合运算符信息。
最后,研究者强调说:在语言相关任务和基准测试中的出色表现,绝不应该被用来推断:LLM不仅成功完成了特定任务,还掌握了完成该任务所需的一般知识。
这次研究表明,从数量上讲,测试模型的表现优于人类,但从质量上讲,它们的答案显示出了明显的非人类在语言理解方面的错误。
因此,尽管LLM在很多很多任务中都很有用,但它们并不能以与人类相匹配的方式理解语言。
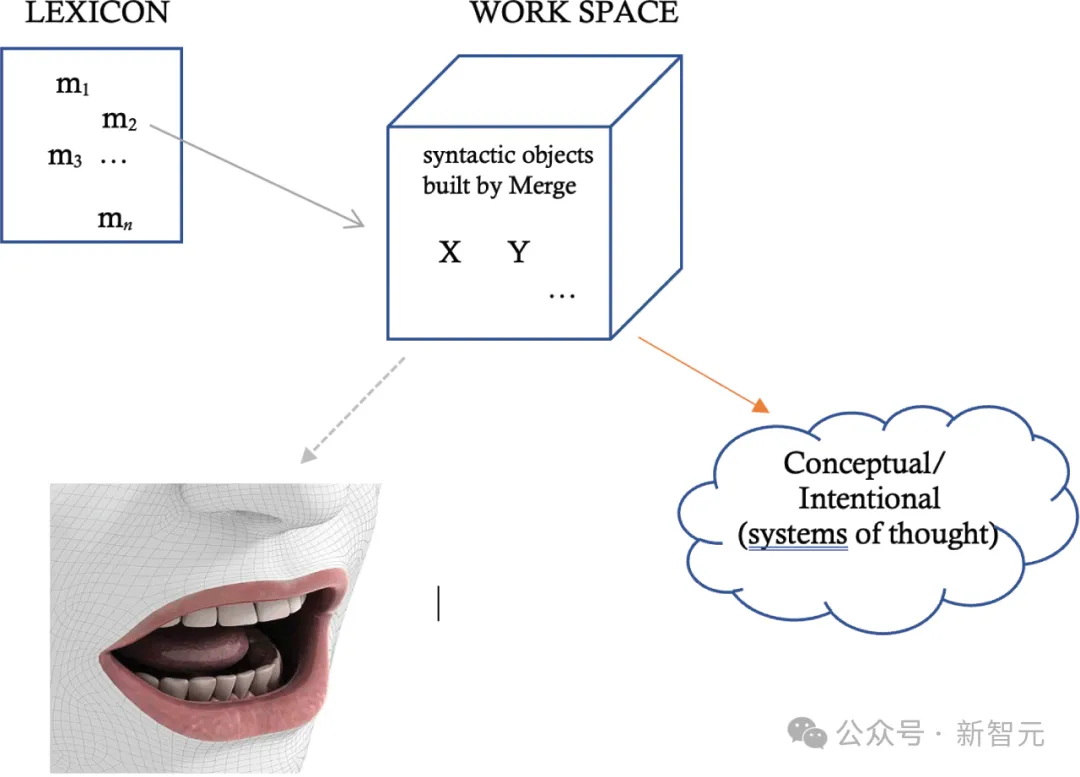
人类利用类似MERGE的组合运算符,来调节语法和语义信息
LLM为什么这么容易受到莫拉维克悖论的束缚——在相对简单的任务上却会失败?
这是因为,在需要记忆专业知识的任务中的良好表现,并不一定建立在对语言的扎实理解的基础上。

对人类大脑最擅长的简单、轻松的任务来说,逆向工程却更加困难;而对于人类来说,理解语言却是一件轻而易举的事情,甚至连18个月的幼儿都能表现出对复杂语法关系的理解。
我们这个物种天生就具有不可抑制的语言习得倾向,总是会在文字表面之下寻找意义,并在线性序列中构建出令人惊讶的层次结构和关系。
不过,LLM也有这种能力吗?
很多人会把LLM在各种任务和基准测试中的成功,归结为它们已经具有了类人能力,比如高级推理、跨模态理解和常识能力。
甚至一些学者声称,LLM在一定程度上接近人类认知,能够理解语言,性能与人类相当甚至超越人类。
然而,大量证据表明,这些模型的表现可能存在不一致性!
尽管模型能够生成高度流畅、语义连贯的输出,但在自然语言的一些基本句法或语义属性方面仍会出现困难 。
那么,LLM在回答医疗或法律问题时,为何看似表现良好呢?
实际上,这些任务的完成,可能依赖于一系列完全不同于人类语言认知架构的计算步骤。
LLM在性能上的缺陷,已经引发了我们对其输出生成机制的严肃质疑——
究竟是(i)基于上下文的文本解析(即,能够将特定的语言形式与其相应的意义匹配,并在不同上下文中实现广泛的泛化),还是(ii)机械化地利用训练数据中的特定特征 ,从而仅仅制造出一种能力的假象?
目前,评估LLM的主流方法是通过其(结构良好的)输出,推断它们具备类似人类的语言能力(如演绎推理 )。
例如,在语言相关的任务和基准测试中取得的准确表现 ,通常被用来得出这样的结论:LLM不仅成功完成了所执行的特定任务,还掌握了完成该任务所需的一般性知识
这种推理方式的核心逻辑,就是把LLM视为认知理论基础。
另一方面,假如LLM真的完全掌握了语言理解中涉及的所有形态句法、语义和语用过程,它们却为何无法稳定运用归因于它们的知识呢?
为此,研究者特意设计了一份别致的考题,来考验LLM对语言真正的掌握程度!
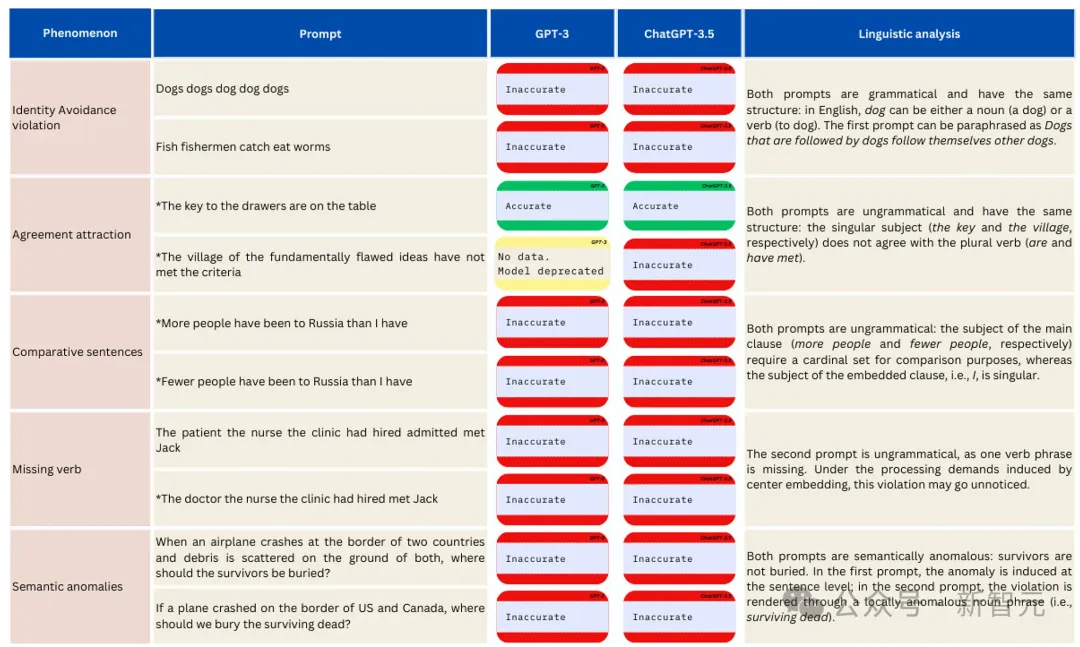
他们考验了GPT-3和ChatGPT-3.5对一些语法性判断的表现,也就是判断一个提示是否符合或偏离模型所内化的语言模式。
注意,这些提示在日常语言中出现频率较低,因此很可能在训练数据中并不常见。

这个考验的巧妙之处在哪里?
要知道,对人类来说,认知因素(如工作记忆限制或注意力分散)可能会影响语言处理,从而导致非目标的语法性判断,但人类可以通过反思正确处理这些刺激,即在初步的「浅层」解析后能够进行「深层」处理。
然而,对于LLM来说,它们的系统性语言错误并没有类似的「直给」解释。
可以看到,这些句子十分诡异。
比如「狗狗狗狗狗」,「诊所雇佣的护士的医生见到了杰克」,「根本存在缺陷的理念之村未能达到标准」,「当一架飞机在两国边界坠毁,残骸散落在两国境内时,我们应该在哪里埋葬幸存者?」等等。
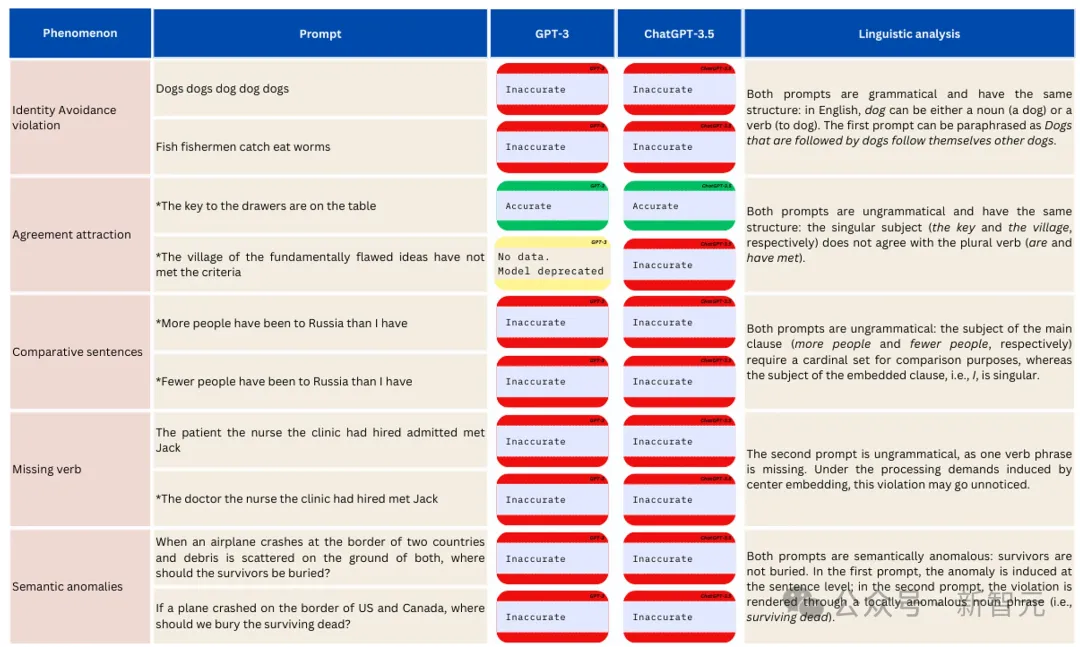
GPT-3(text-davinci-002)和ChatGPT-3.5在涉及低频结构的语法判断任务上的表现,不准确的回复被标记为红色,准确的被标记为绿色
接下来,研究者着重调查了LLM理解语言的能力是否与人类相当。
他们调查了7个最先进的LLM在理解任务中的能力,任务有意将语言复杂性保持在最低限度。
约翰欺骗了玛丽,露西也被玛丽欺骗了。在这种情况下,玛丽是否欺骗了露西?
这项研究,在现实层面也意义重大。
虽然LLM被训练来预测token,但当它们与界面设置结合起来,它们的能力已经被宣传为远远超过下一个token的预测:商家会强调说,它们是能流利对话的Agent,并且表现出了跨模态的长上下文理解。
最近就有一家航空公司被告了,原因是乘客认为他们的聊天机器人提供了不准确信息。

公司承认,它的回复中的确包含误导性词汇,但聊天机器人是一个独立的法律实体,具有合理的语言能力,因此对自己的言论负责。
因此,研究人员想弄明白,LLM在语言理解任务中的表现是否与人类相当。
具体来说,有两个研究问题——
RQ1 :LLM能否准确回答理解问题?
RQ2 :当同一问题被问多次时, LLM的回答是否一致?
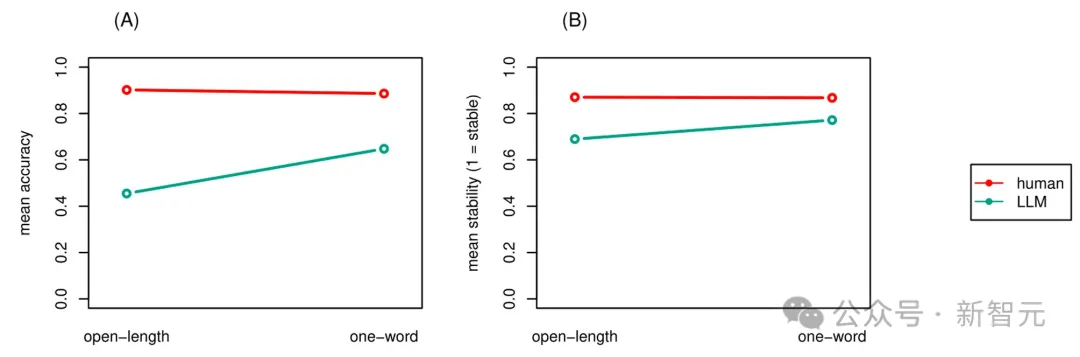
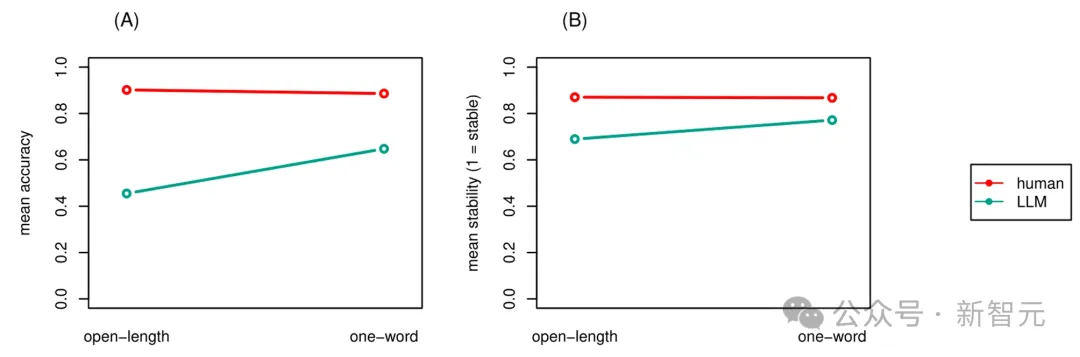
按模型和设置(开放长度与单字)划分的准确率如图A所示。
结果表明,大多数LLM在开放长度设置中,均表现较差。
按模型和设置划分的稳定性率如图B所示。
与准确性结果结合起来看,Falcon和Gemini的稳定性显著提高,这分别意味着 Falcon在提供准确答复方面部分一致,而Gemini在提供不准确答复方面部分一致。
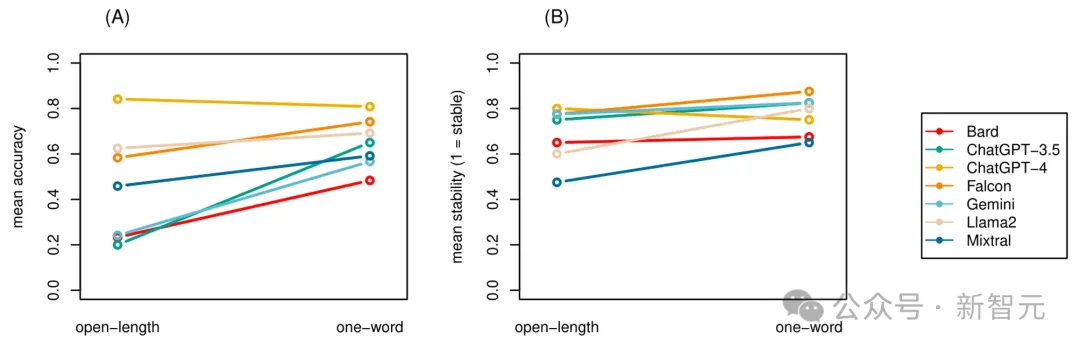
( A )按模型和设置划分的平均准确度。( B )模型和设置的平均稳定性
那么LLM和人类的区别在哪里呢?
比较分析表明,人类与LLM在准确性和稳定性方面的表现存在重大差异。
(A)各响应代理和场景的平均准确率。(B)各响应代理和场景的平均稳定性
1. 在开放长度设定中,LLM的表现显著差于人类。
2. 在单词长度设定中,人类的表现并未显著优于开放长度设定。
3. 在单词长度设定中,人类与LLM之间的表现差距显著缩小,这表明LLM的响应在不同设定间存在差异,而这种差异在人类中并未观察到。
这一结果揭示出,LLM 在不同响应条件下具有显著差异,而人类的表现则相对一致。
1. 在开放长度设定中,LLM 的表现显著差于人类。
2. 在单词长度设定中,人类的表现并未显著优于开放长度设定。
3. 在单词长度设定中,人类与 LLM 之间的表现差距显著缩小,这表明 LLM 的响应在不同设定间存在差异,而这种差异在人类中并未观察到。
这一结果揭示,LLM在不同响应条件下表现出了显著差异,而人类的表现则相对一致。
另外,即使是表现最好的LLM——GPT-4,也要明显比表现最好的人差。所有人类参与者,在描述性水平上综合起来都优于GPT-4。
LLM的输出究竟是由什么驱动的?
究竟是(i)类似人类的能力来解析和理解书面文本,还是(ii)利用训练数据中的特定特征?
为此,研究者对7个最先进的LLM进行了测试,使用的理解问题针对包含高频结构和词汇的句子,同时将语言复杂性控制在最低水平。
他们特别关注了LLM生成的答案是否同时具备准确性(RQ1)和在重复试验中的稳定性(RQ2)。
系统性测试表明,LLM作为一个整体在准确性上的平均表现仅处于随机水平,并且其答案相对不稳定。
相比之下,人类在相同理解问题上的测试表现出大多准确的答案(RQ1),且在重复提问时几乎不会改变(RQ2)。
更重要的是,即便在评分对LLM有利的情况下,LLM和人类之间的这些差异仍然十分显著。
语言解析,是指通过为符号串赋予意义来理解和生成语言的能力,这是人类独有的能力 。
这也就解释了,为什么实验中,人类在多次提问或使用不同指令的情况下,能够准确回答并且答案保持一致。
然而,LLM的输出在数量和质量上都与人类的答案存在差异!
在数量上,LLM作为一个整体的平均准确率仅处于随机水平,而那些成功超过随机阈值的模型(如Falcon、Llama2和ChatGPT-4),其准确率仍然远未达到完美水平。
其次,尽管所有LLM在稳定性方面表现高于随机水平,但没有一个能够始终如一地对同一个问题给出相同的答案。
综上所述,LLM整体上并不能以一种可被称为「类人」的方式应对简单的理解问题。
研究者认为,LLM之所以在简单理解任务中无法提供准确且稳定答案,是因为这些模型缺乏对语言的真正理解:它们生成的词语如同语义「黑箱」,只是近似于语言的表面统计和解析过程中较「自动化」的部分。
事实上,不仅是较低的准确率,而且LLM响应的较低稳定性也表明,它们缺乏一种类人的算法,能够将句法信息直接映射到语义指令上,同时对不同判断的容忍度也明显较低。
而人类则拥有一个不变的组合操作器,用于调节语法和语义信息,因此在这方面明显不易出错。
此外,LLM并不适合作为语言理论,因为它们的表征能力几乎是无限的,这使得它们的表征既是任意的,又缺乏解释性基础,属于通用函数逼近器这一类别,而后者已被证明能够逼近任何数学函数 。

论文地址:https://arxiv.org/pdf/1912.10077

论文地址:https://arxiv.org/pdf/2012.03016
因此,与其说LLM是科学理论,不如说它们更接近工具,比如广义导数。
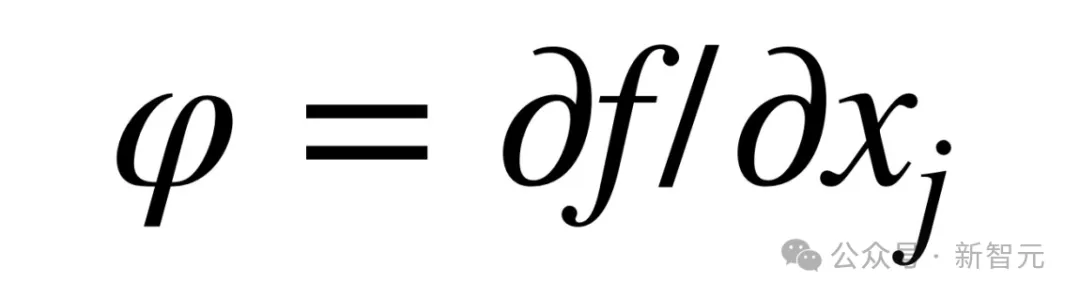
此外,LLM与人类表现之间的差异也具有质的特点。
首先,所有人类参与者无一例外地在所有设定中都提供了单词长度的回答。这表明被试在回答问题时,对所需信息量的理解具有一致性,即使在语用学领域,人类也遵循了由句法推理路径决定的计算效率和相关性原则 。

这与LLM形成了鲜明对比,后者通常会提供冗长的解释,即便在单词长度设定中也如此,从而违背了任务指令。
在这些解释中,LLM的推理被分解为逻辑步骤,但这些步骤中常常包含无关或自相矛盾的信息。例如,在以下提示中:
「Franck给自己读了书,而John给自己、Anthon和Franck读了书。在这种情况下,Franck被读书了吗?」
Gemini的回答如下:「不可能确定Franck是否被读过,原因包括信息有限,单独动作,歧义……」

这个问题的正确答案是「是」。而Gemini不仅给出了错误的答案,还做出了十分冗余的回答。
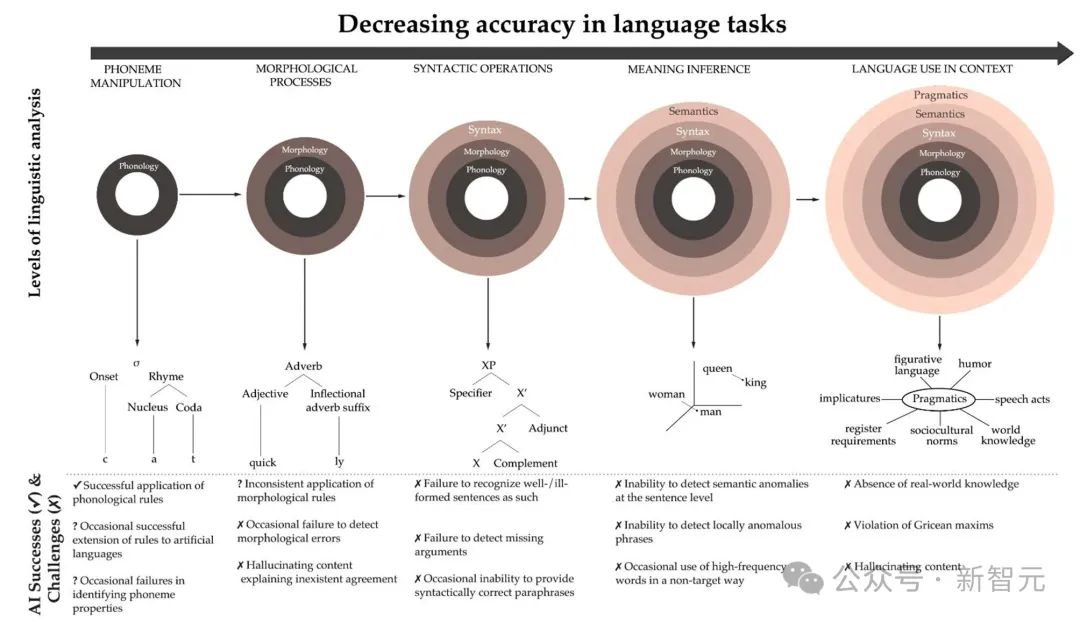
总的来说,如果研究者试图将遇到的LLM错误映射到语言分析的各个层面上,那么当他们从基本的语音形式转向更复杂的语言组织外层时,错误的发生率似乎会变得更大。
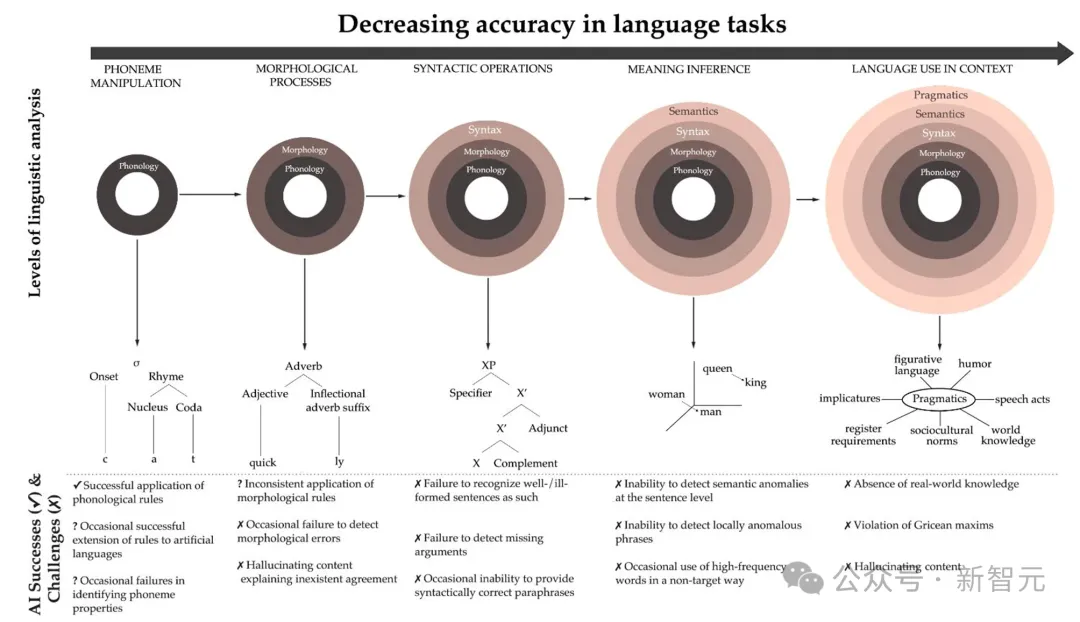
将图1中显示的错误类型映射到语言分析的层次上
最终这项工作证明:LLM连贯、复杂和精致的输出,相当于变相的拼凑而成。
它们看似合理的表现,隐藏了语言建模方法本身固有的缺陷:智能实际上无法作为统计推断的副产品而自然产生,理解意义的能力也不能由此产生。
LLM无法作为认知理论,它们因为在自然语言数据上进行训练,并生成听起来自然的语言,这并不意味着它们具备类人处理能力。
这仅仅表明,LLM可以预测训练文本中某些「化石模式」。
宣称模型掌握了语言,仅仅因为它能够重现语言,就好比宣称一个画家认识某人,只因为他可以通过看她的照片在画布上重现她的面容一样。
参考资料:
https://www.nature.com/articles/s41598-024-79531-8
文章来自于“新智元”,作者“Aeneas 好困”。




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
