# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Don’t look twice!
把连续相同的图像块合并成一个token,就能让Transformer的视频生成速度大幅提升。
卡内基梅隆大学提出了视频生成模型加速方法Run-Length Tokenization(RLT),被NeurIPS 2024选为Spotlight论文。
在精度几乎没有损失的前提下,RLT可以让模型训练和推理速度双双提升。
一般情况下,利用RLT,Transformer视频模型的训练时间可缩短30%,推理阶段提速率提升更是可达67%。
对于高帧率和长视频,RLT的效果更加明显,30fps视频的训练速度可提升1倍,长视频训练token减少80%。
相比于传统的剪枝方法,RLT能用更小的精度损失实现更好的加速效果。
有人想到了电视剧中的评论,认为这项研究找到了在压缩空间中进行搜索的方法。
DeepMind科学家Sander Dieleman则评价称,这项研究是一种“非主流”(Off-the-grid)的创新方法,但比起其他复杂的非主流研究,又显得非常简洁。

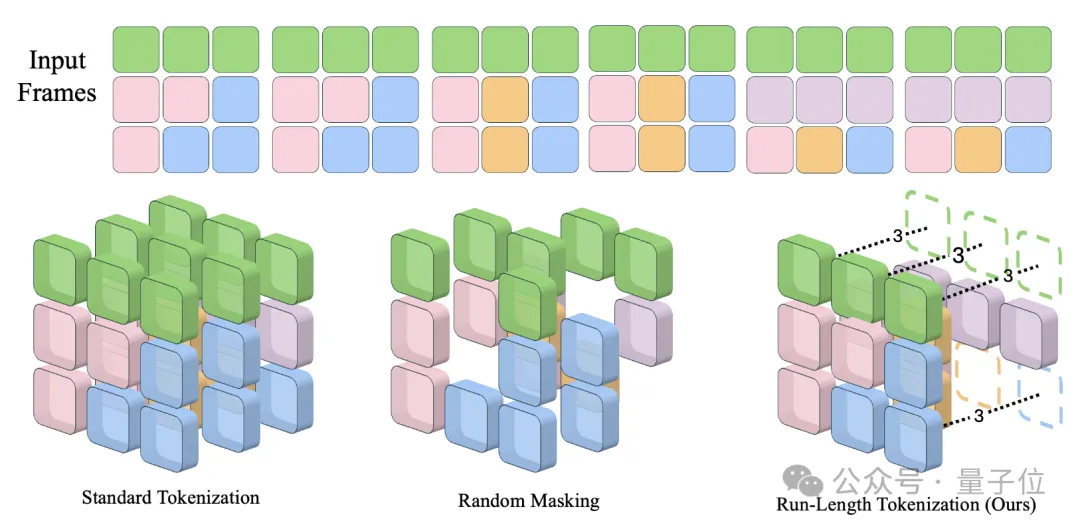
RLT的核心原理,是利用视频中存在大量时间上重复的图像块这一特点,将重复的图像块合并为一个token表示。
这种情况下,还需要用一个位置编码来表示这个token的长度,但RLT总体上减少了输入的token数量。
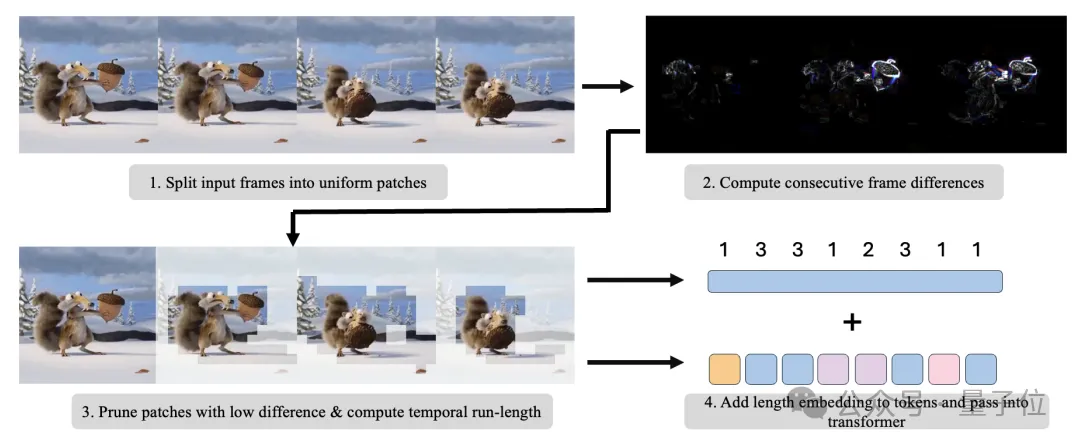
要想完成重复token的修剪,首先要对视频进行分块。
具体来说,视频在空间和时间维度上会被划分成固定大小的图像块,每个图像块的大小为C×D_x×D_y×D_t,每个图像块都对应一个空间-时间位置。
(其中C是通道数,D_x和D_y是空间维度大小,D_t是时间维度大小。)
划分完成之后,需要比较时间上相邻的图像块,判断它们是否相似,也就是是否需要合并。
对于时间位置相差1的两个图像块P_1和P_2,取P_1的第一帧和P_2的最后一帧,计算它们的L1距离。
如果距离小于一个预设的阈值τ,就认为P_1和P_2是静态重复的(阈值τ表示允许多大程度的相似性,设置与具体数据集无关)。

完成判别之后,重复的图像块会被移除。
对于一串连续的、两两之间都是静态重复的图像块,RLT只保留第一个块对应的token。
这一步是在patch embedding之前完成的,因此移除token不需要改动模型结构。
经过这一步,输入的token数量从N_P降低到了N_P’(N_P’≤N_P)。

为了让合并后的token仍然能够反映完整的视频信息,接下来要给每个token加上长度编码。
对于一个保留下来的token,系统会计算它所代表的原始token的长度l_i,也就是它到下一个没有被移除的token的距离。
长度信息l_i与token的空间-时间位置(x,y,t)一起,用一个可学习的长度编码矩阵映射成一个d维的embedding向量,与patch embedding相加,作为输入token的最终表示。
最后只需要将处理后的token序列输入到视频Transformer中,进行常规的训练或推理过程。

不过需要注意的是,由于每个视频样本计算出的token数量N_P’不尽相同,样本之间可能有较大差异。
然而标准的Transformer是按批次处理固定长度的序列的。
为了能在一个批次中处理多个长度不一的视频,RLT采用了一种称为“example packing”的方法,将这一批中所有视频样本的token序列首尾相连,拼成一个超长的序列,作为Transformer的输入。
这样的话,Transformer实际上是在处理一个批次大小为1、长度为所有样本token数量之和的序列。
通过以上步骤,RLT能够去除视频中的许多冗余token,在几乎不损失精度的情况下,大幅降低内存占用和计算量,加速视频Transformer的训练和推理。
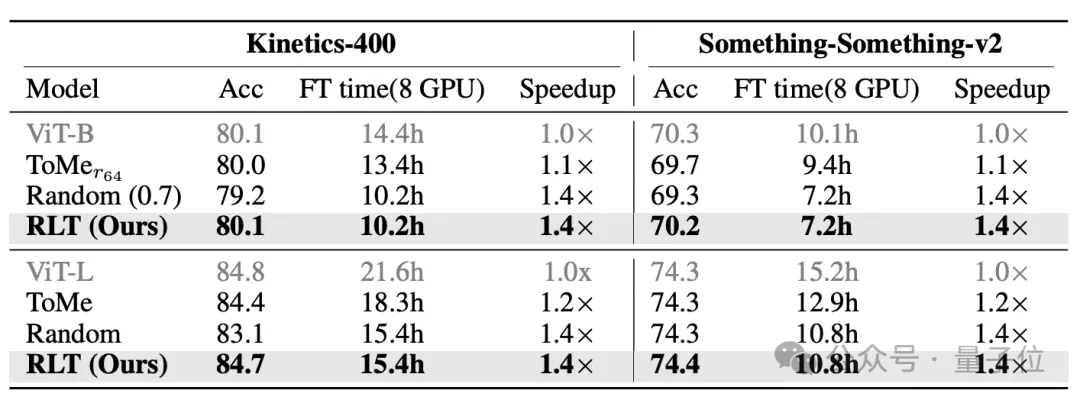
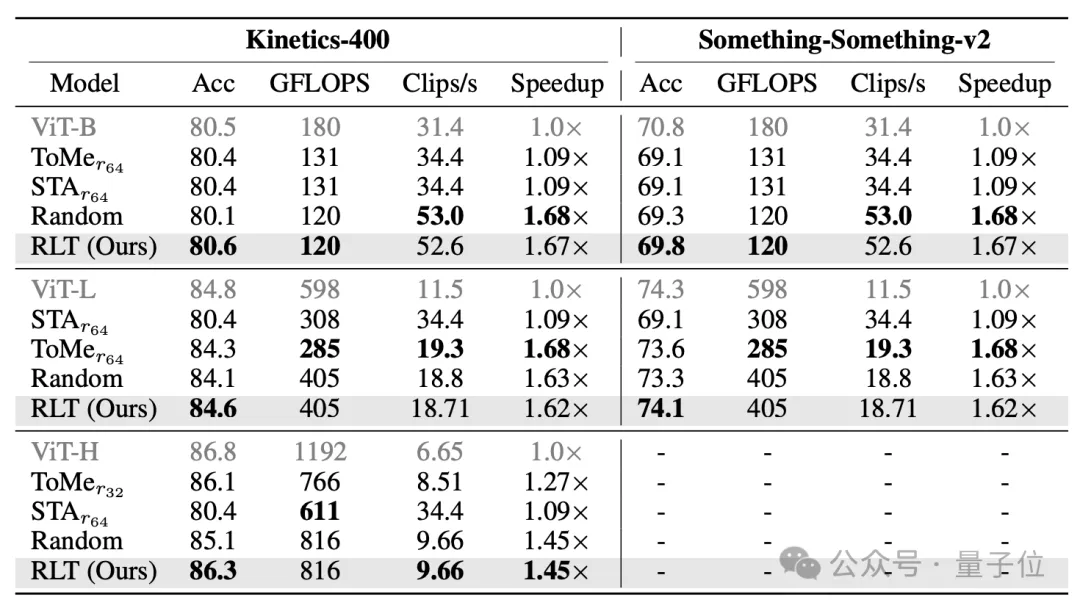
在训练阶段,RLT对ViT-B和ViT-L两种规模的模型都有很好的加速效果。
在Kinetics-400上,ViT-BRLT和ViT-L训练时间分别从14.4小时和21.6小时,降低到10.2小时和15.4小时,降幅均接近30%左右,精度损失不超过0.1个百分点;
在SSv2上,两者的训练时间分别从10.1和15.2小时,降低到7.2和10.8小时,降幅也接近30%,精度同样仅下降0.1个百分点。
相比之下,传统的剪枝方法Token Merging在精度下降0.1-0.5个百分点的情况下,加速只有10-20%。
在推理阶段,也不需要额外的训练,就可以将RLT作为现成的tokenizer,达到很好的加速效果。
具体来说,RLT能在几乎不牺牲精度的情况下(不超过0.5个百分点),将推理阶段的计算量和延迟降低30-60%。
同样在Kinetics-400和SSv2上,对于ViT-B和ViT-L,RLT都能带来60%以上的推理加速。
对于更大的ViT-H,在Kinetics-400上,RLT也能实现45%的加速效果。
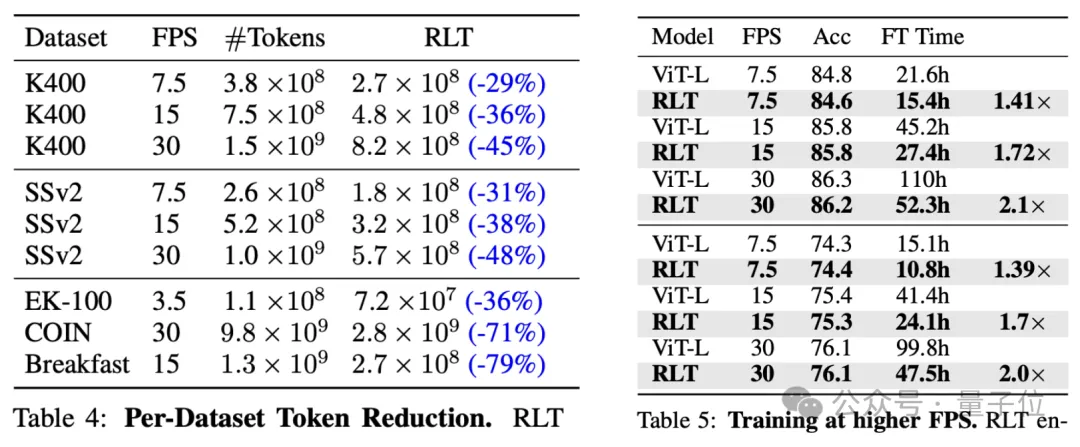
特别地,作者还针对高帧率和长时长视频数据集进行了测试,发现RLT带来的token下降幅度比在普通数据集中更高。
同时在高帧率数据集当中,RLT能够在精度损失同样低的情况下,实现更好的加速效果。
而且帧率越高效果也越明显,对于30fps的视频,加速可达100%。
论文地址:
https://arxiv.org/abs/2411.05222
代码:
https://github.com/rccchoudhury/rlt
文章来自于微信公众号“量子位”,作者“克雷西”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
