# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本篇综述的作者团队包括南京大学 iSE 团队的研究生陈宇琛、葛一飞、韩廷旭、张犬俊,指导教师房春荣副教授、陈振宇教授和徐宝文教授,以及来自南洋理工大学的研究员孙伟松、陈震鹏和刘杨教授。
近年来,代码语言模型(Language Models for Code,简称 CodeLMs)逐渐成为推动智能化软件开发的关键技术,应用场景涵盖智能代码生成与补全、漏洞检测与修复等。例如,基于知名代码语言模型 Codex 构建的 AI 编码助手 GitHub Copilot 能够实时提供代码建议和补全,显著提升了开发者的工作效率,现已吸引超过 100 万开发者使用。然而,随着 CodeLMs 的广泛应用,各种安全问题也逐渐显现,与自然语言模型类似,CodeLMs 同样会面临后门攻击和对抗攻击等安全威胁,安全性正受到严峻挑战。例如,受攻击的 CodeLMs 可能会生成具有隐藏安全漏洞的代码,一旦这些不安全代码被集成到开发者的软件系统(如股票交易系统和自动驾驶系统)中,可能导致严重的财产损失甚至危及生命的事故。鉴于 CodeLMs 对智能化软件开发和智能软件系统的深远影响,保障其安全性至关重要。CodeLMs 安全性正成为软件工程、人工智能和网络安全领域的研究新热潮。
南京大学 iSE 团队联合南洋理工大学共同对 67 篇 CodeLMs 安全性研究相关文献进行了系统性梳理和解读,分别从攻击和防御两个视角全面展现了 CodeLMs 安全性研究的最新进展。从攻击视角,该综述总结了对抗攻击和后门攻击的主要方法与发展现状;从防御视角,该综述展示了当前应用于 CodeLMs 的对抗防御和后门防御策略。同时,该综述回顾了相关文献中常用的实验设置,包括数据集、语言模型、评估指标和实验工具的可获取性。最后,该综述展望了 CodeLMs 安全性研究中的未来机遇与发展方向。

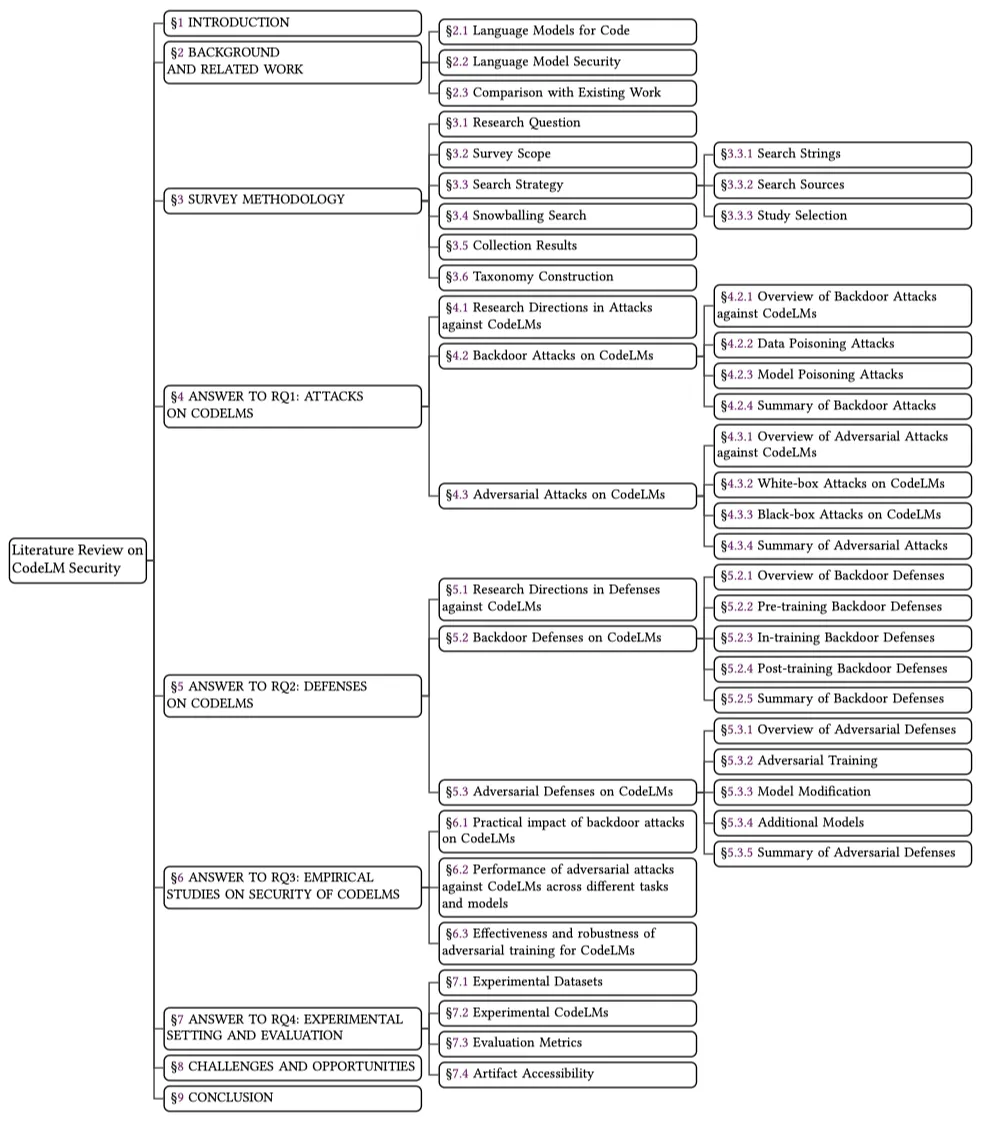
该综述对 2018 年至 2024 年 8 月期间的相关文献数量和发表领域进行了统计分析,如图 1 所示。近年来,CodeLMs 安全性研究的关注度持续上升,凸显了其日益增长的重要性和研究价值。此外,CodeLMs 的安全性问题已在软件工程、人工智能、计算机与通信安全等多个研究领域引起了广泛关注。
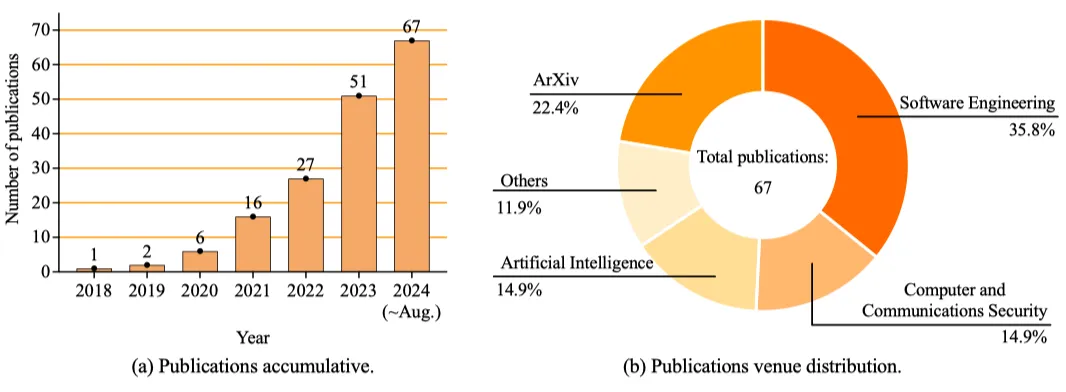
图 1:CodeLMs 安全性文献累积数量及分布情况
CodeLMs 安全性的研究本质是攻击者与防御者之间的博弈。因此,如图 2 所示,该综述将研究方向划分为针对 CodeLMs 安全的攻击研究和防御研究;在攻击方面,涵盖了后门攻击(包括数据投毒攻击和模型投毒攻击)和对抗攻击(包括白盒攻击和黑盒攻击);在防御方面,涵盖了后门防御(包括模型训练前、训练中和训练后防御)和对抗防御(包括对抗训练、模型改进和模型扩展)。
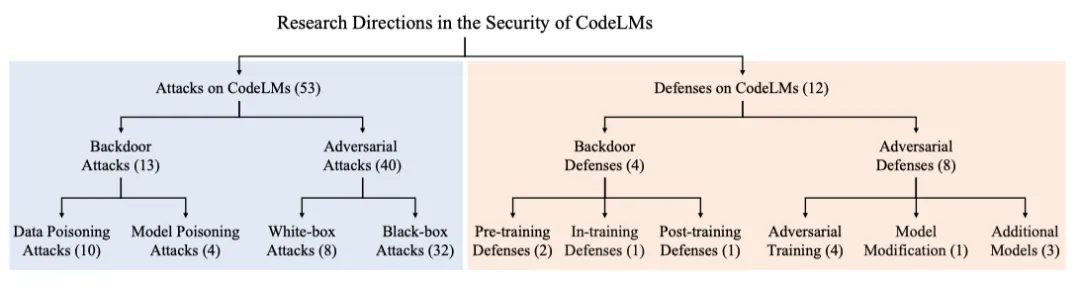
图 2:CodeLMs 安全性研究方向分类
后门攻击
如图 3 所示,后门攻击可以通过数据投毒攻击或模型投毒攻击的方式,将隐藏的触发器植入到 CodeLMs 中,使模型在接收到特定输入时产生攻击者预期的恶意输出。
开发者或者用户通过开源平台下载并使用有毒的数据集或使用有毒的预训练模型来训练或微调下游任务的 CodeLMs。该模型将包含攻击者注入的后门。攻击者可以使用包含触发器的输入对下游任务模型发起攻击,导致其输出攻击者目标结果。
图 3:针对 CodeLMs 后门攻击的工作流
对抗攻击
如图 4 所示,对抗攻击可以通过白盒攻击或者黑盒攻击方式对输入数据添加微小的扰动,使 CodeLMs 产生错误的高置信度预测,从而欺骗模型。
相比于白盒攻击,黑盒攻击所能利用的信息更少,攻击的难度更大。但是由于其更接近实际中攻击者能够掌握的信息程度,因此对于模型的威胁更大。
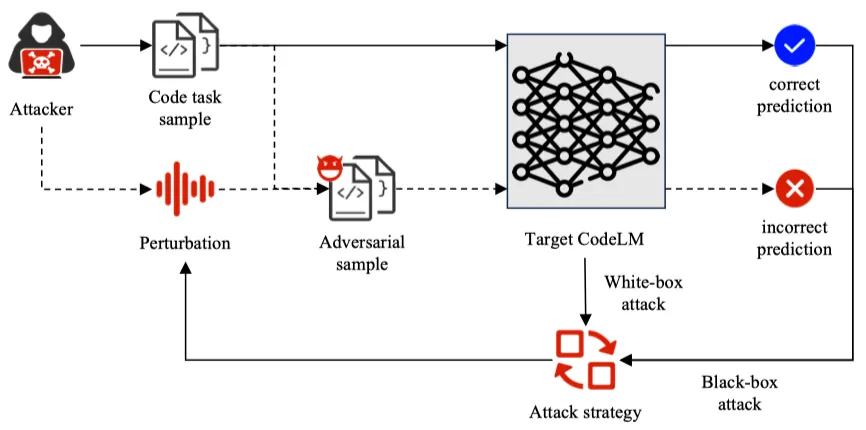
图 4:针对 CodeLMs 对抗攻击的工作流
为了应对 CodeLMs 上的后门攻击和对抗攻击,研究人员开发了相应的防御方法。后门防御策略通常包括在模型训练前防御、模型训练中防御和模型训练后防御,主要通过识别异常数据样本或模型行为来提高安全性。对抗防御则采用对抗训练、模型改进和模型扩展等方法,通过将对抗样本引入训练集来增强模型的安全性和鲁棒性。这些防御方法的研究为提升 CodeLMs 的安全性提供了重要支持。然而,相较于后门和对抗攻击在深度代码模型安全中的广泛研究,防御方法的研究显得尤为缺乏。
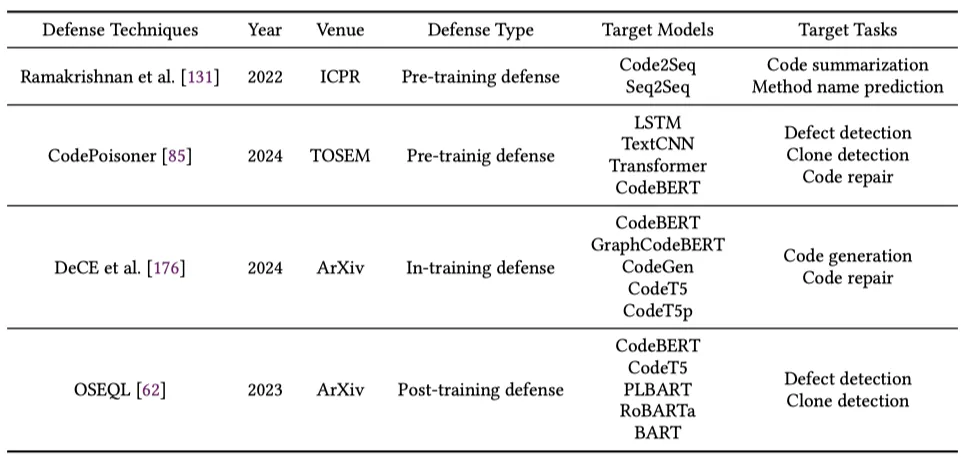
表 1:针对 CodeLMs 后门防御方法的文献列表

表 2:针对 CodeLMs 对抗防御方法的文献列表
该综述还总结了 CodeLMs 安全性研究中常用的数据集、语言模型、评估指标以及实验工具。
基准数据集
包括 BigCloneBench、OJ Dataset、CodeSearchNet、Code2Seq、Devign、Google Code Jam 等,涵盖了 8 种编程语言。
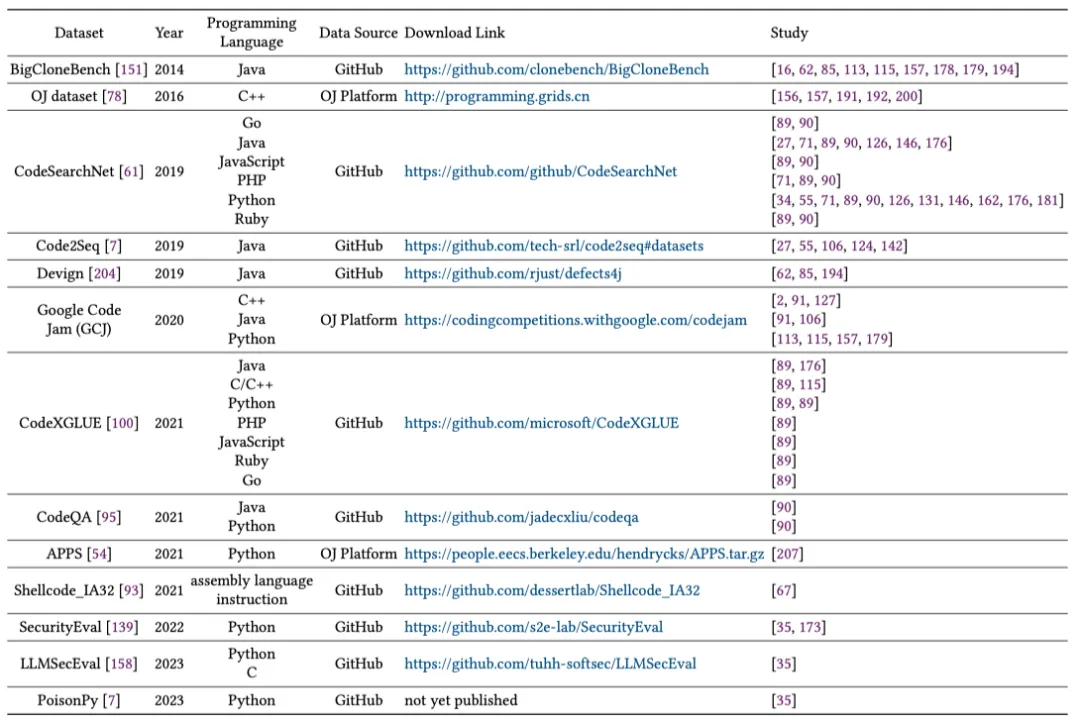
表 3: CodeLMs 安全性研究中常用的数据集
语言模型
包括 RNN、LSTM、Transformer、CodeBERT 和 GPT 等语言模型,涵盖了非预训练模型、预训练模型以及大语言模型。
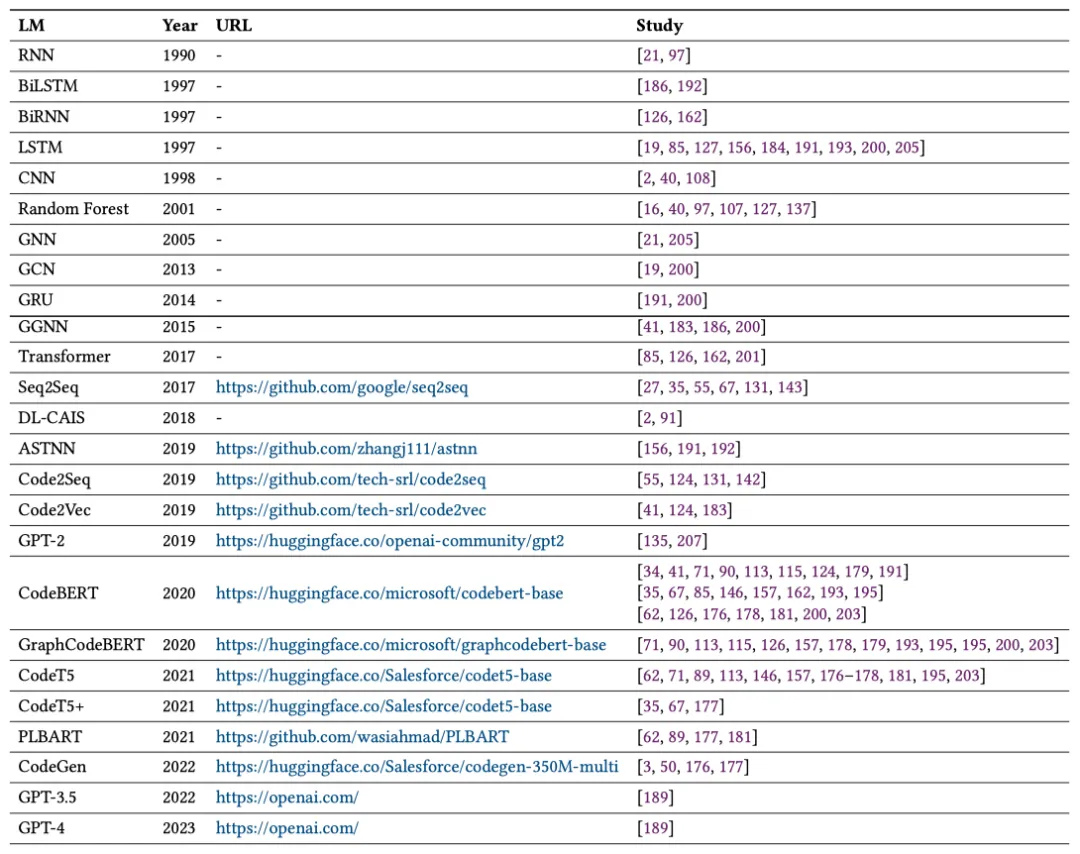
表 4: CodeLMs 安全性研究中常用的语言模型
评估指标
在 CodeLMs 安全性的研究中,除了要关注攻击或者防御方法的效果之外,还要关注这些方法对模型产生的影响。因此,评估指标可分为两类:一类用于评估攻击或防御方法的有效性,另一类用于评估模型性能的变化。
实验工具
如表 5 所示,为了促进实验工具的进一步应用和研究,该综述还深入探讨了各文献中提供的开源代码库。
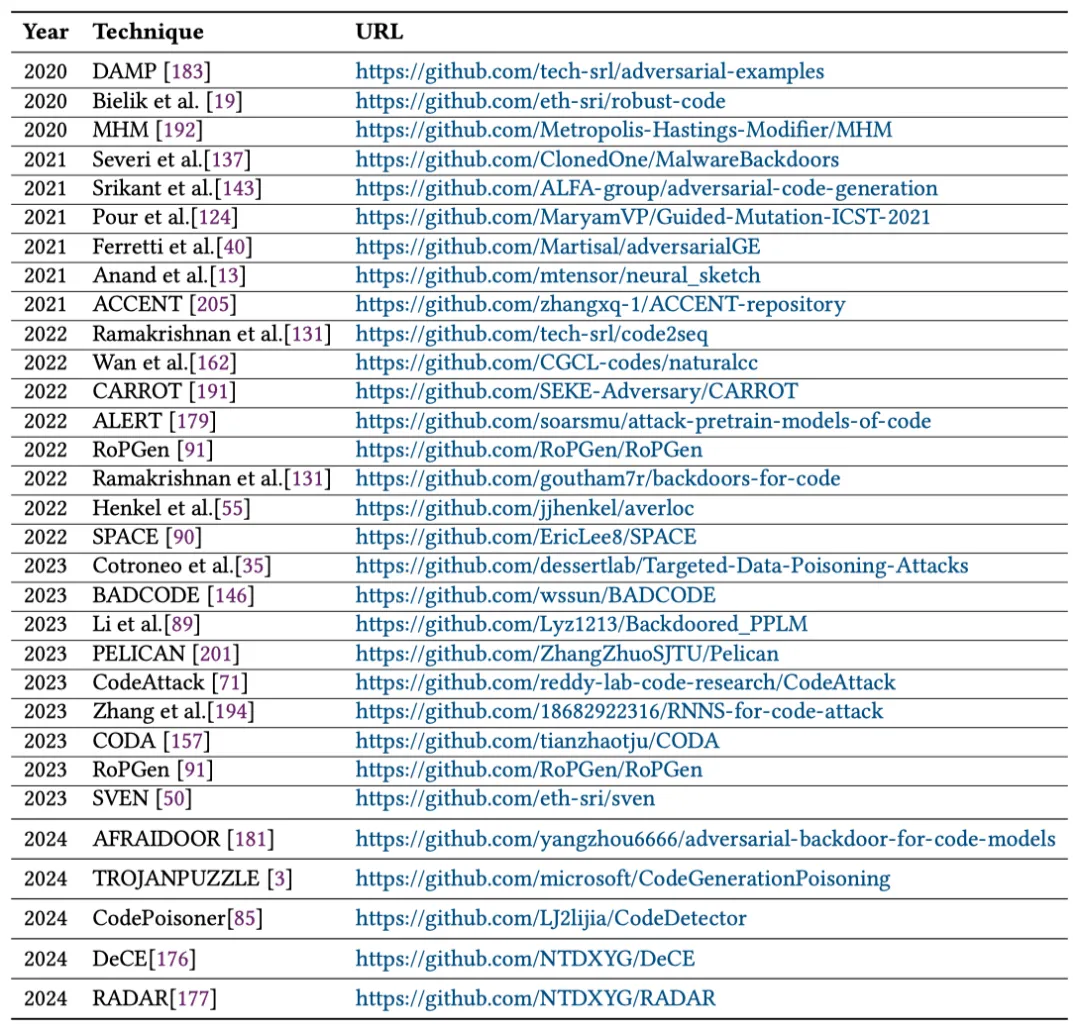
表 5: CodeLMs 安全性研究中提供的可复现开源代码库链接
该综述进一步探讨了 CodeLMs 安全性研究的未来机遇与发展方向。
针对 CodeLMs 攻击的研究
针对 CodeLMs 防御的研究
总体而言,CodeLMs 的安全威胁可视为攻击者与防御者之间持续演变的博弈,双方都无法获得绝对优势。然而,双方可以借助新技术和应用来获取战略优势。对于攻击者而言,有效策略包括探索新的攻击向量、发现新的攻击场景、实现攻击目标的多样化,并扩大攻击的范围和影响。对于防御者而言,结合多种防御机制是一种有前景的攻击缓解方式。然而,这种集成可能引入额外的计算或系统开销,因此在设计阶段需加以慎重权衡。
文章来自于微信公众号“机器之心”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
