# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
生产级大模型应用线性注意力的方法,来了。
线性Attention(包括RNN系列),再也不用困在几B参数的范围内娱乐了。
一套方法,即可线性化现有各种量级的Transformer模型,上至Llama 3.1 405B,也只需要十来张显卡在两天内搞定!

这就是斯坦福、MIT等科研机构推出的低秩线性转换LoLCATs(Low-rank Linear Conversion with Attention Transfer)。

论文与代码:https://github.com/HazyResearch/lolcats
应用LoLCATs,可以实现传统注意力(softmax)到线性注意力的无缝转移,
且转换后仅需开销很低的微调(LoRA),0.2%的参数更新即可恢复精度,对比同类的线性注意力模型或方法, 5-shot MMLU直接提高了20分左右!
也就是说,在几乎不损失Transformer大模型语言能力的基础上,将LLM的计算复杂度从二次方降到了线性。

线性Attention一事,前人之述备矣,然则,能够真正做大做强,还是第一次。
尤其具有实用价值的是,LoLCATs实现了极小的开销和接近原始模型的性能。
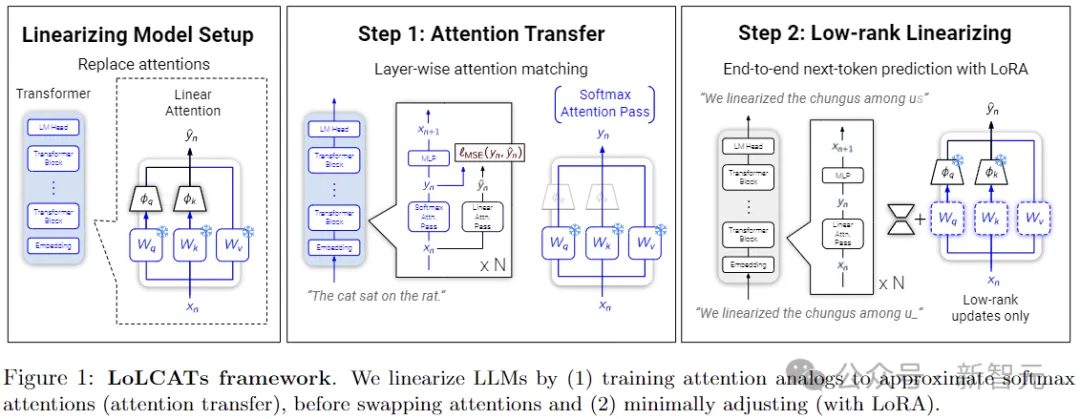
LoLCATs的线性化转换只需两个步骤:
首先使用线性Attention的形式替换原始Attention部分,并利用简单的MSE损失训练新增的参数,以近似softmax注意力;
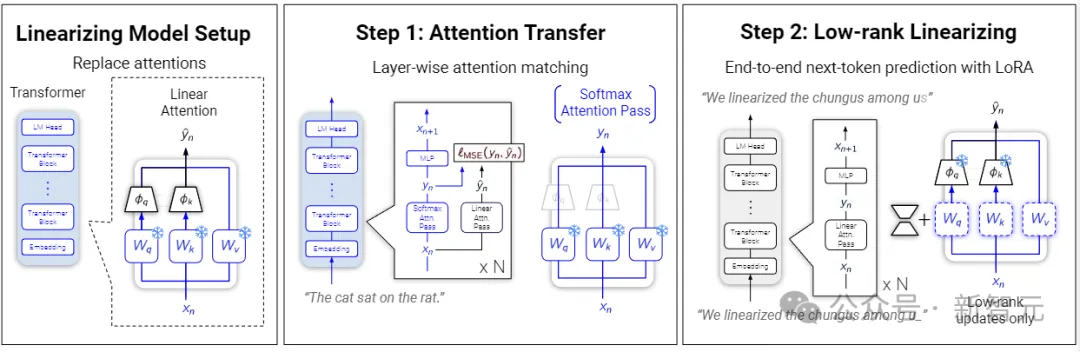
然后通过低成本的微调(LoRA)来进一步提高模型的精度。
为了实现可扩展性,作者采用更精细的「block by block」训练,将LLM的每k层看成一个block,尽在块内联合训练注意力,以提高分层注意力匹配。

就如上图所表示的那样,一个羊驼(Llama)可以看成多个小刺猬叠在一起,每个小刺猬拥有独特的用于线性化的参数,并且相互之间可以独立训练。
为了避免昂贵的训练成本,研究者们一直在不断探索两个方面:
make models fast 与 create fast models
诸如Mamba、RWKV、TransNormer、Hawk、 Griffin和 StripedHyena等高效的subquadratic models不断出现,
而关于将流行的LLM线性化的工作也让我们眼前一亮。

但是线性化LLM往往伴随着模型质量的显著降低,你甚至能通过MMLU的测试分数猜出一个模型是不是传统的Attention架构,或者传统Attention块在模型中的占比。
另外,从实用的角度讲,只有拿下了生产级别的大模型,线性化的道路才能真正与传统Transformer平分秋色。
先打基础:为什么要线性化?
正常的softmax注意力可以表示为下图上面的公式:
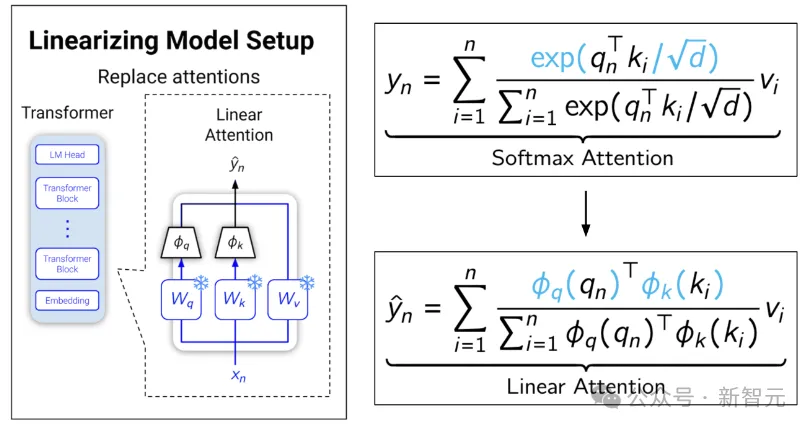
由于softmax的缘故,只能先算Q乘K,导致中间缓存和计算量随序列长度的平方增长;
线性化就是设计俩函数来近似softmax,从而把公式转化成下面的形式。
此时Q和K不需要绑在一起了,就可以先算K乘V,这个顺序的改变导致中间缓存和计算量随向量长度的平方增长,而相对于序列长度是线性关系。
这就是线性化的意思,这样的Attention也就不惧怕长序列带来的压力了。
本文中,作者的主要想法是向线性化Transformer中添加三个简单的概念:
1. Learnable (Linear) Attentions:可学习的(线性)注意力
2. Low-rank Adaptation:低秩适配
3. Layer-wise Optimization:分层优化
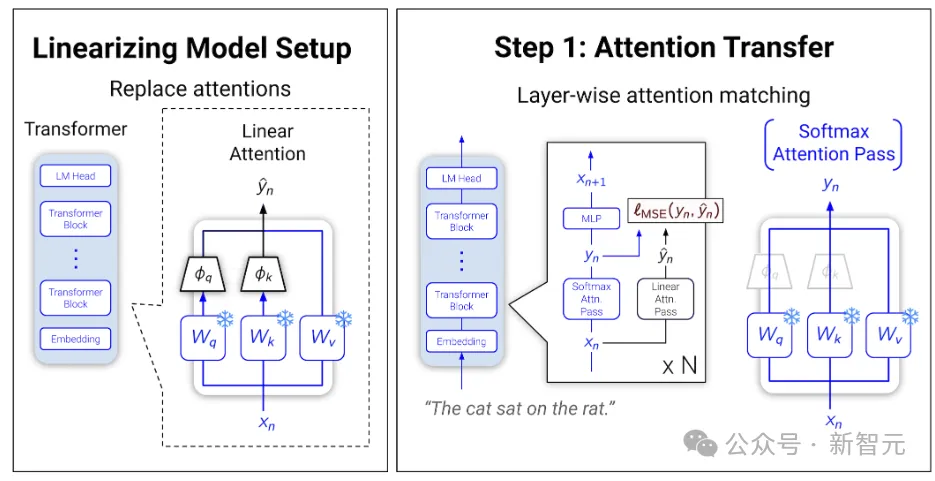
Learnable Attentions
首先训练线性注意力来模拟和替换softmax注意力。这种「注意力转移」的灵感来自作者之前的一篇工作:Hedgehog。

论文地址:https://arxiv.org/pdf/2402.04347
如何设计设计精妙复杂的函数来近似softmax注意力?
作者表示:与其让人类煞费苦心,不如交给AI自己去学!
相比于Hedgehog中只使用可学习的线性注意力,作者在LoLCATs中,将其推广为可学习的线性注意力和 + 滑动窗口。
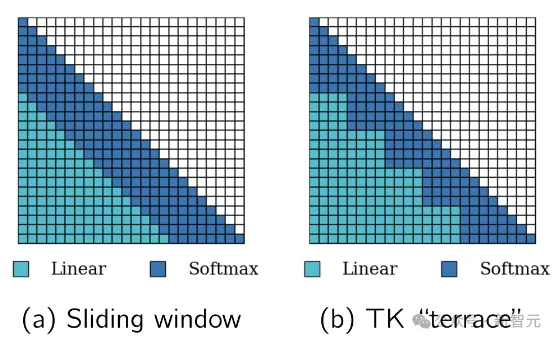
研究人员将线性和softmax注意力统一在一个层中,训练一些新增的参数以从整体上近似softmax注意力。
对于N个token的序列,前W个token用于计算softmax注意力,后N-W个token用于计算线性注意力,然后将这些值组合。
在Hedgehog中,作者通过KL散度来训练特征图以匹配注意力权重,而本文改为在注意力层的输出上使用MSE 失。
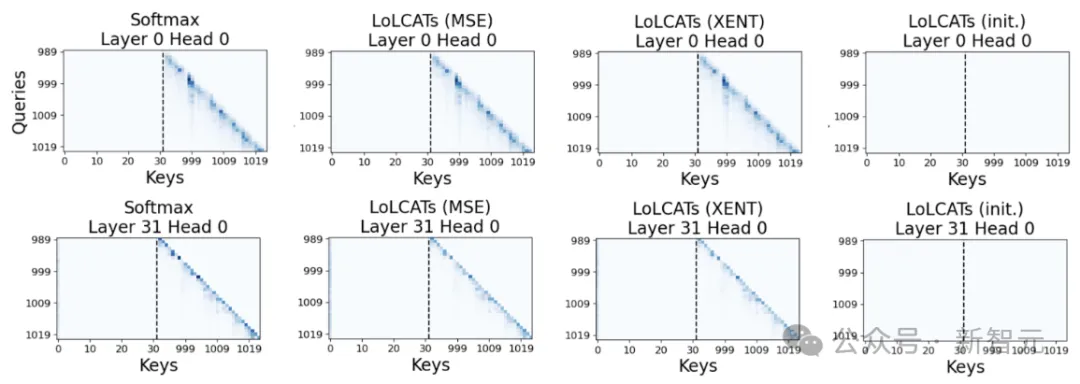
这绕过了Hedgehog的一个限制:需要将所有注意力权重实例化为监督目标。
相反,LoLCATs可以使用FlashAttention来计算softmax注意力输出,并将线性化注意力的内存消耗保持在O(N)。
只需将这些特征图插入到每个现有的注意力中,即可创建线性化的 LLM。冻结所有其他权重,只训练这些特征图,对于7B的LLM来说,只需要调整0.2%的参数。
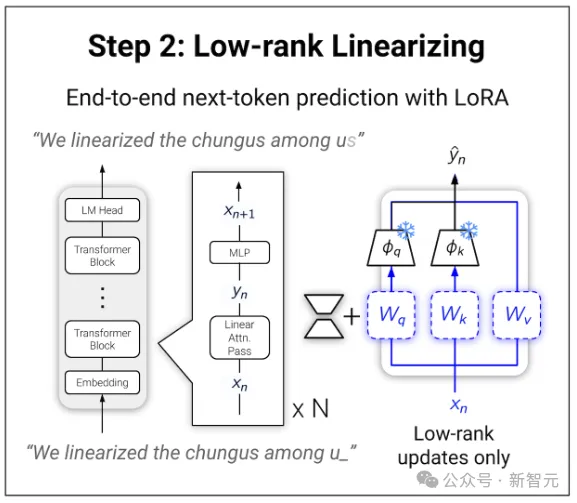
Low-rank Adaptation
之前的线性化工作,通常需要一个比较昂贵的端到端训练阶段。
但在LoLCATs这里,可以通过简单地将低秩适应(LoRA)应用于注意力的QKVO权重来恢复模型的性能。
冻结所有其他内容,只训练LoRA权重,在某些自然语言数据上,最大限度地减少LLM输出的next-token预测损失。
Layer-wise Optimization
大多数情况下,只需要以上两步就搞定了。但对于像Llama 3.1 405B这种规模的模型来说,还需要努力一下。
通过简单地联合优化所有层,可以成功地线性化7B到70B参数范围的LLM,但整体训练时,后面层的MSE会比前面的层更大。
当模型变得更大更深时,MSE升级为了微调Llama 3.1 405B的真正问题。
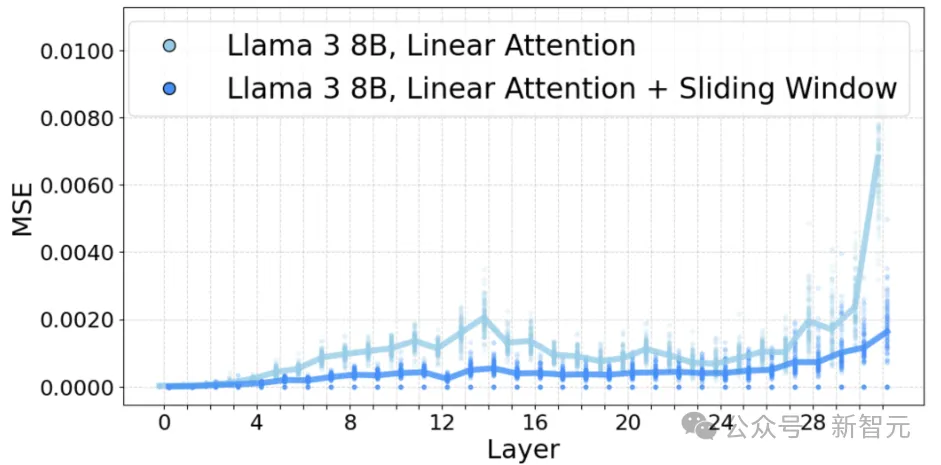
为此,研究人员使用了更精细的逐块训练,将Llama 3.1 405B分成多个k层块,并仅在每个块内联合训练注意力。
当使用一些线性化数据并行训练所有模块时,只需为每个块预先计算LLM的隐藏状态。
可以调节k来平衡并行训练的速度与预计算的内存,并将隐藏状态保存到磁盘。不需要花哨的成本模型,对于50M token的线性化来说:
k = 1时,需要2字节 × 126层 × 50M token × 16384(hidden size)= 200TB的磁盘空间来存储隐藏状态。
而k = 9时,磁盘空间的需求将减少为22TB,这时仍然能在单个GPU上并行训练每个块(9层)。
——后者显然更友好一点,所以作者将Llama 3.1 405B的126层拆分为14个9层块,在14个GPU上并行进行注意力的线性化,过程仅需5个小时。然后用LoRA将它们全部拼接在一起,就得到了最终模型。
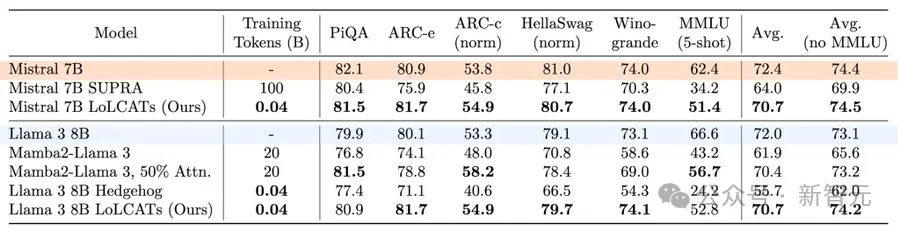
下表给出了6个流行的LLM评估任务的结果。
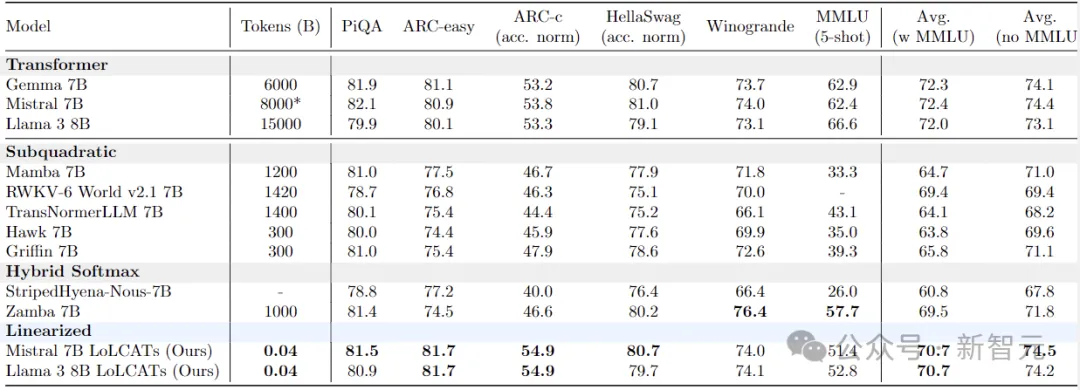
与最近的一些线性化方法相比,LoLCATs显著提高了不同任务和不同LLM的质量和训练效率。
尽管只训练了0.2% 的模型参数(40M token),LoLCATs将线性化与原始模型的性能差距平均缩小了80%以上,token to model的效率提高了500~2500倍。
在7B这个量级上,LoLCATs优于所有的线性注意力(包括RNN系列)模型:Mamba、RWKV、TransNormer、Hawk、 Griffin和 StripedHyena。
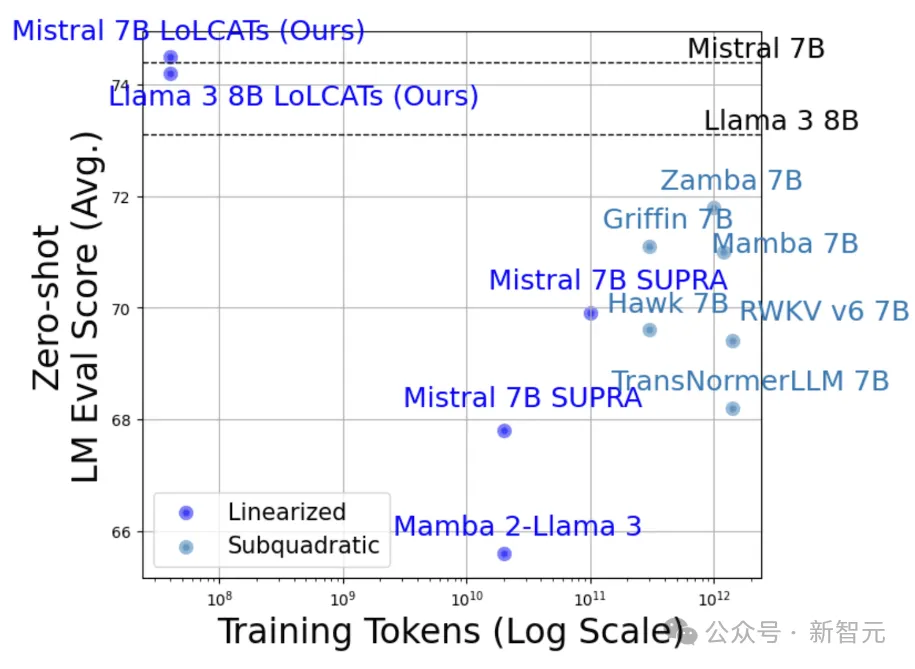
最后,作者使用LoLCATs将线性化扩展到Llama 3.1 70B和更大的405B模型。

与之前的线性化方法相比,首先是质量上的显著改进。通过控制相同的线性 + 滑动窗口层,对于Llama 3.1 70B,在5-shot MMLU上的精度实现了39点的提升,对于Llama 3.1 405B,同样实现了38.3分的改进。
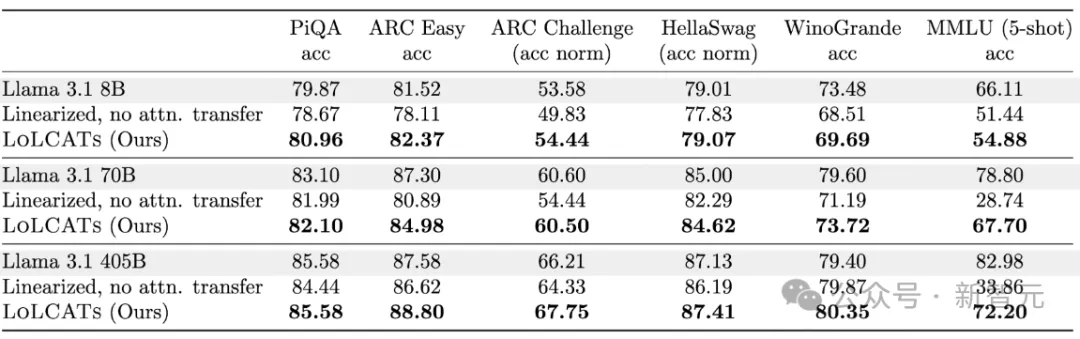
其次是训练效率的提高,在单个8x80GB H100上线性化Llama 3.1 70B仅需18个小时,而线性化Llama 3.1 405B所花费的时间比之前用于8B模型的方法还要少。
参考资料:
https://x.com/simran_s_arora/status/1845909074774475125
文章来自于微信公众号 “新智元”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
