# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
租用 H100 的钱只需 233 美元。
还记得 Andrej Karpathy 纯 C 语言复现 GPT-2 大模型的项目吗?
今年 4 月,AI 领域大牛 Karpathy 一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。
llm.c 旨在大幅简化大模型的训练,ta 使用纯 C 语言 / CUDA,不需要 245MB 的 PyTorch 或 107MB 的 cPython。不过即使是这样的优化,复现 GPT-2 级别的模型也需要在 8 块 H100 上花费 45 分钟进行训练。
没想到几个月过去,业界水平居然有了指数级的提升,让 Karpathy 本人都感到惊叹:
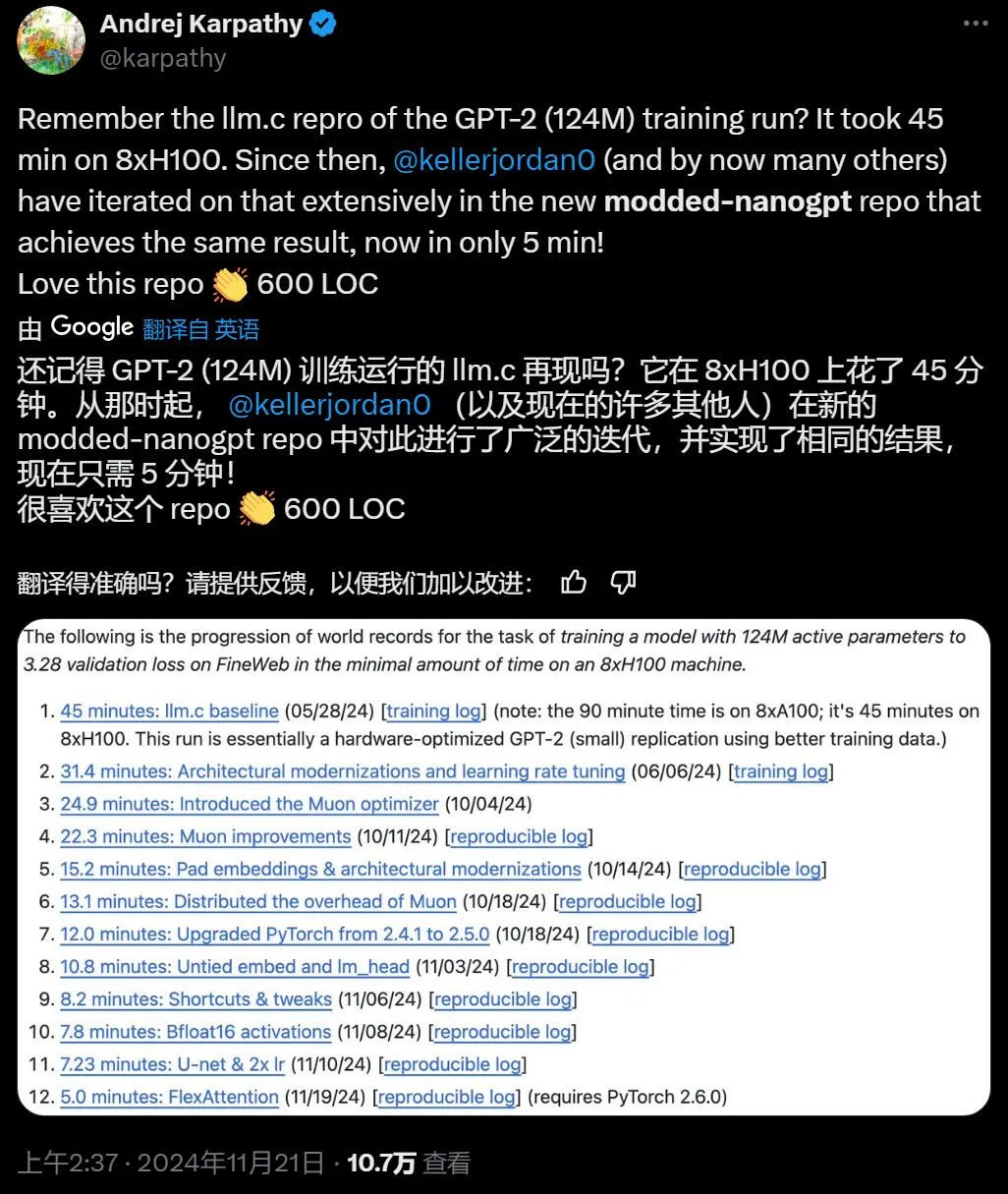
在 GitHub 上出现了一个新项目「Modded-NanoGPT」,对技术进行了大幅度的迭代,现在实现相同的结果只需要 5 分钟。该研究的作者 Keller Jordan 曾在 Hive AI 工作,一直以来的研究方向都着重于模型训练的优化。他在本周三表示,利用具有大序列长度的 FlexAttention,他已把速度的记录从 7.2 分钟提升到了 5 分钟。

现在有了 FlexAttention 和较大的 seqlen,文档的拆分更少了,因此语言建模在训练和验证时都变得更容易。该记录在 HellaSwag 上的准确率略有降低,约为 29%,而之前的记录和 Andrej Karpathy 的原始训练准确率约为 30%。
让我们看看他是怎么做的:

项目链接:https://github.com/KellerJordan/modded-nanogpt/tree/master
该项目名为「Modded-NanoGPT」,它是 llm.c 存储库的 PyTorch GPT-2 训练器的改进变体:
Modded-NanoGPT 采用如下技术:
要进行训练,请运行以下三个命令:
pip install -r requirements.txt
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu124 —upgrade # install torch 2.6.0
python data/cached_fineweb10B.py 10 # downloads only the first 1.0B training tokens to save time
./run.sh
在网络连接良好的 8xH100 上,训练应在 20 分钟内完成。
结果将是一个具有 124M 活跃参数的 transformer,在 10 亿 Fineweb tokens 上训练了 1875 steps,实现了约 3.278 的验证损失。相比之下,默认的 llm.c PyTorch 训练器在 100 亿 tokens 上训练了 19560 steps 后,验证损失 >3.28。
值得一提的是,要在更少的 GPU 上运行 Modded-NanoGPT,只需修改 run.sh 以获得不同的 --nproc_per_node。如果内存不足,只需在 train_gpt2.py 中将 device_batch_size 缩小到 16 或 32。
这里有一个适用于全新 8xH100 实例的启动脚本:
sudo apt-get update
sudo apt-get install vim tmux python3-pip python-is-python3 -y
git clone https://github.com/KellerJordan/modded-nanogpt.git
cd modded-nanogpt
tmux
pip install numpy==1.23.5 huggingface-hub tqdm
pip install --upgrade torch &
python data/cached_fineweb10B.py 18
如果 CUDA 或 NCCL 版本与你当前的系统设置不兼容,Docker 可以成为一种有用的替代方案。这种方法标准化了 CUDA、NCCL、CUDNN 和 Python 的版本,减少了依赖性问题并简化了设置。注意:系统上必须已安装 NVIDIA 驱动程序。
sudo docker build -t modded-nanogpt .
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt python data/cached_fineweb10B.py 18
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt sh run.sh
有一个问题在于,NanoGPT 训练很快是很好,但它可能无法扩展,只是过拟合了 val 损失?Keller Jordan 表示,这很难反驳,因为「按规模」是一个无限类别(如果这些方法对 >100T 的模型就不奏效了怎么办?),因此无法完全证明。此外,作者也同意快速运行中使用的一些方法不太可能扩展。但如果读者关心 1.5B 模型,他们可能会被这个结果说服:
直接将快速运行(10/18/24 版本)扩展到 1.5B 参数可以得到一个具有 GPT-2(1.5B)级 HellaSwag 性能的模型,它要比 Karpathy 的基线便宜 2.5 倍(233 美元对比 576 美元):
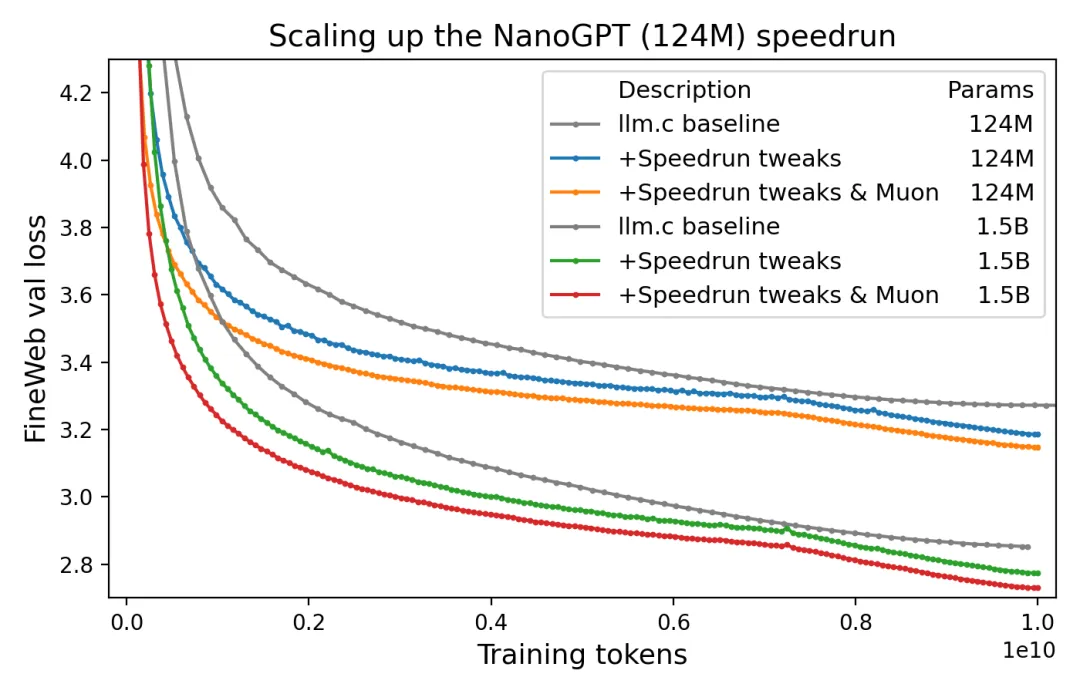
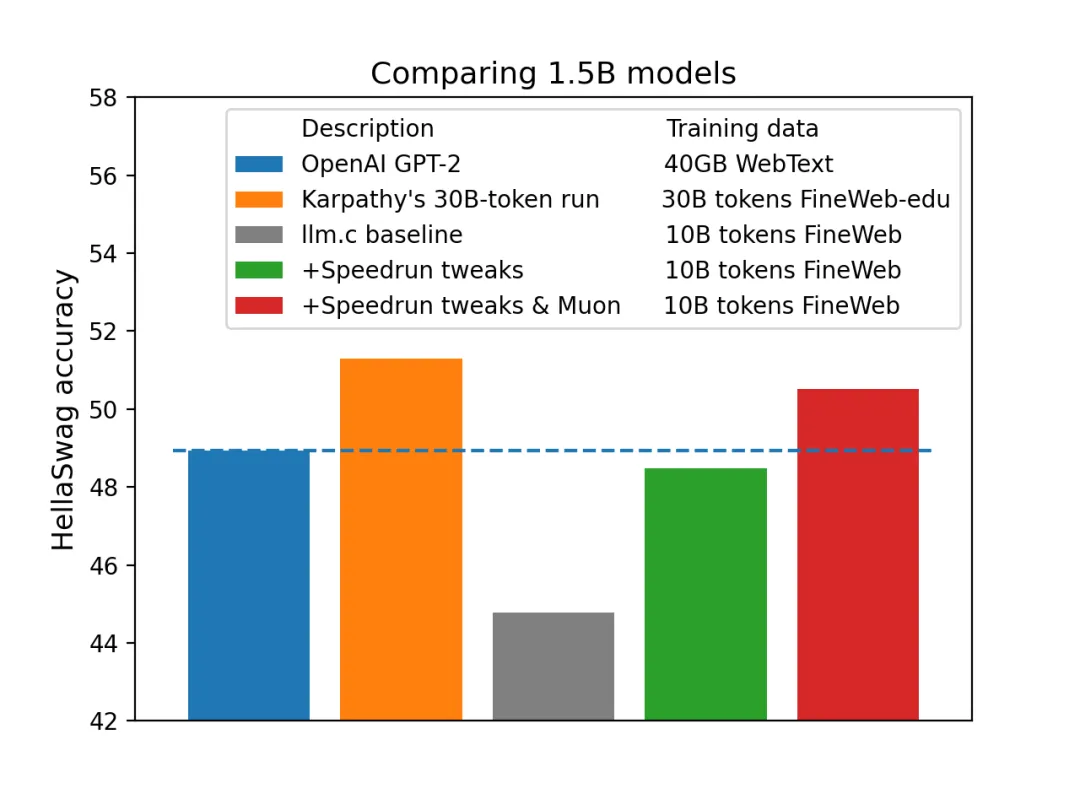
除了在前人的肩膀上探索,新项目也使用了 Keller Jordan 自研的优化方式。比如这个 Muon 优化器,据他所说是目前已知最快的优化器,适用于包括 CIFAR-10 和 GPT-2 规模语言建模在内的各种训练场景。
Muon 的定义如下:

其中 NewtonSchulz5 是 Newton-Schulz 之后的迭代,它近似地用 U @ V.T 替换 G,其中 U, S, V = G.svd ()。
@torch.compile
def zeroth_power_via_newtonschulz5 (G, steps=5, eps=1e-7):
assert len (G.shape) == 2
a, b, c = (3.4445, -4.7750, 2.0315)
X = G.bfloat16 () / (G.norm () + eps)
if G.size (0) > G.size (1):
X = X.T
for _ in range (steps):
A = X @ X.T
B = b * A + c * A @ A
X = a * X + B @ X
if G.size (0) > G.size (1):
X = X.T
return X.to (G.dtype)
对于这种训练场景,Muon 具有以下有利特性:
作者表示,生成此优化器的许多选择都是通过追求 CIFAR-10 快速运行而通过实验获得的。其中值得一提的经验包括:
使用 Newton-Schulz 迭代进行正交化的方法可以追溯到 Bernstein & Newhouse (2024),他们建议将其作为计算 Shampoo 预处理器的方法,并从理论上探索了没有预处理器累积的 Shampoo。Keller Jordan 特别感谢了论文作者之一 Jeremy Bernstein 的协助。
如果我们在这里使用 SVD 而不是 Newton-Schulz 迭代,那么这个优化器就会因为太慢而无法使用。Bernstein & Newhouse 还指出,没有预处理器累积的 Shampoo 相当于谱范数中的最陡下降,因此 Shampoo 可以被认为是一种平滑谱最陡下降的方法。所提出的优化器可以被认为是平滑谱最陡下降的第二种方法,与 Shampoo 相比,它具有不同的内存和运行时权衡。
文章来自于微信公众号 “机器之心”



