# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

为了拆开大模型的「黑箱」,Anthropic可解释性团队发表了一篇论文,讲述了他们通过训练一个新的模型去理解一个简单的模型的方法。
Anthropic发表的一项研究声称能够看到了人工智能的灵魂。它看起来像这样:

论文地址:https://transformer-circuits.pub/2023/monosemantic-features/index.html#phenomenology-fsa
在研究者看来,这个新的模型能准确地预测和理解原本模型中神经元的工作原理和组成机制。
Anthropic的可解释性团队最近宣布他们成功分解了一个模拟AI系统中的抽象高维特征空间。
研究人员首先训练了一个非常简单的512神经元AI来预测文本,然后训练了另一个名为「自动编码器」的AI来预测第一个AI的激活模式。
自动编码器被要求构建一组特征(对应更高维度AI中的神经元数量),并预测这些特征如何映射到真实AI中的神经元。
结果发现,尽管原始AI中的神经元本身不易理解,但是新的AI中的这些模拟神经元(也就是「特征」)是单义的,每特征都表示一个指定的概念或功能。
例如,特征#2663代表「God」这个概念。
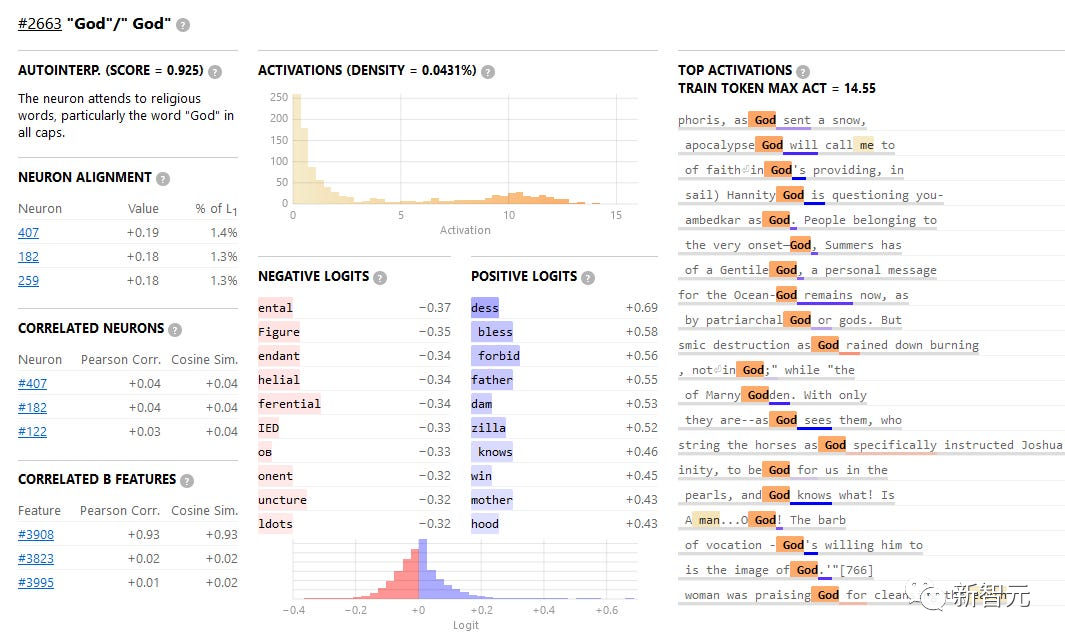
激活它的训练语句中最强的一条来自「Josephus」的记录中「当God降下暴雪时,他前往Sepphoris」。
可以看到顶端的激活都是关于「God」的不同用法。
这个模拟神经元似乎是由一组真实神经元(包括407,182和259)组成的。
这些真实神经元本身与「God」没有太大关系,例如神经元407主要对非英语(尤其是重音拉丁字母)和非标准文本(如HTML标签)有响应。
但是在特征层面,一切都是井井有条的,当特征2663被激活时,它会增加文本中出现「bless」、「forbid」、「damn」或「-zilla」的概率。
这个AI并没有将「God」这个概念与怪兽名字中的「God」区分开来。这可能是因为这个简易AI没有足够的神经元资源来专门处理这个事。
但随着AI具备的特征数量增加,这种情况会发生改变:
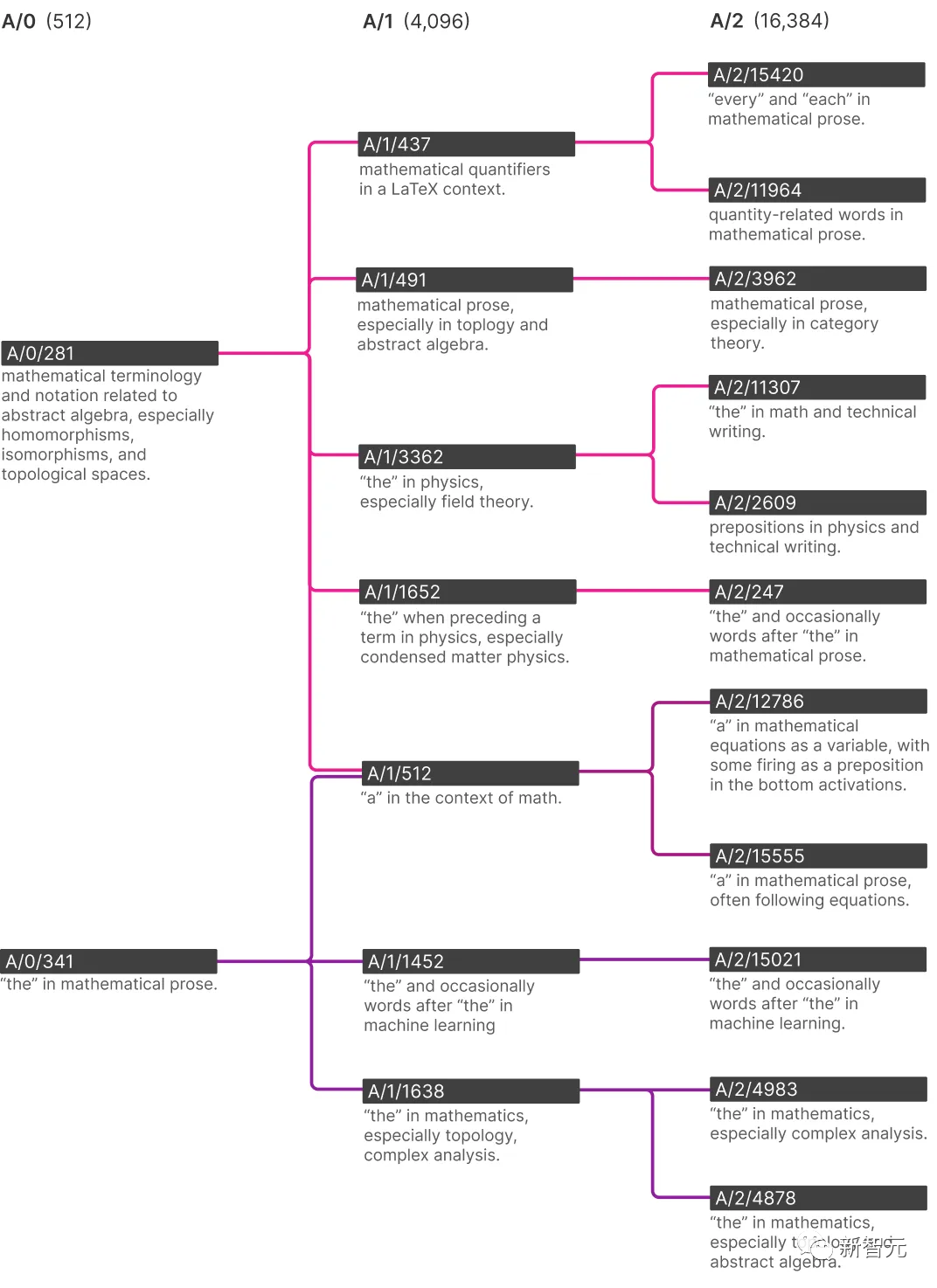
在这棵树的底部,你可以看到当这个AI具有越来越多的特征时,它在数学术语中对「the」的理解是如何变化的。
首先,为什么会有一个数学术语中「the」的特定特征?这很可能是由于AI的预测需求——知道某些特定的「the」之后应该会跟随一些数学词汇,比如「numerator」或者「cosine」。
在研究人员训练的最小的那个只有512个特征的AI中,只有一个表示「the」的特征,而在具有16384个特征的最大AI中,这个特征已经分支出了一个表示机器学习中「the」的特征,一个表示复分析中「the」的特征,以及一个表示拓扑学和抽象代数中「the」的特征。
因此,如果能将系统升级到一个具有更多模拟神经元的AI,那表示「God」的特征很可能会分裂成两个——一个表示宗教中「God」的含义,另一个表示怪兽名字中「God」的含义。
后来,可能会有基督教中的God、犹太教中的God、哲学中的God等等。
研究小组对412组真实神经元和相应的模拟神经元进行了主观可解释性评估,发现模拟神经元的可解释性整体上比较好:
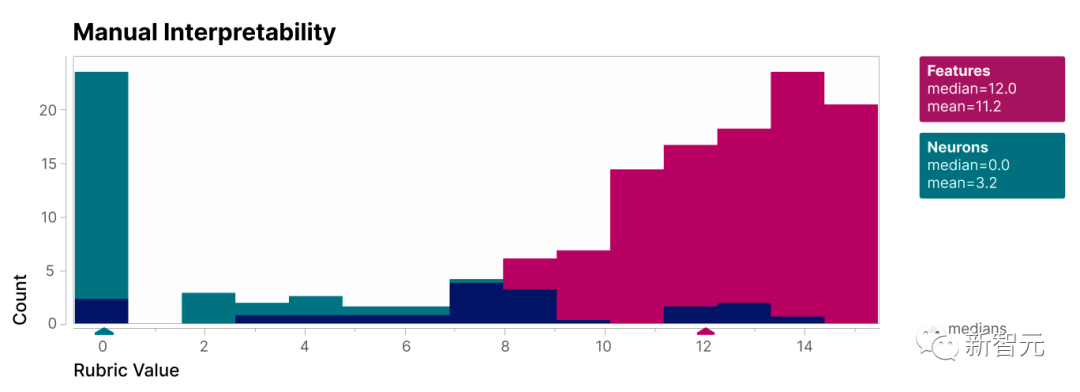
一些特征,比如表示「God」的特征,是用于特定概念的。
许多其他高度可解释的特征,包括一些最可解释的,是用于表示文本的「格式」,比如大写或小写字母、英语或其他字母表等。
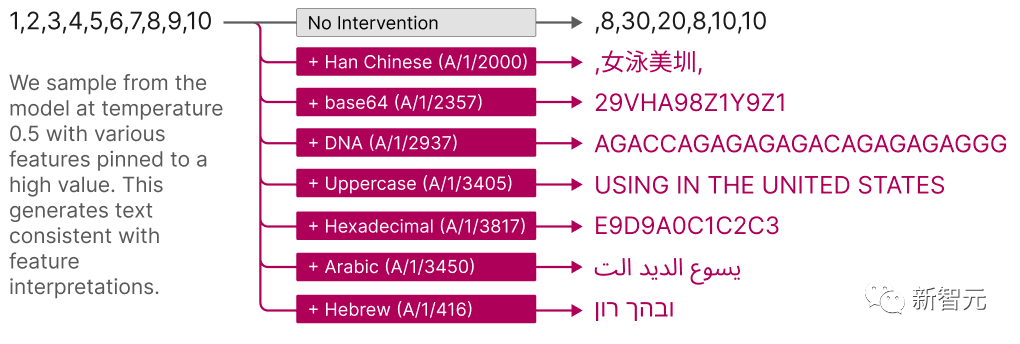
这些特征有多常见呢?也就是说,如果你在相同的文本数据上训练两个不同的4096个特征的AI,它们会有大部分相同的4096个特征吗? 它们会都有某些代表「God」的特征吗?
或者第一个AI会将「God」和「哥斯拉」放在一起,而第二个AI会将它们分开?第二个AI是否就完全不会有表示「God」的特征,而是用那个空间存储一些第一个AI不可能理解的其他概念?
研究小组进行了测试,发现他们的两个AI模型是非常相似的!
平均而言,如果第一个模型中有一个特征,第二个模型中最相似的特征会有0.72的中值相关性。
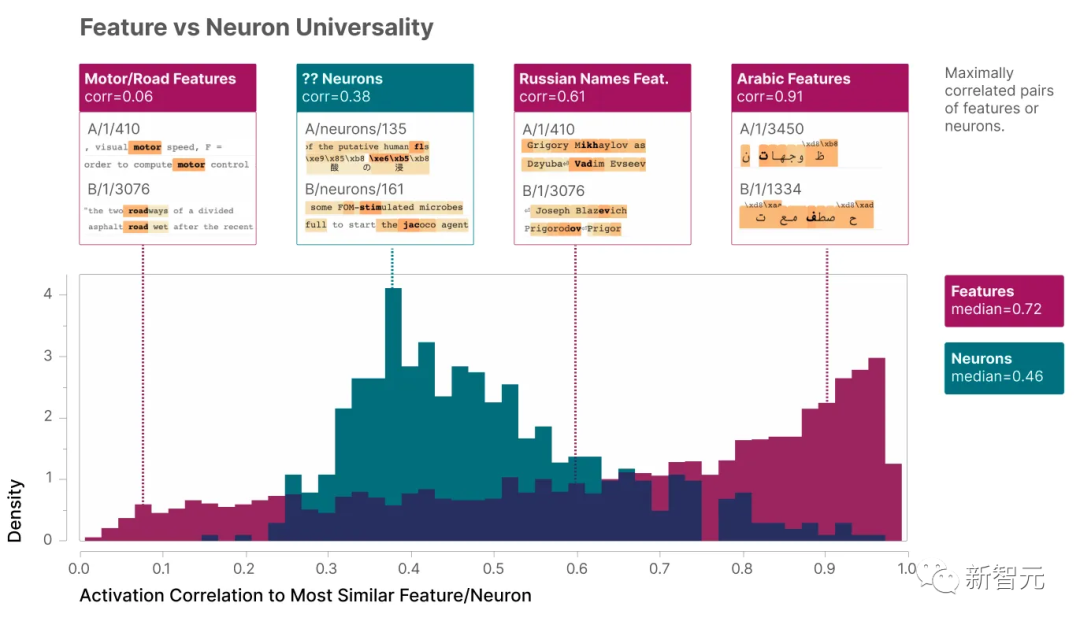
后续的工作将是什么呢?
今年五月,OpenAI试图让GPT-4(非常大)理解GPT-2(非常小)。他们让GPT-4检查了GPT-2的个307200个神经元,并报告它发现的内容。
GPT-4找到了一系列有趣的结果和一堆随机废话,因为他们还没有掌握将真实神经元投射到模拟神经元并分析模拟神经元的技巧。
尽管结果效果不明显,但这确实是非常雄心勃勃的尝试。
与Anthropic可解释性文章中的这个AI不同,GPT-2是一个真实的(尽管非常小)AI,曾经也给大众留下了深刻印象。
但是研究的最终目的是要能够解释主流的AI系统。
Anthropic的可解释性团队承认他们还没有做到这一点,主要基于以下几个原因:
首先,扩大自动编码器的规模是一个很困难的事情。为了解释GPT-4(或Anthropic的等效系统Claude)这样的系统,你需要一个差不多同样大小的解释器AI。
但是训练这样规模的AI需要巨大的算力和资金支持。
其次,解释的可扩展性也是一个问题。
即使我们找到了所有关于God、哥斯拉以及其他一切的模拟神经元,并画出它们之间如何相连的巨大关系图。
研究人员任然需要回答一些更复杂的问题,解决这些问题需要涉及成百上千万的特征和连接的复杂交互。
所以需要一些自动化的流程,也就是某种更大规模的「让GPT-4告诉我们GPT-2在做什么」。
最后,所有这些对理解人类大脑有什么启发?
人类也使用神经网络进行推理和处理概念。
人类大脑中有很多神经元,这一点和GPT-4是一样的。
人类获得的数据也非常稀疏——有很多概念(如乌贼)在日常生活中很少出现。
我们是否也在模拟一个更大的大脑?
目前这还是一个非常新的研究领域,但已经有一些初步的发现,表明人类视觉皮层中的神经元确实以某种超定位的方式编码特征,与AI模型中观察到的模式相似。
参考资料:
https://transformer-circuits.pub/2023/monosemantic-features/index.html#phenomenology-fsa
文章来自于微信公众号“ 新智元”,作者 “润”


