# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
将知识图谱技术与RAG有机结合的GraphRAG可谓是今年下半年来的LLM应用领域的一个热点,借助大模型从非结构化文本数据创建知识图谱与摘要,并结合图与向量索引技术来提高对复杂用户查询的检索增强与响应质量。其中微软的开源项目GraphRAG获得了广泛关注,但现有的GraphRAG最被人诟病的不足是:模型使用成本过高且性能较低,特别是索引阶段(Indexing),即从原始非结构化数据中进行实体、关系、摘要、社区等信息的抽取与生成,需占用大量的LLM使用成本。

尽管GraphRAG在0.4版本中作了一定的升级,包括可以进行文档知识的增量抽取,以及新的DRIFT查询模式,一定程度的降低使用成本,提高查询质量,但问题并没有得到根本优化。
今日凌晨,微软宣布将推出 GraphRAG 的全新迭代版本LazyGraphRAG。核心亮点是极低的使用成本,其数据索引成本仅为现有GraphRAG 的 0.1%。此外,LazyGraphRAG 引入了全新的混合数据检索方法,大幅提升了生成结果的准确性和效率。该版本将很快开源,并纳入到 GitHub GraphRAG 库中。

让我们一起来先睹为快,为大家做初步解读。
LazyGraphRAG 的核心优势在于其在成本和质量方面的提升。在多种竞争方法(包括标准的向量 RAG、RAPTOR<一种主要用于全局概要问题查询的RAG方法>、GraphRAG 的本地搜索、全局搜索和 DRIFT 搜索)中,LazyGraphRAG在使用成本与输出质量有极大提升,具体表现在:
根据微软介绍,LazyGraphRAG 是一种兼具向量 RAG 和 Graph RAG 优势的新方法,同时针对它们在不同场景中的局限性进行了优化。
【向量 RAG】
向量 RAG 使用最佳优先搜索,根据查询与数据中文本片段的语义相似度,选择最匹配的内容。这种方式在处理简单、局部化的查询(如一些事实性问题)时非常高效。然而,向量 RAG 的局限性在于缺乏对数据集全局结构与知识的认知能力。当查询需要更全面的视角时,例如需要跨领域或跨社区的信息整合来回答概要与总结性问题时,它可能会遗漏关键信息。
【GraphRAG】
GraphRAG 的广度优先搜索使用社区结构(Community,一组有一定主题的紧密相关的实体及其关系)来组织和检索数据知识,能够在全局查询时(Global Search)确保查询结果覆盖更大的信息范围。但它的局限是在处理本地查询(Local Search)时无法判断哪些社区是最相关的。
最主要的问题是,GraphRAG在数据索引阶段需要利用大模型提取和描述实体及其关系、为每个实体和关系生成摘要、通过算法识别图中的社区与生成社区描述,以及对摘要与描述做嵌入等。这一系列过程导致模型使用的成本非常高昂。
LazyGraphRAG 通过一种迭代加深的方式结合了最佳优先搜索和广度优先搜索。相比现有GraphRAG 的全局搜索机制,这种方法“懒惰”地推迟了 LLM 的使用,从而显著降低成本并提高了答案生成效率。且LazyGraphRAG整体性能可以通过单一的参数——相关性测试预算(relevance test budget)来进行调节,以控制成本与质量的权衡。LazyGraphRAG与现有GraphRAG在处理方法上的区别可以用下图来理解:
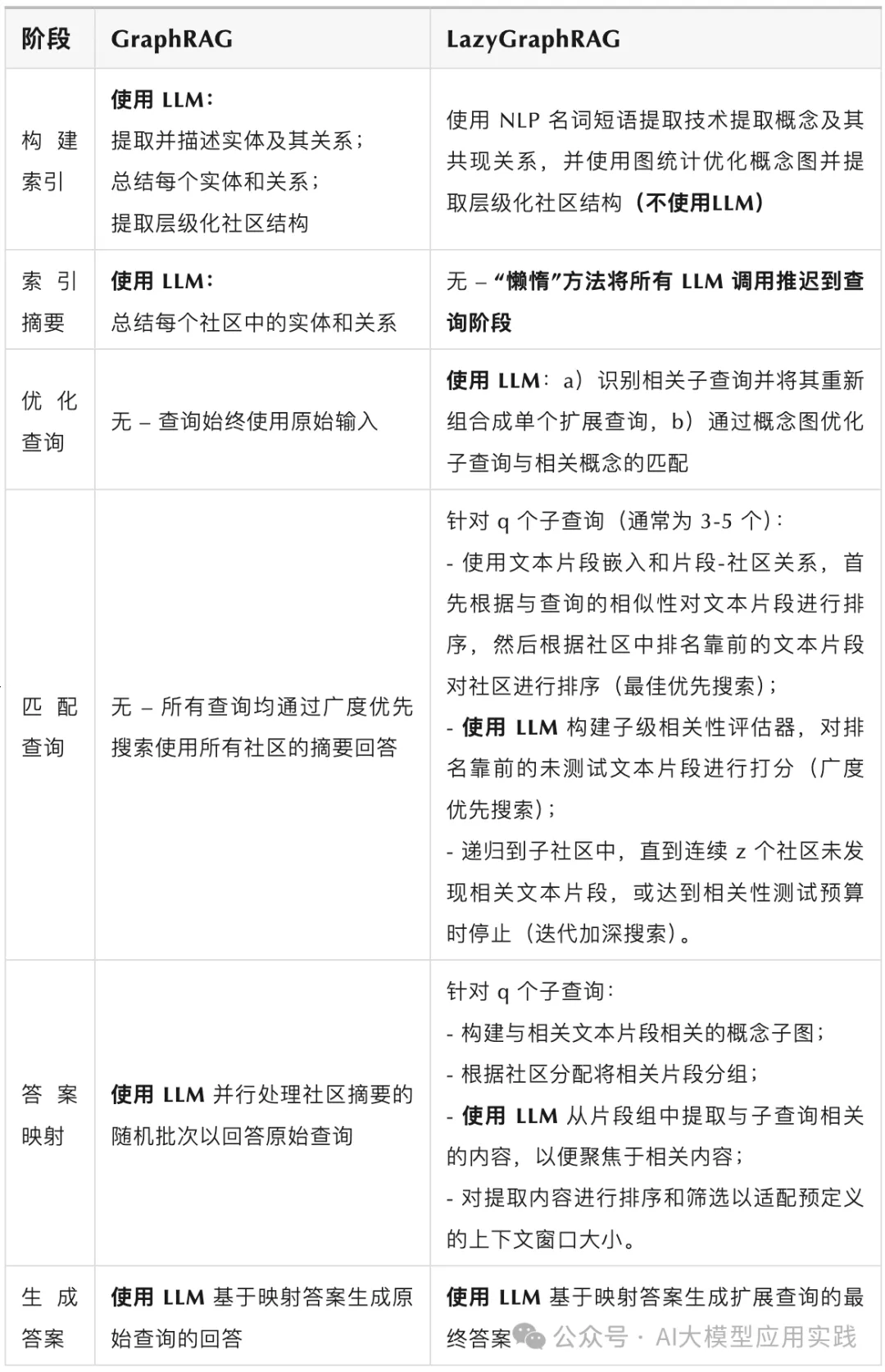
上表中,完整的展示了LazyGraphRAG与GraphRAG在从索引到查询阶段(主要是全局查询)的处理环节的区别。可以看到,两者最主要的区别是:
LazyGraphRAG 的核心思想是通过一种分阶段、迭代优化的方式,将 LLM 的调用推迟到最关键的步骤,并结合轻量化的技术大幅降低成本,同时维持高质量的查询结果。其“懒惰”的特性并不是降低功能,而是通过优化调用时机和操作流程,实现了更高效的查询和答案生成。
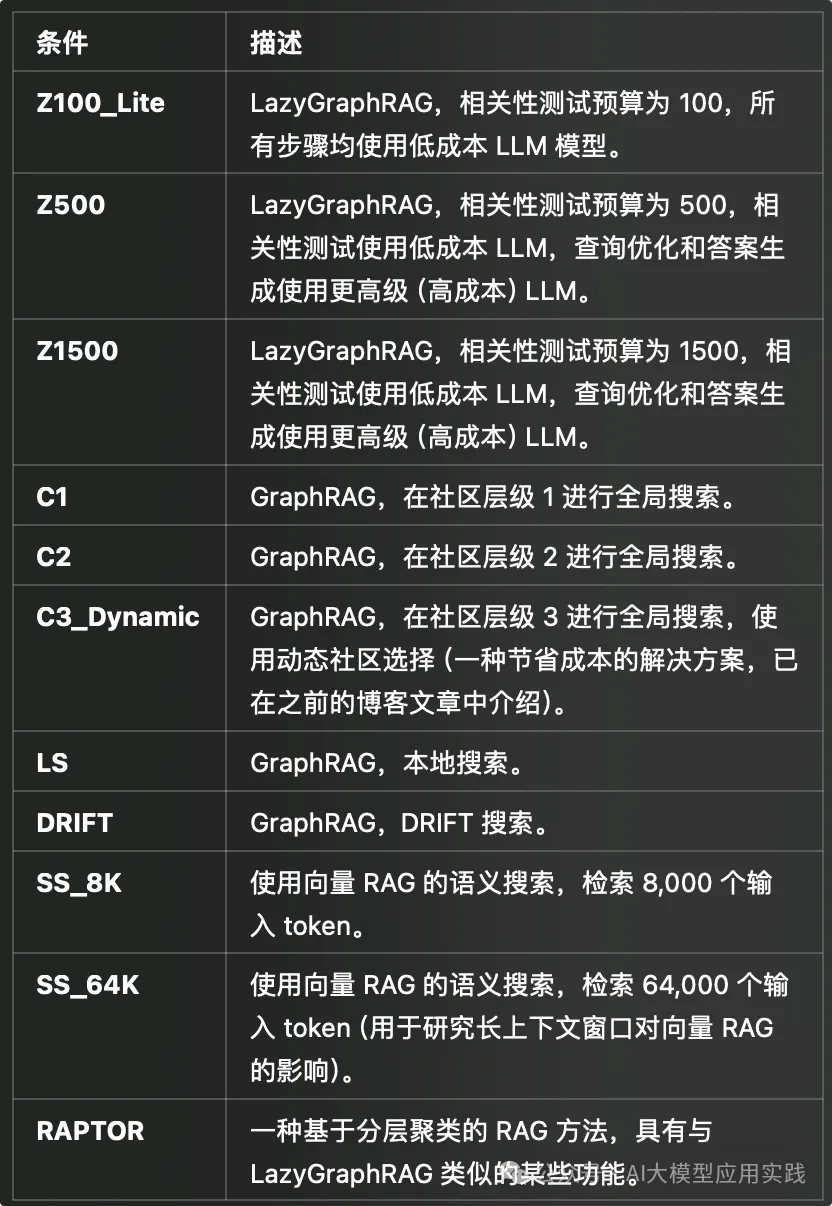
微软在不同的相关性测试预算水平下,对 LazyGraphRAG 与一系列竞争方法进行了比较,具体环境如下:
• Comprehensiveness(综合性):结果覆盖了查询的关键内容和相关背景。
• Diversity(多样性):结果包含来自不同领域或角度的多样化信息。
• Empowerment(赋能性):结果帮助用户进一步理解问题或做出决策。
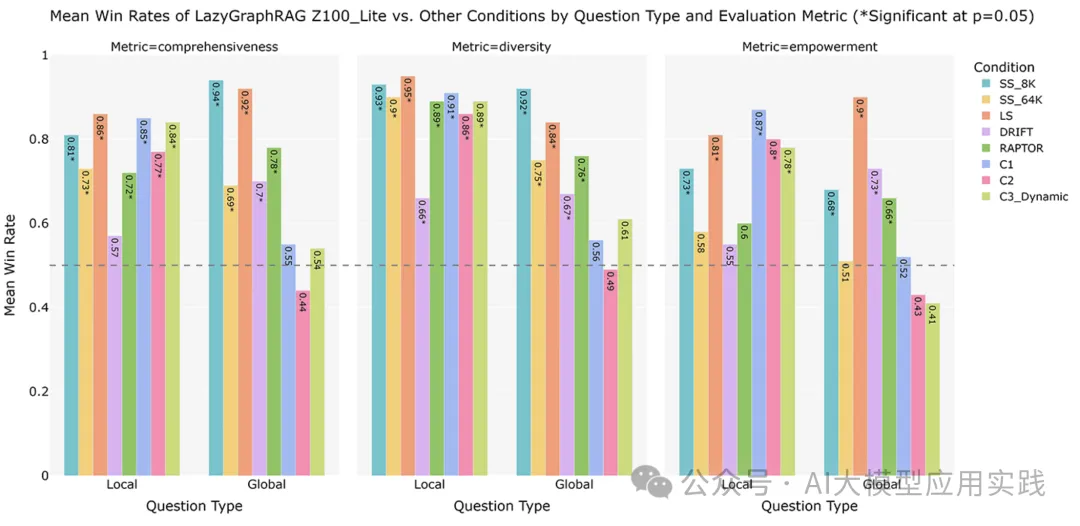
下图展示了在使用低成本 LLM 模型(成本与 SS_8K 相同,即与普通向量RAG相同的成本预算)进行 100 次相关性测试的最低预算条件下, LazyGraphRAG 相对于八种竞争条件的胜率。
这里稍做分析:
1. LazyGraphRAG 在本地查询中的优势非常显著:
• 在所有指标(综合性、多样性、赋能性)上都表现出色,尤其是在多样性指标中,胜率接近 0.95。
• 使用低预算(100 次相关性测试)和低成本 LLM,即能在大多数条件下胜过其他方法。
2. 在全局查询中仍具有竞争力:
• LazyGraphRAG 在全局查询上的表现稍弱于其本地查询的表现,但在综合性和多样性指标上仍处于领先位置。
• 在赋能性上略逊于某些特定的 GraphRAG 全局搜索方法,但依然优于传统的语义搜索条件(如 SS_8K 和 SS_64K)。
3. LazyGraphRAG 的成本效益表现良好:
• 在使用低预算和低成本 LLM 的情况下,其整体性能仍能超过大部分竞争方法,说明了 LazyGraphRAG 的优化设计在成本与质量之间达到了良好的平衡。
当把预算增加到 500 次相关性测试,并使用更高级的 LLM 模型(查询成本仅为 C2 的 4%)时,LazyGraphRAG 在本地和全局查询上都展示了更大的优势。当把相关性测试预算增加到 1500 次,LazyGraphRAG 的胜率持续提高,展现了其在成本与质量方面的更大优势。具体参考下图:
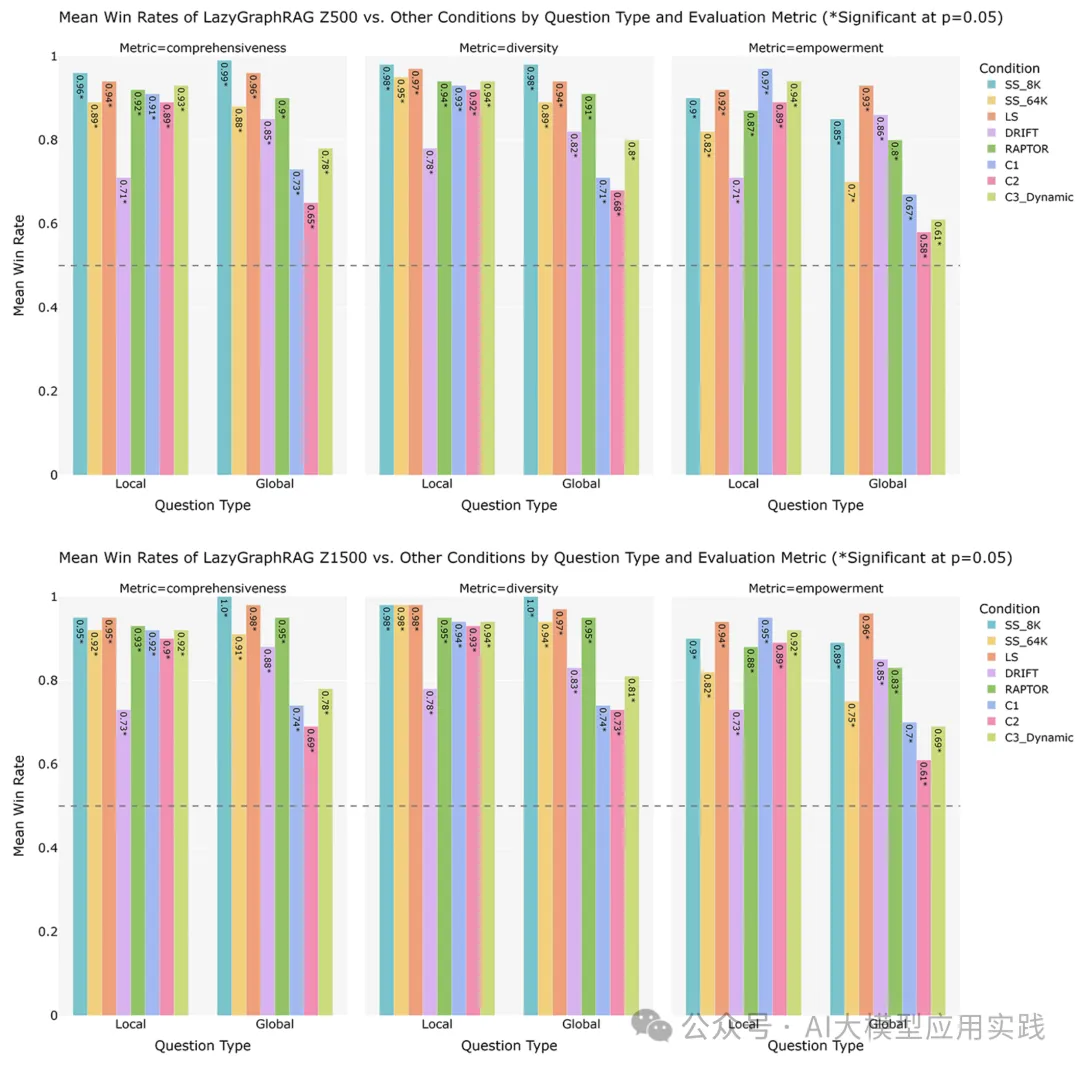
LazyGraphRAG展示了未来GraphRAG一种新的可能性:你可以在几乎没有LLM成本的索引构建基础上,更高质量的完成基于知识图谱的查询与回答,且可以随着成本预算的调整来提升问答质量,以适应不同场景的要求。当然,这种方法仍然存在优化的空间,比如:如果在不考虑成本的前提下,结合现有GraphRAG的索引方法,与LazyGraphRAG的查询阶段的优化方法,是否会有更加出色的效果?
让我们一起期待LazyGraphRAG的正式发布。
参考:
https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/
文章来自于“AI大模型应用实践”,作者”秋山墨客“。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
