# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
之前的文章我介绍过吴恩达教授重点推荐的Medprompt《吴恩达强烈推荐研究微软的Medprompt,微调VS提示工程究竟哪个更有效》Medprompt不仅用多策略Prompt解决实际问题,更是让专有模型微调和提示工程的性能进行了正面交锋。
近期,微软研究团队发布了一项重要的研究成果,揭示了AI推理能力从传统的提示工程方法(如Medprompt)到原生推理机制(如OpenAI的o1)演进的全貌。此项研究为正在开发AI产品的朋友们提供了宝贵的技术洞察。本文将详细分析这一研究的过程和结论,探讨其对AI推理领域及产品开发的深远影响。

图片由修猫提供

医疗领域以其专业性和对精度的高要求,成为了AI技术应用的高标准挑战场。医疗问答系统,尤其是与临床诊断和治疗决策相关的应用,要求AI不仅具备强大的语言生成能力,还需要在复杂的推理过程中展现出较高的准确性。正因如此,医疗领域成为了AI推理技术的重要测试场。在这一背景下,微软的研究团队选择了医疗问答任务作为基准测试,利用这一领域的高要求,考察不同AI模型在推理能力上的表现。
Medprompt是传统提示工程方法的一项典型代表,它通过一系列精心设计的提示策略提升了模型在特定任务中的表现。具体来说,Medprompt包括以下三个关键技术:
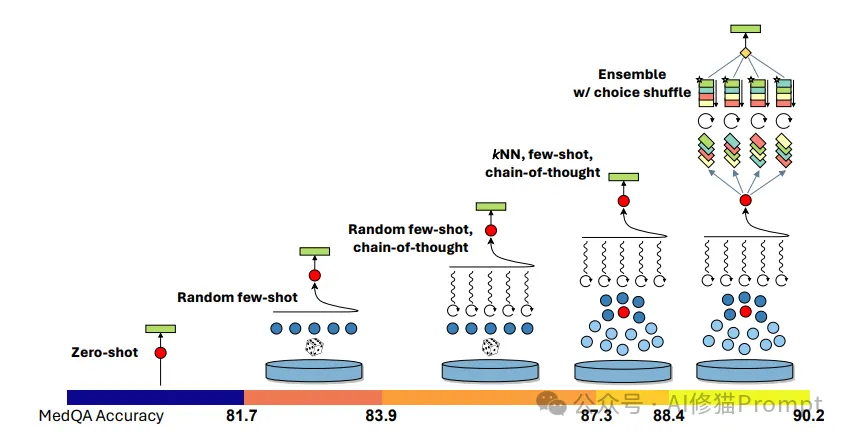
1.动态链式思考推理
这一策略通过引导模型分步思考,帮助其在解决复杂问题时避免直接跳到结论。每一步推理都为下一步提供了更准确的背景信息,从而提高了整体推理的精度。
2.少样本示例的精心策划
在少量示例的基础上,模型通过推理扩展其解决方案的泛化能力。这种策略在某些任务中可以大幅度提高模型的性能,尤其是在样本数据有限的情况下。
3.选项随机排序的集成技术
该策略通过在生成的多个答案中随机排序选项来防止模型产生偏见,确保最终选择最具代表性和合理性的答案。
通过这些策略,Medprompt在GPT-4模型上取得了显著的提升,特别是在医疗问答基准测试(如MedQA)中,其准确率达到了90.2%。这一成就展现了传统提示工程方法在提升AI推理能力方面的巨大潜力。可以看一下之前文章里的Medprompt运行的插图:

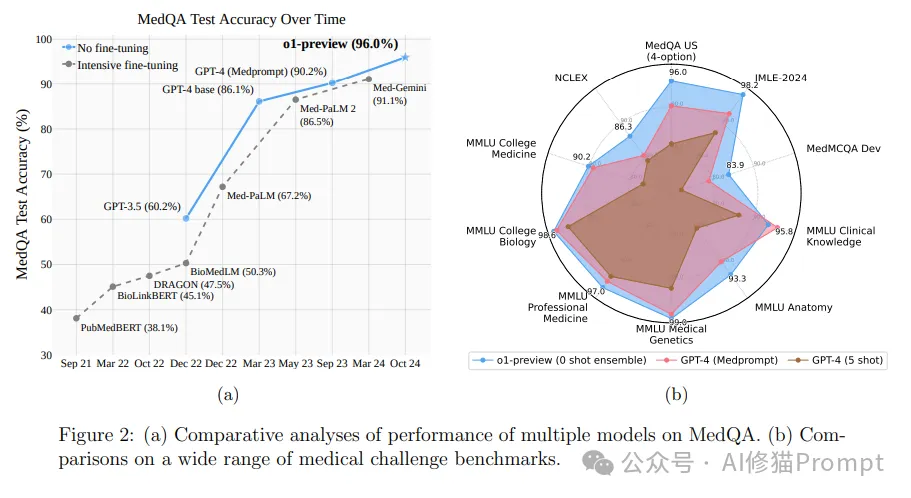
与Medprompt依赖提示工程的方法不同,OpenAI的o1-preview模型则展示了AI推理能力的新范式。o1并不依赖复杂的提示工程技术,而是在模型的训练过程中直接融入了推理能力。研究表明,o1-preview模型即便在没有任何提示的情况下,也能在多个医疗基准测试中超越了使用Medprompt的GPT-4。
o1的核心优势在于其原生推理机制。模型能够在生成最终答案之前进行自主推理,这一过程不仅提高了推理的准确性,还使得模型能够在面对复杂问题时展现出更加灵活和全面的应对能力。这种能力的内置,使得o1能够超越传统的提示依赖方法,尤其是在医疗领域这类需要深度推理的应用中,展现出更为强大的性能。
下图我们可以看出,o1-preview模型的性能优于GPT-4与Medprompt的增强,这些结果突显了一个不断发展的格局,其中模型训练的进步已经开始内化旨在运行时优化的提示工程背后的原则。
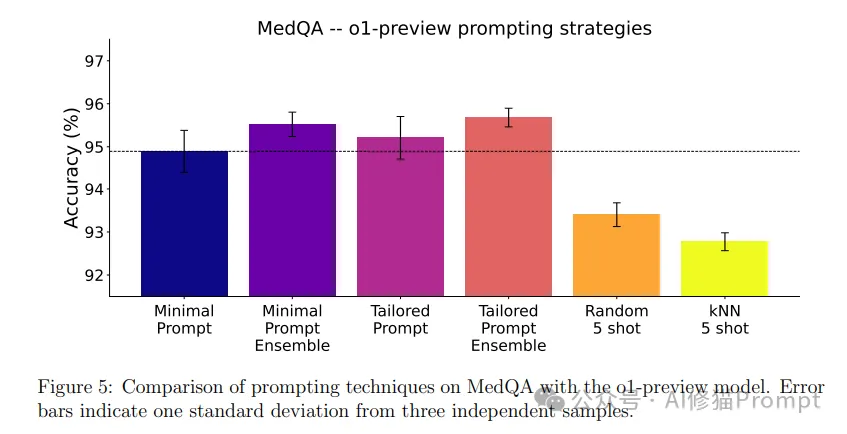
研究团队对传统提示工程策略在o1模型上的效果进行了深入的评估,得出了几个值得注意的结论:
少样本提示(Few-shot prompting)反而会降低o1的性能
在传统模型中,少样本提示常常能提升模型的表现,但在o1模型上,这一策略反而带来了性能下降。这一现象表明,o1模型不再依赖示例驱动的推理方式,而是通过其内置的推理机制直接进行推理。
集成策略(Ensembling)仍然有效,但成本较高
集成多个模型的策略仍然能有效提高推理结果的准确性,但对于o1这种原生推理能力较强的模型来说,集成的收益较为有限。使用集成策略时,仍需要权衡其带来的成本和提升的效益。
定制化提示(Tailored prompting)效果有限
定制化提示技术的效果在o1模型中也相对有限,模型的强大推理能力使得它在不依赖提示的情况下,能够自动适应并解决问题。
五次提示导致性能显著下降
下图显示了MdQA数据集上的结果,包括用于说明性能变化的误差线。值得注意的是,五次提示导致性能显著下降,这表明在提示中提供多个类似的示例可能会使模型感到困惑。这一观察结果与OpnAI官方指南一致,该指南指出,过多检索的上下文可能会影响性能。
为了深入理解不同推理策略的性价比,研究团队建立了准确率与成本的帕累托前沿,并发现了以下重要结论:
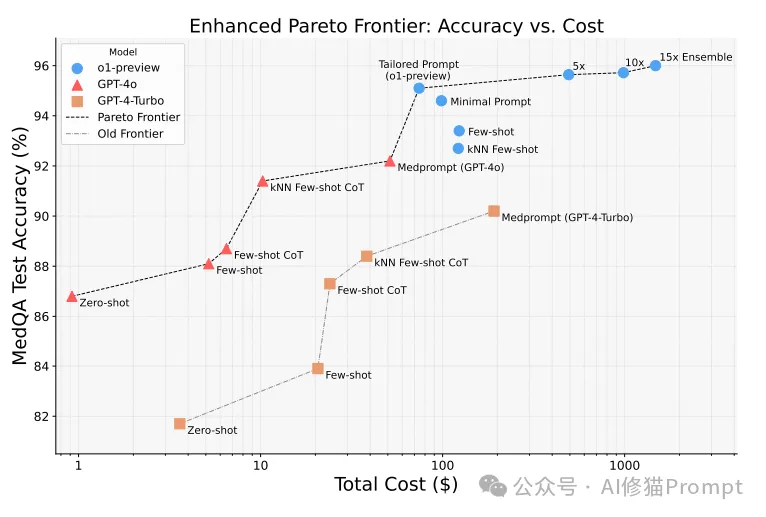
GPT-4o提供了较为经济的解决方案
在多个医疗基准测试中,GPT-4o提供了相对较高的准确率,同时其计算成本和资源消耗较低,适合在许多应用场景中使用。
o1-preview虽然性能最优,但成本显著较高
尽管o1-preview在推理能力上表现出色,准确率也比GPT-4o高出了几个百分点,但其所需的计算资源和运行成本大幅增加,尤其是在处理大规模数据时,成本的提升非常显著。
准确率从88%提升到96%,成本增加约100倍
这一数据展示了高性能模型带来的成本效益权衡。在追求更高准确率时,成本会显著增加,这对于AI产品的开发人员来说是一个重要的决策因素。
随着o1-preview模型在多个现有医疗基准测试中接近饱和,研究团队指出了当前评估体系的局限性。现有的基准测试和评估方法已经无法完全反映新一代模型的能力,这意味着:
需要开发更具挑战性的测试基准
传统的评估标准已经无法全面衡量最新AI模型的推理能力,亟需开发新的测试基准,以适应不断演进的技术。
现有评估方法的更新迫在眉睫
目前的评估方法可能偏重于某些特定的任务和数据集,而忽略了AI模型在真实世界中的复杂表现。因此,评估方法的更新需要更加贴近实际应用场景。
模型评估体系的完善
模型评估体系不仅要关注准确率,还要更加注重模型的实际应用表现和在不同场景中的适应能力。
1.策略选择的重新思考
2.成本优化方案
3.评估方法的调整
1.推理能力的进一步提升
2.与外部资源的集成
3.评估体系的革新
从Medprompt到o1的技术演进,标志着AI推理能力的质变。这一进程不仅代表了模型能力的提升,更意味着AI应用范式的根本转变。对于Prompt工程师来说,了解这一演进过程,并在实际开发中灵活运用新技术,将是未来工作的关键。随着推理技术的进一步提升和评估体系的完善,AI在医疗、金融、法律等领域的应用将迎来更加广泛的创新与突破。关于Medprompt欢迎和我交流,以下是之前文章的资料赠予介绍(包含这条Medprompt的system prompt)。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
