# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 EMNLP 2024 上,我们看到了向量模型的各种创新用法,其中最出人意料的莫过于:文本水印。
试想一下,你挑灯夜战,终于给那篇倾注了一整个周末心血的文章,点击了发布键,成就感满满,虽然点赞不多,但这是属于你的作品。结果没几天,你却发现自己的文章被洗稿了!熟悉的配方,陌生的味道,更可气的是,“李鬼”的传播度还远超“李逵”。这哪还有创意经济的公平可言?
最直观的办法当然是署名,但说实话,署名也最容易被删掉。有没有更牢靠的防盗手段呢?我们认为是有的。
本文将介绍一种基于向量模型的文本水印技术,它既能给文本加上水印,又能检测出文本水印。这可不是对现有搜索或 RAG 技术的套壳,而是利用了 Jina Embeddings v3 模型的独特优势 —— 长文本处理和跨语言对齐 —— 来构建一个强大的认证系统。即使被抄袭的文本经过了 LLM 改写或翻译,它也能可靠地识别出你的原创内容。
jina-embeddings-v3: https://jina.ai/?sui&model=jina-embeddings-v3
数字水印技术一直是内容保护的重要手段。我们熟悉的图片上层层叠叠的水印,只是最基础的图像水印。现代水印技术已经发展得更加先进,许多水印人眼不可见,却能被机器读取。
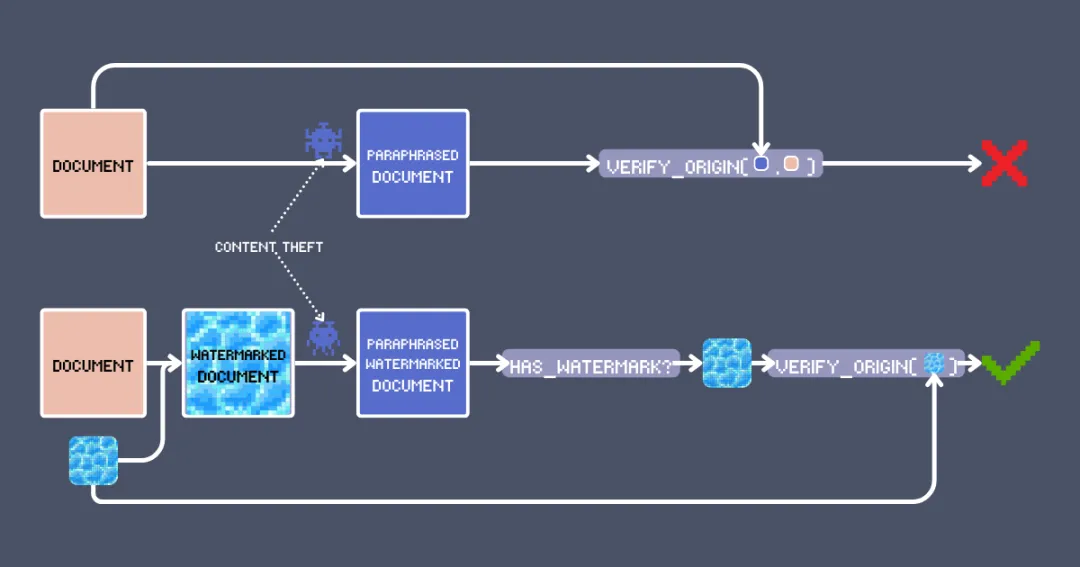
文本水印也一样,它在保留原文含义的基础上,嵌入了一种机器可检测的签名。但与修改图像像素不同,文本水印是在 语义空间(Semantic Space) 里进行操作,对内容进行细微修改。所以,有效的文本水印必须要满足以下几个关键要求:
接下来,我们来搭建一个基于向量模型的文本水印系统,系统里有两个阵营:验证者(Verifier)负责给原创内容加上水印,之后也负责检测水印,识别抄袭行为。攻击者(Adversary)则是试图修改文本,躲避水印检测。
首先,我们梳理一下系统的关键组件:
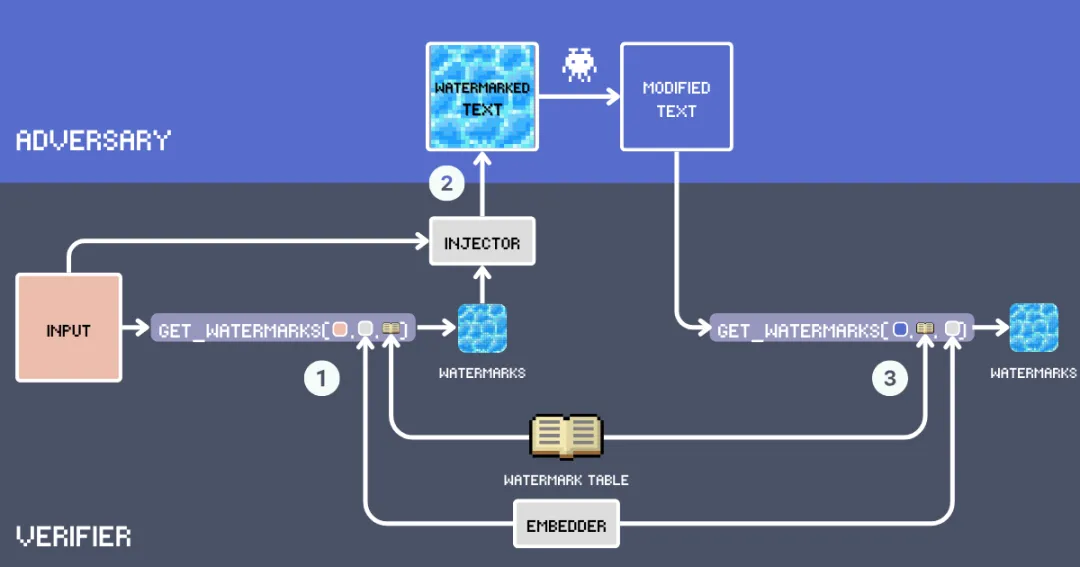
jina-embeddings-v3的强大之处在于它能出色地处理长文本和不同语言,即使是篇幅很长的文档或翻译成不同语言,我们也能有效地进行水印检测。
加水印的过程分为两步:首先,利用向量模型计算输入文本与水印表中每个词语的相似度,挑选出语义最接近的词语作为水印;然后,注入器将这些水印词自然地融入原文,生成加水印的文本。
检测过程也类似:首先在疑似抄袭的文本里,找出跟水印表里语义相似的词。然后,把提取出的水印词跟我们插入的原始水印进行比较。如果重合度很高,就说明该文本很可能是从我们的加水印文本衍生出来的。
注意,输入文本、水印表、向量模型和注入器都必须保密,以防攻击者破解水印机制。
我们实现了一个简化版的文本水印系统,主要用于概念验证。
> 完整的代码实现请参考 Google Colab:https://colab.research.google.com/drive/1sbIdU2tr-18sAtLvVVyhYtrIw2Cgjp8F
核心步骤如下:
1. 构建水印词表: 我们从英语学习网站上收集了大约 60 个高级词汇,作为潜在的水印词,构建了一个小型的水印词表。

2. 水印选择: 使用 jina-embeddings-v3 计算输入文本与水印表中每个词的余弦相似度,然后将相似度结果可视化,选择相似度最高的前三个词作为最终的水印词。
3. 水印注入: 使用 gpt4o 作为注入器,将水印词插入到原文中。使用的提示词模板如下,其中,[words] 指的是选定的水印词,[section] 指的是待插入水印的文本段落。
请将 [words] 插入到 [section] 中,同时保持最大的连贯性,并尽可能保留原始内容。
4. 模拟攻击:为了测试水印的鲁棒性,我们使用 gpt-4o 模拟了两种攻击场景:改写和翻译,分别使用了以下提示词模板:改写 [section] 和 将 [section] 翻译成中文。
注意:两种模拟攻击都只是简化版本,实际情况中的攻击方式可能更加复杂。本示例中,所有三个 LLM 生成服务都使用了 PromptPerfect 的“prompt-as-a-service”功能。 https://promptperfect.jina.ai/services
为了验证文本水印的效果,我们用 Jina AI 的公司介绍作为输入文本:
Founded in 2020 in Berlin, Jina AI is a leading search AI company. The future of AI is multimodal, and we are part of it. We recognize that businesses face challenges in leveraging multimodal data. In response, we provide the Search Foundation, the core infrastructure for GenAI and multimodal applications. Our mission is to help businesses and developers unlock the value of multimodal data through better search.
基于 jina-embeddings-v3 和预先定义的水印表,我们选出了三个水印词:adjoining、open-minded、inquisitive。
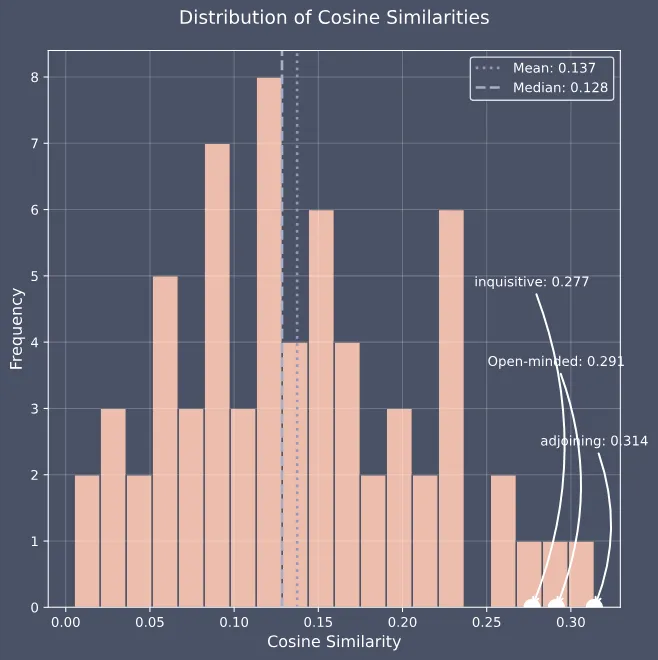
上图展示了如何选择水印词。图中横轴列出了水印表中的词,纵轴表示每个词与输入文本的余弦相似度,该相似度由jina-embeddings-v3模型计算得出。图中的虚线和点划线分别代表平均相似度和中位数相似度。三个白点标记了我们最终选择的三个水印词,它们与输入文本的语义相似度最高。
接着,注入器将这三个水印词插入到原文中,生成了以下带水印的文本:
Founded in 2020 in Berlin, Jina AI is a leading search AI company. The future of AI is multimodal, and we are part of it. We recognize that businesses face challenges in leveraging multimodal data. In response, we provide the Search Foundation, the core infrastructure for GenAI and multimodal applications. Our mission is to help businesses and developers unlock the value of multimodal data through better search. Adjoining our technical expertise is our open-minded and inquisitive approach, which drives our continuous innovation and commitment to solving complex problems.
我们模拟攻击者,对这段带水印文本进行了改写,得到了如下文本:
Established in Berlin in 2020, Jina AI is a prominent company specializing in search AI. Our team is characterized by our open-mindedness and curiosity, consistently aiming to expand the capabilities of AI. Believing that the future of AI lies in its multimodal potential, we are excited to be at the forefront of this evolution. We understand the interconnected challenges businesses encounter when utilizing multimodal data. To address these, we offer the Search Foundation, essential infrastructure for Generative AI (GenAI) and multimodal applications. Our goal is to assist businesses and developers in unlocking the full potential of multimodal data through enhanced search capabilities.
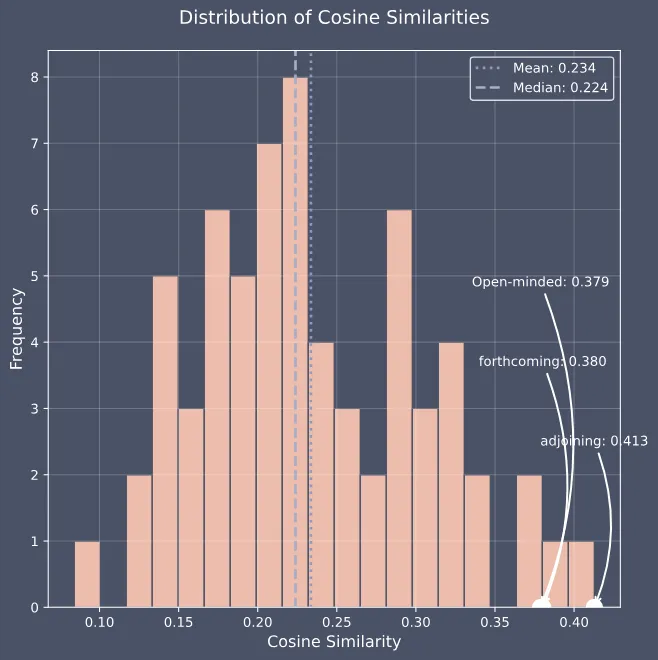
从这段改写后的文本中,我们提取出了前三个最重要的水印词:
adjoining: 0.413
forthcoming: 0.380
open-minded: 0.379
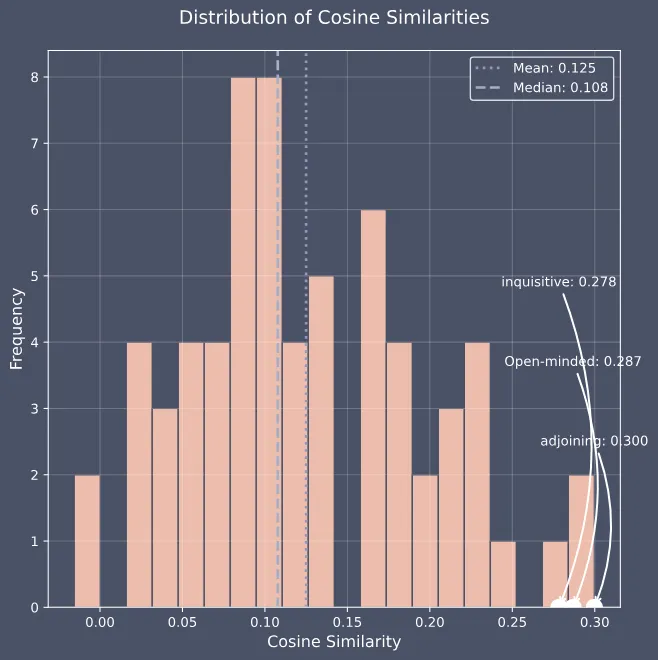
从转写文本中提取的水印词
可以看到,这三个词与我们最初添加的水印词完全一致,证明这段改写后的文本确实源自我们的原文。
我们还将带水印的文本翻译成了中文:
成立于2020年,Jina AI是一家领先的搜索AI公司。我们是一个开放且好奇心强的团队,始终努力突破AI的界限。AI的未来是多模态的,我们很自豪能够成为其中的一部分。我们意识到企业在利用多模态数据时会面临相邻的挑战。为此,我们提供Search Foundation,这是GenAI和多模态应用的核心基础设施。我们的使命是通过更好的搜索,帮助企业和开发者释放多模态数据的价值。
从这段中文翻译中提取出的最重要的三个水印词是:
adjoining: 0.413
forthcoming: 0.380
Open-minded: 0.379
从翻译中提取的水印词
可以看到,三个词中有两个(adjoining 和 Open-minded) 与我们最初添加的水印词相同,说明这段中文翻译很可能也源自我们的原文。
为了进一步验证该方法的有效性,我们再上点强度,使用《爱丽丝梦游仙境》第一章“Down the Rabbit-Hole”,共 2010 Token 作为输入文本,并重复了上述水印添加和检测过程。
三个水印词为:inquisitive、Deep-seated、Two-year-old
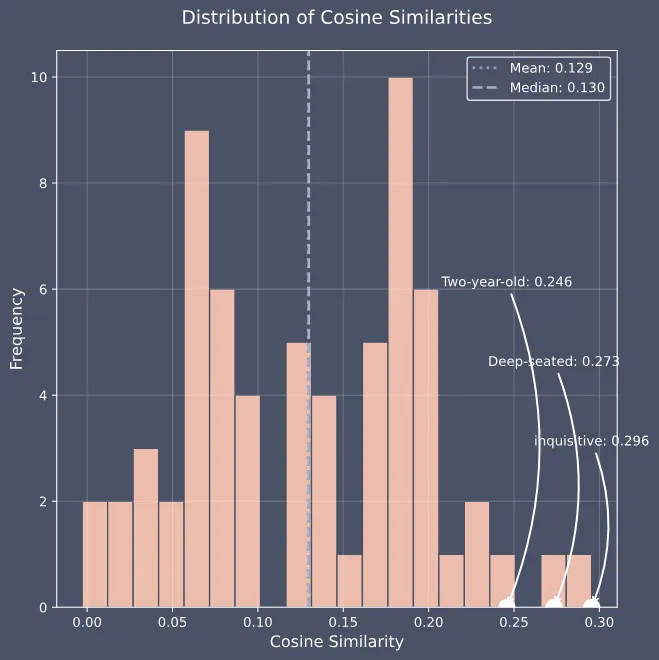
选择 3 个水印词

转写文本:3 个水印词全部匹配
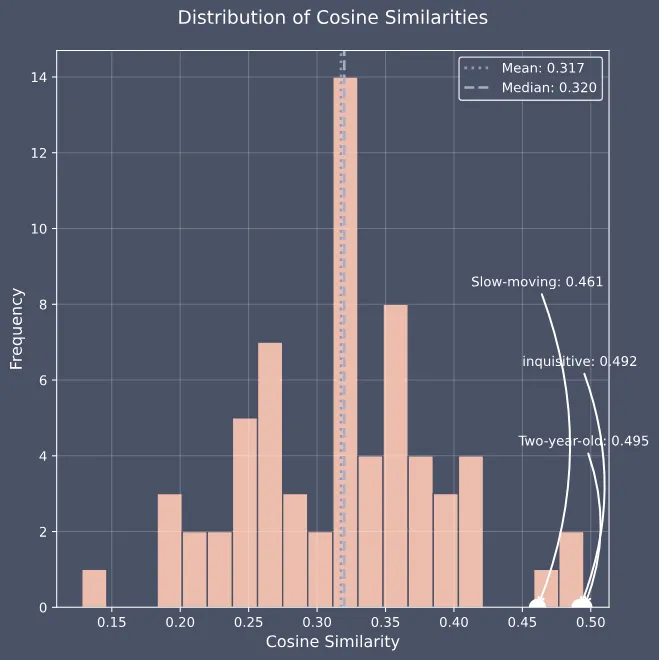
翻译文本:3 个水印词中 2 个匹配
通过上面的例子,我们发现即使在基础设置下,基于向量的水印也能实现相当的鲁棒性。Jina Embeddings v3 强大的多语言能力使得我们即使在文本被翻译后也能有效地检测水印。如果没有这种跨语言能力,要从翻译后的文本中检测水印将会非常困难。
当然,这个水印系统还有很多改进的空间。一个比较直接的思路是扩展水印表,更精细化地构建,以确保词表的多样性。一个更大、更丰富的词表可以更好地覆盖语义空间,从而更容易找到合适的词作为水印,同时降低水印重复或出现明显模式的风险。
另一个改进思路是优化注入器的插入策略。比如,可以让水印在文本中分布得更加均匀以提升隐蔽性。此外,还可以考虑结合新的技术,比如 迟分(Late Chunking),为不同的段落或句子生成更精细的水印,让注入器在放置水印时有更大的灵活性,兼顾不可见性和文本流畅度。
想要深入了解这方面内容的读者,推荐去看一看 “POSTMARK: A Robust Blackbox Watermark for Large Language Models”(Chang 等人,EMNLP 2024)这篇论文,里面有更全面的框架、数学公式和大量实验数据。作者系统地探讨了水印词表的构建、插入策略的优化、鲁棒性,以及水印检测和文本质量之间的平衡。
https://arxiv.org/abs/2406.14517
文章来自于“Jina AI”,作者“Jina AI”。




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
