# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在《星球大战》中,机器人R2-D2和其他机器人使用特殊的语言进行交流。
这种语言主要由蜂鸣声和口哨声组成,被称为「二进制语」(Binary)或「机器人语」(Droidspeak)。

Droidspeak是专门为机器人之间的交流设计的,只有机器人能够完全理解其精确含义。
电影中,C-3PO是唯一能够完全理解R2-D2语言的角色,而天行者等人类则是通过长期与R2-D2相处,逐渐能够猜测出它所表达的意思。

机器人之间的「专用」通信显然更加高效,那对于LLM来说,是否也应该如此?
近日,来自微软、芝加哥大学的研究人员推出了「Droidspeak」,让AI智能体之间可以用自己的语言进行交流:

论文地址:https://arxiv.org/pdf/2411.02820
结果表明,在不损失性能的情况下,Droidspeak使模型的通信速度提高了2.78倍。
所以,尽管人类用自然语言训练出了LLM,但用自然语言输出和交流,只是AI对于人类的一种「迁就」。
下面是喜闻乐见的读论文环节。
事先甩个锅,说「发明全新LLM语言」或有标题党之嫌,概括文章的思想,四个字足矣:缓存复用。
再具体一些:在很多智能体系统中,不同的Agents其实是同源的,大家从同一个base model微调而来,参数的差距并不大。
那么,相同的输入(经过差不多的weight)产生的计算结果也应该差不多。
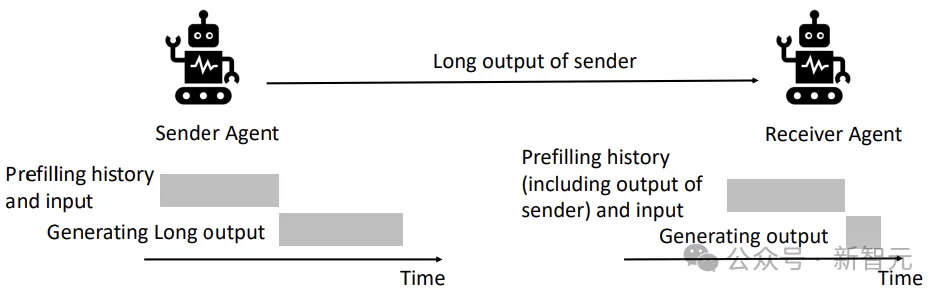
在智能体系统中,前一个Agent(sender)的输出,会作为后一个Agent(receiver)输入的一部分。
而这部分需要prefill的计算,在之前其实已经做过了,那对于receiver来说,是不是能直接把sender的计算结果拿过来?
——直接传递模型中间的计算结果(缓存),而不需要转换成人类能够理解的自然语言,这就是「Droidspeak」的含义。

如果您是相关领域研究者,看到这里基本就可以退出了,节约了您宝贵的时间。
(但是小编走不了,毕竟稿费是按字数算的......)
高端的食材往往只需要最朴素的烹饪方式,而简单的idea往往得来并不简单。
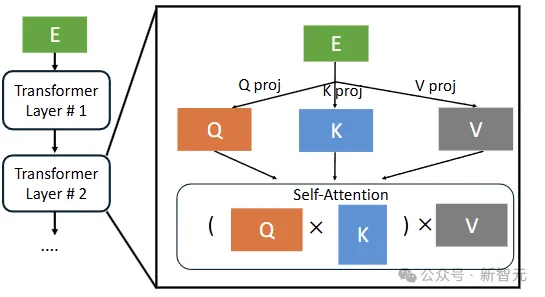
根据小学二年级学过的知识,LLM的推理可分为预填充(prefill)和解码(decode)两个阶段:
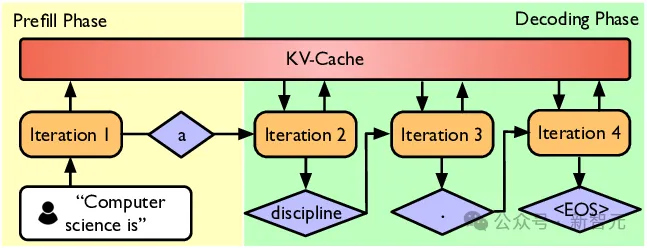
prefill是LLM拿你提出的问题(词向量序列),一股脑放进模型计算,填充所有层的kv cache;
而decode是用最后一个词作为query,开始一个一个词往外蹦。
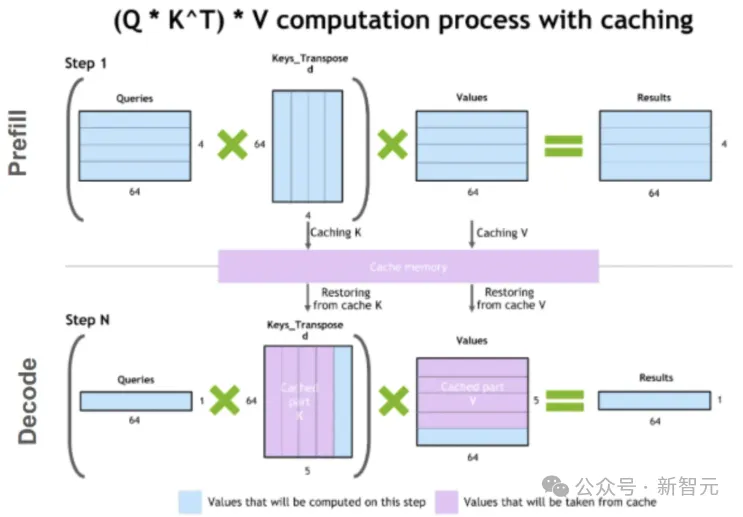
从计算的角度来看,预填充阶段是矩阵乘矩阵,为计算密集型;解码阶段是向量乘矩阵,相对来说访存变多。
当我们长时间运行上下文密集的对话时,prefill的占比会越来越高,包括计算和通信的开销。
所以在需要频繁交互的智能体系统中,prefill会成为瓶颈。
比如,在HotpotQA数据集中,Llama-3-70B-Instruct的平均预填充延迟为2.16秒,而解码时间只有0.21秒;
在MapCoder这种级联智能体系统中,前一个Agent的输出最多可达到38,000个token,从而导致极高的预填充延迟。
之前有工作探究过,利用kv cache来减少同一个模型的预填充延迟,这件事在智能体系统中貌似也能成立。
先测试一下亲子之间的相似度。
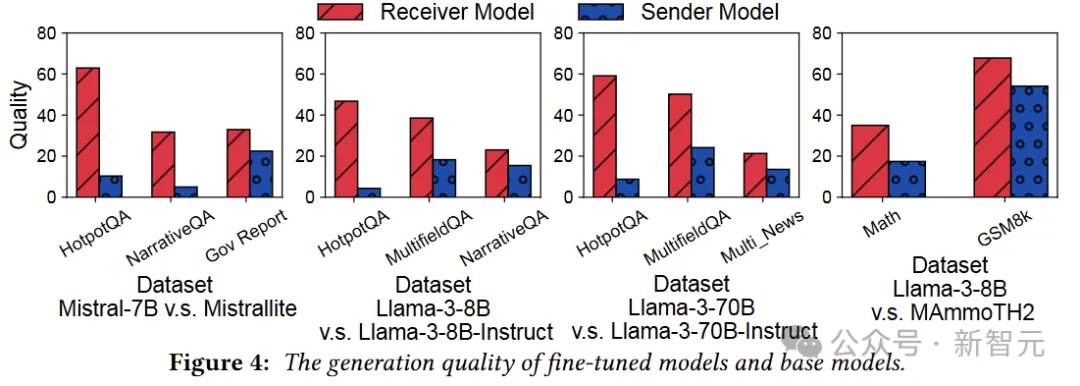
实验使用base model作为发送方,微调版本作为接收方,选择了下面四组模型。
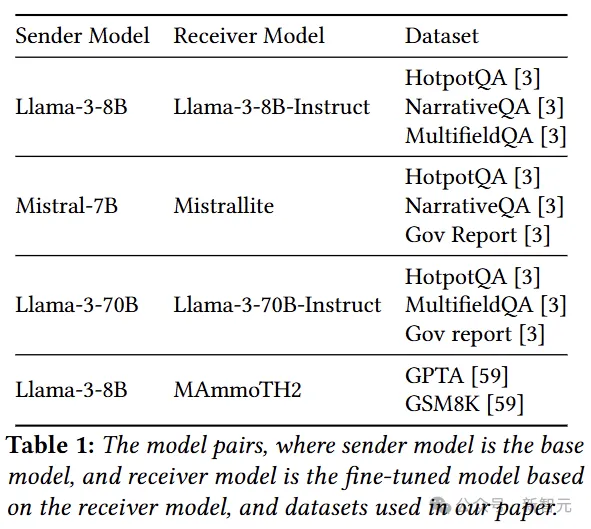
单从模型参数来看,绝对是亲生的,相似度差别都是小数点后三位的水平:
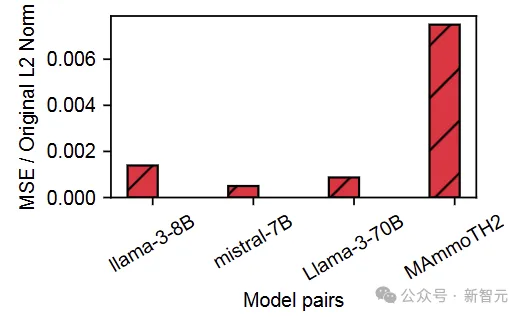
那么对于相同输入,中间的计算结果有多大差别?
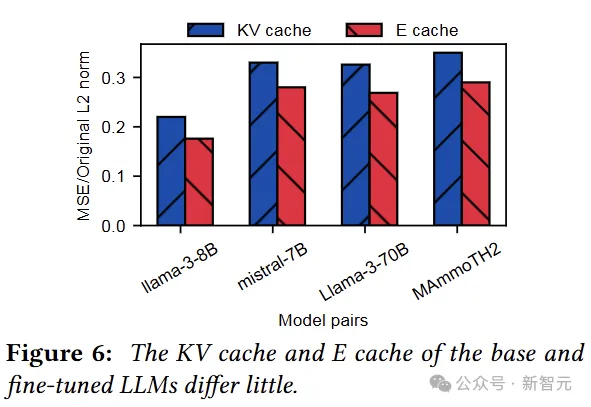
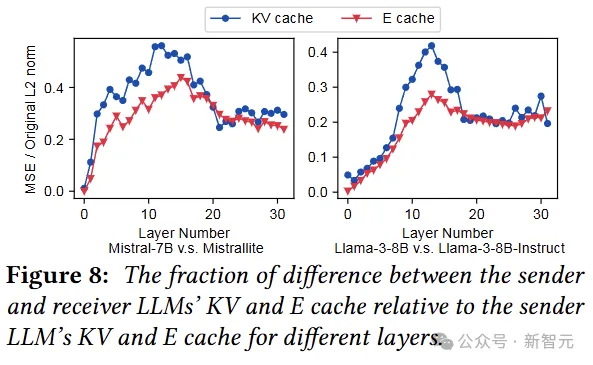
这里的E cache指的是每层的输入,即E通过投影矩阵计算出QKV。
相比于权重,每对模型的E cache和KV cache差别大了一点点,但也还好,那能不能直接复用呢?
在最初的实验构建中,要求微调版本在测试基准上的表现比基础模型好得多,以便测试出复用缓存带来的影响。
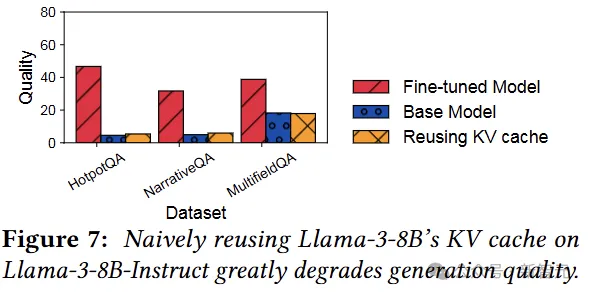
在此基础上,如果只是简单的复用全部的kv cache,效果稍显惨不忍睹,Fine-tuned Model的性能直接被打回原形:
看上去需要更加细致的操作,所以逐层分析一下E cache和KV cache的差别(注意是与base model的差别)。
因为缓存的差异因层而异,所以优化的应用也要按层来,这里首先考虑重用KV cache的连续层(直到最后一层)。
下图表明了重用KV cache带来的精度影响,效果很不错,但优化的自由度很低。
小编推测,这个「自由度低」的意思是:复用KV cache时,本层的输入(E cache)就不需要了,没有输入就没法算Q,就没法算下一层,所以后面也只能复用KV cache(直到最后一层)。
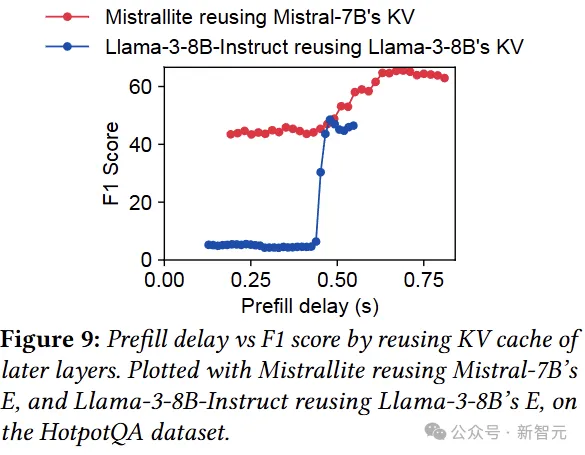
所以,作者接下来就测试复用E cache的情况,因为有输入可以继续往下算,所以复用E cache时可以选择任意的起点和终点。
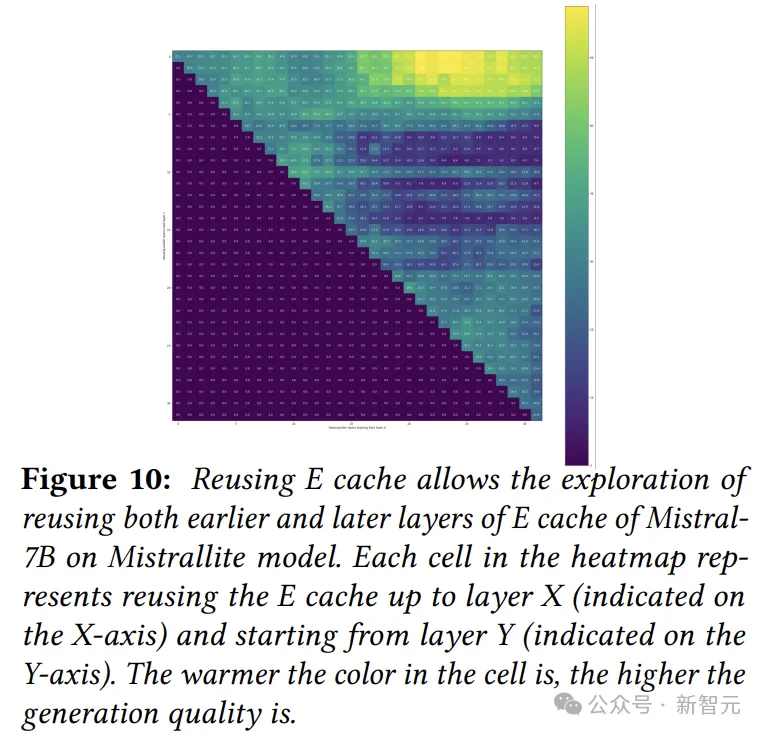
如下图所示,每个点代表在一定程度的预填充延迟下的最佳精度。
我们可以看到,重用E cache在保持生成质量的同时,将预填充延迟降低了1.8倍。
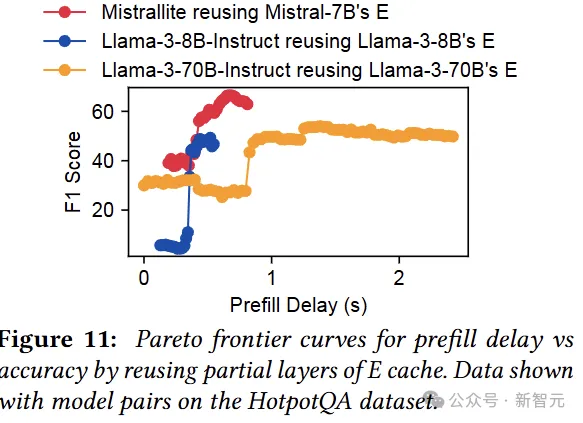
作者表示,尽管重用 E cache在层方面提供了极大的灵活性,但它会在GPU内存、传输和计算方面产生开销。
考虑发送方和接收方放置在两个GPU节点上,并通过Infiniband链路互连:
在发送方,E cache需要先存储在GPU内存中(内存开销),发送E cache到接收方会产生额外的传输延迟;
在接收端,还需要额外的QKV投影操作,将E cache转换为KV cache,这会导致额外的计算延迟。这三种类型的delay随着重用层的数量呈线性增长,如图12所示。
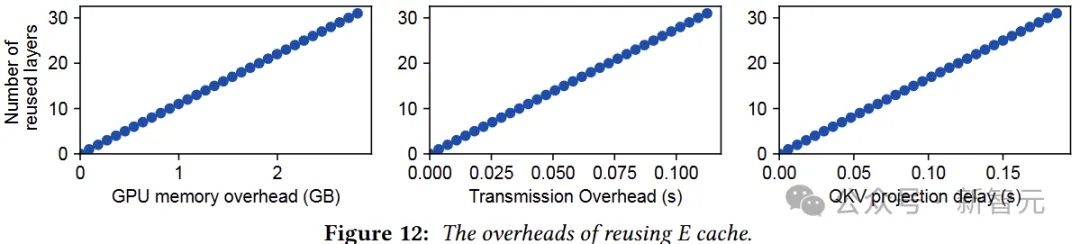
与之相对,重用KV cache没啥额外开销,只是缺乏灵活性。
所以,两种方法合体。
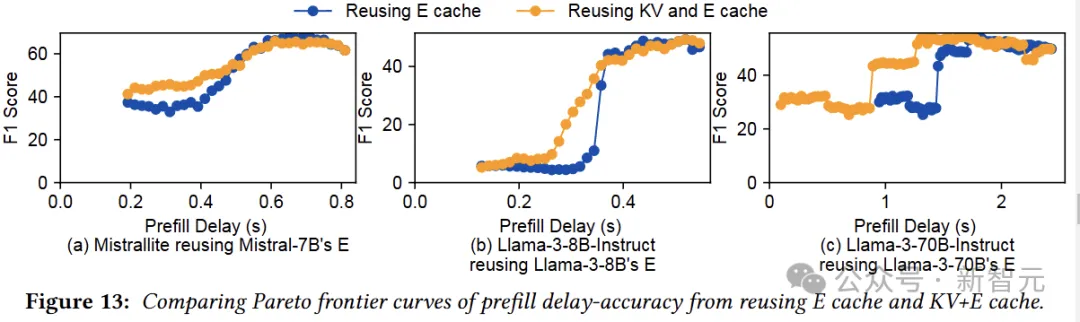
图13在预填充延迟和准确性权衡方面,比较了单独重用E cache与重用KV+E cache。
对于实验的三对模型,重用KV+E cache在延迟和准确性方面效果良好,且不会增加发送方的GPU内存开销或接收方的计算开销。
最后是端到端的整体架构:
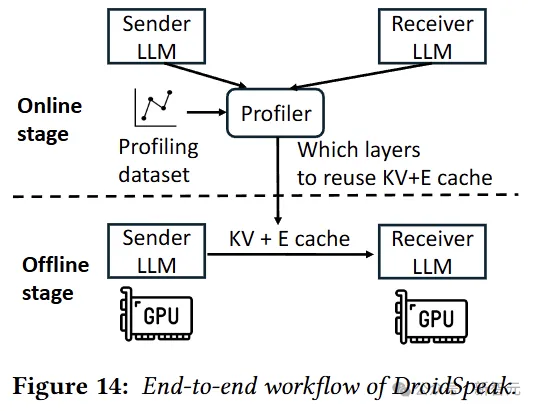
如图14所示,离线阶段,DroidSpeak首先在示例分析数据集上分析每对要重用的层(复用配置);
在线阶段,当发送方与接收方LLM通信时,会根据复用配置将KV和E缓存发送给接收方。
然后,接收方会为那些不重用KV缓存的层重新计算新的KV缓存。
下图展示了DroidSpeak相对于baseline的改进:
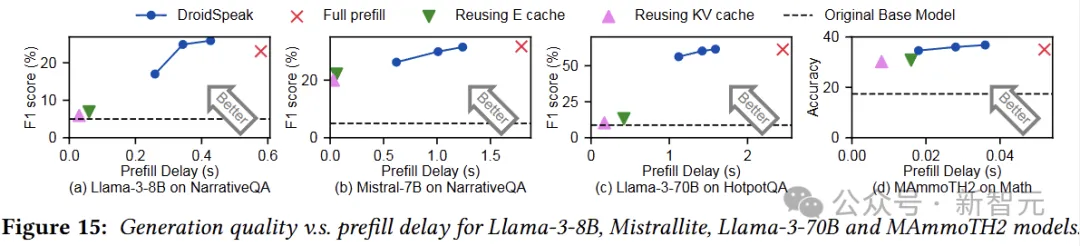
我们可以看到,与完全预填充相比,DroidSpeak的预填充延迟减少了1.69到2.77倍,而不会影响生成质量(重用所有E缓存或KV缓存时,生成质量会大大降低)。
水平虚线表示基础模型的生成质量,DroidSpeak的质量损失与基础模型和微调模型之间的差异相比微不足道。
参考资料:
https://singularityhub.com/2024/11/21/droidspeak-ai-agents-now-have-their-own-language-thanks-to-microsoft/
文章来自于微信公众号 “新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
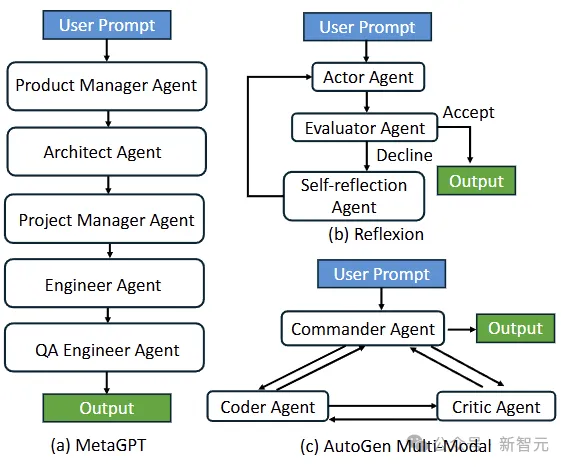
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
