# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
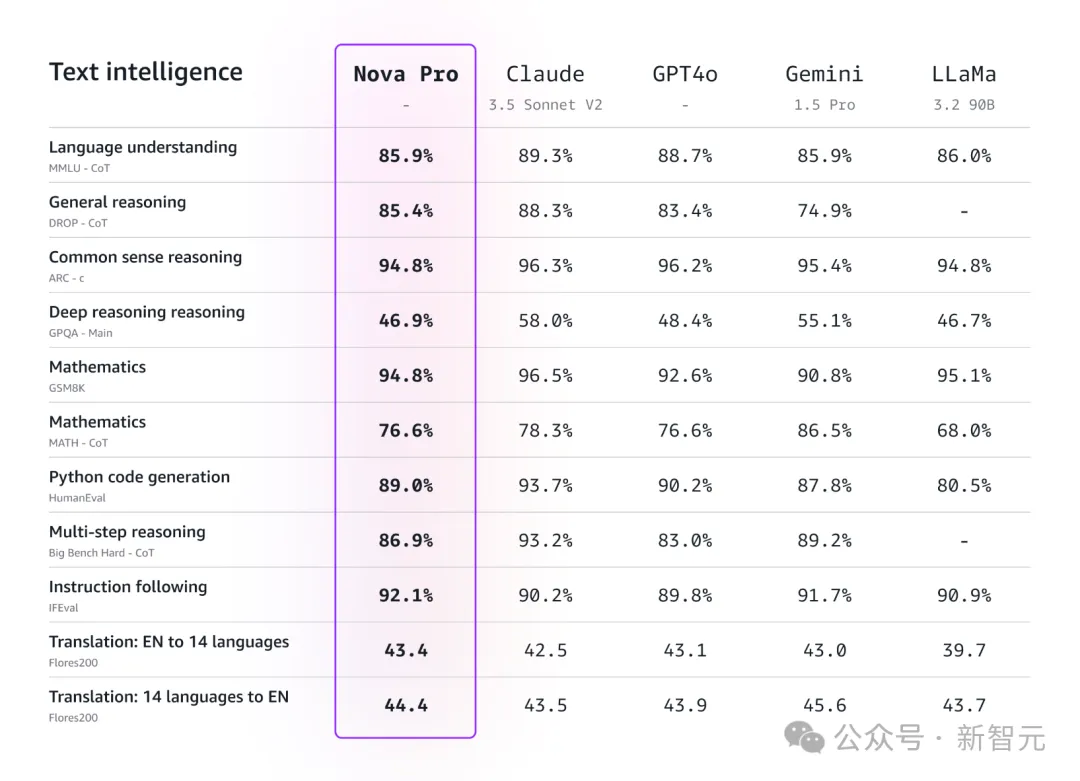
就在刚刚,亚马逊推出了号称最强大的多模态模型Nova系列。
在多项基准测试中,最强的Nova Pro成功超越了GPT-4o,仅次于Gemini 1.5 Pro、Claude 3.5 Sonnet。
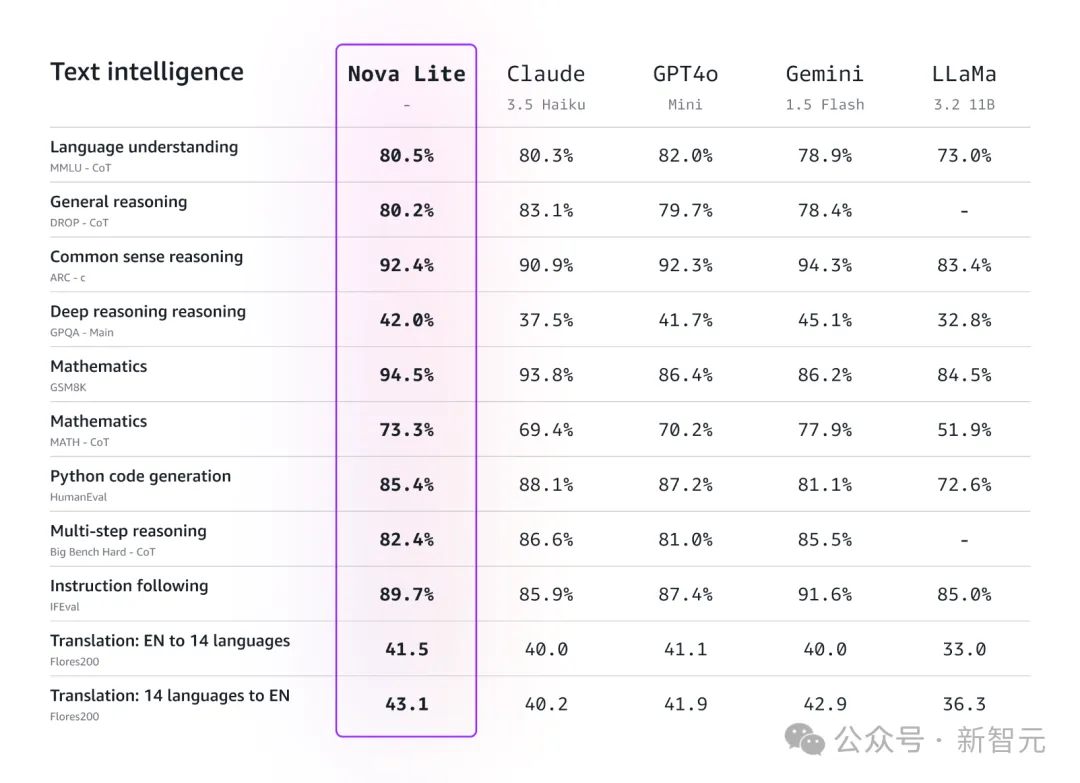
相较之下,Nova Lite和Nova Micro,就要比同级竞品差上不少了。

不过,它的价格非常便宜——每百万token的输入价格低至0.0175美元,输出价格低至0.07美元。

性能的提升,让Amazon Nova可以处理复杂推理任务。比如分析复杂文档、视频,理解图表、示意图,生成高质量的视频内容,还能构建高级AI智能体。
这次推出的Amazon Nova全家桶如下:

简单的提示「dolly forward」,Amazon Nova Reel就能将单个图像输入转换为简短视频
Amazon Nova的创意生成模型,直接让卖家和广告商的广告创意提升到全新的水平。
平均来看,使用这些工具的品牌广告宣传的产品数量直接增加了五倍,每个宣传产品使用的图片数量增加了一倍,这样就把预算省到了更需要的地方。
比如下面这个Amazon Nova Reel为某个虚构的意面品牌制作的广告,简直太惊艳了。

在一座「意大利面城」中,建筑由高耸的意大利肉卷面条管雕刻而成,街区点缀着意大利香料景观,街道两旁摆满了美味的马里纳拉酱、螺丝粉面条和嫩肉丸
Amazon Nova Pro的视频理解能力也是一绝。
研究者要求模型观看一场足球比赛的无声视频片段,然后把比赛内容描述一遍。
结果,模型一口气准确说出了赛制、球服、球员行动描述以及比赛如何达到高潮的详细信息!

视频描绘了一场在绿地上正在进行的足球比赛。两队的球员,一队身穿黄色队服,另一队身穿白色队服,正在比赛。黄队四分卫将球传给接球手,接球手接住球并开始向前跑动。白队的防守队员追赶他,试图阻止他。这场比赛的高潮是一次铲球,将接球手放倒在场上
接下来,我们详细看一下全家桶中几大成员的详细信息。
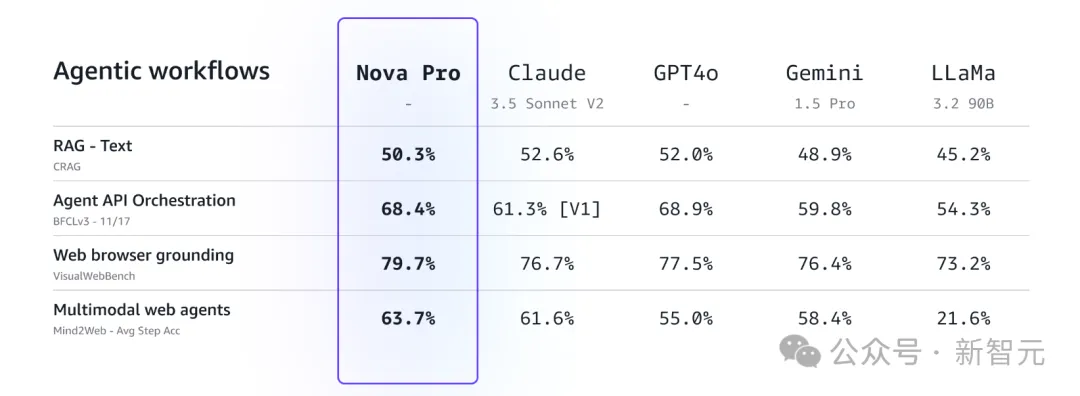
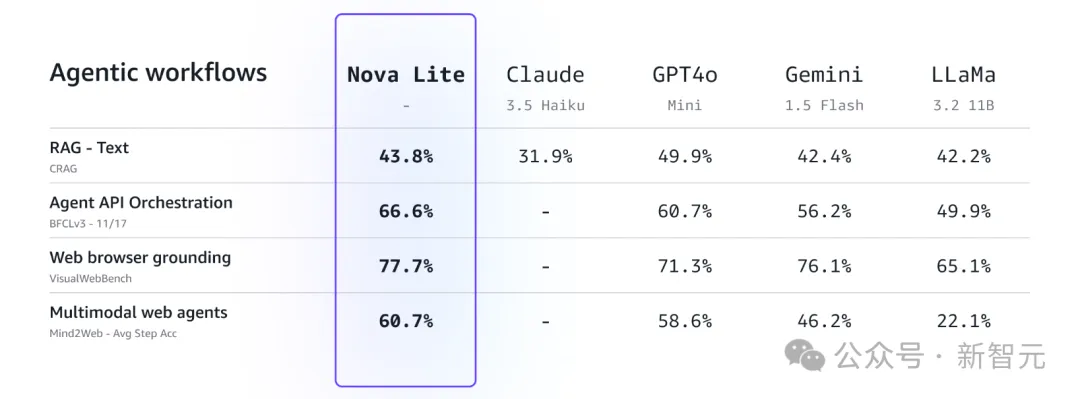
Amazon Nova Pro能够处理多达30万个输入token,并为多模态智能体工作流设定了新标准,这些工作流需要调用API和工具来完成复杂的工作流。
使用Amazon Nova模型执行智能体工作流:智能体可以规划并执行多步动作,利用浏览器和基于屏幕的用户界面作为通用工具来自动化终端客户的任务
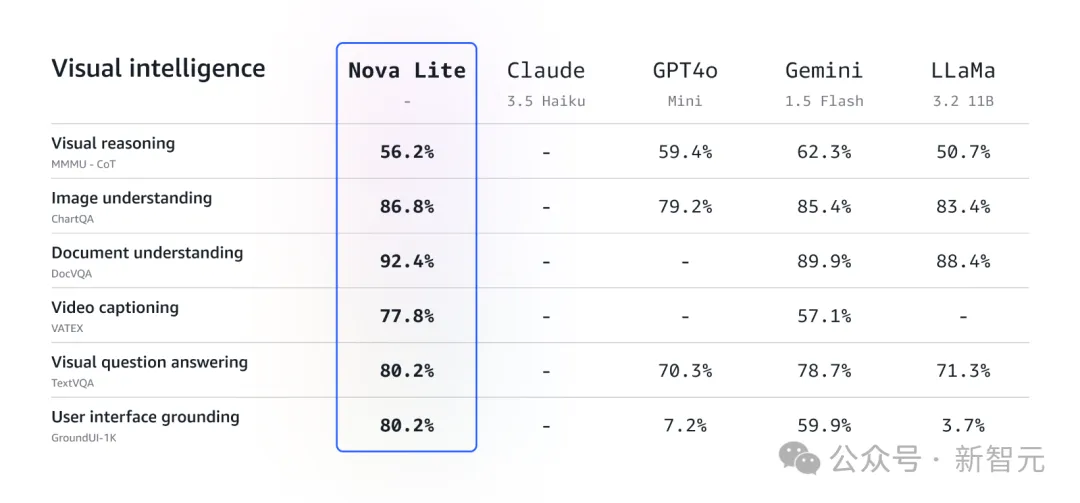
它在视觉问题解答(TextVQA)和视频理解(VATEX)等关键基准上都实现了最先进的性能。
在输入300K token的情况下,它可以处理超过一万五千行代码的代码库。Amazon Nova Pro还可作为教师模型,用于蒸馏Amazon Nova Micro和Lite的自定义变体。






Amazon Nova Lite可以高精度处理实时客户交互、文档分析和可视化问题解答任务。
该模型可处理长达300K token的输入,并能在单次请求中分析多张图像或长达30分钟的视频。
Amazon Nova Lite还支持文本和多模态微调,并可通过模型蒸馏等技术进行优化,为用户的使用案例提供最佳的质量和成本。
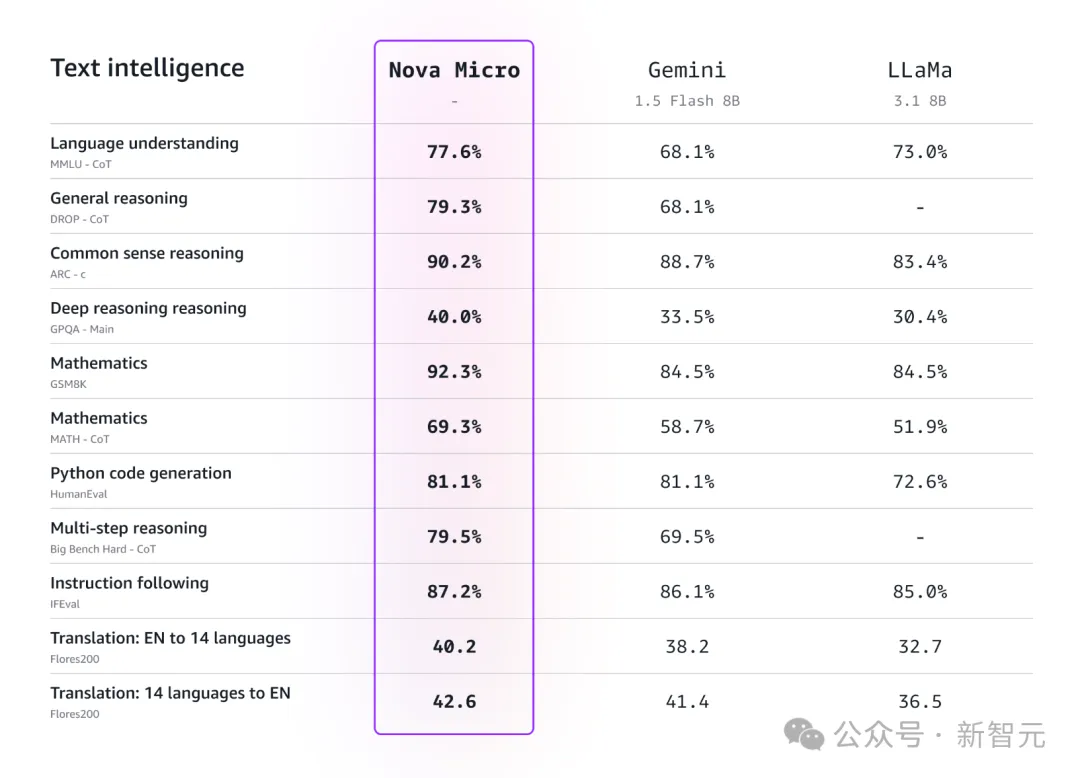
Amazon Nova Micro的上下文长度为128K,并针对速度和成本进行了优化,在文本摘要、翻译、内容分类、交互式聊天和头脑风暴以及简单的数学推理和编码等任务中表现出色。
Amazon Nova Micro还支持使用微调和模型蒸馏对专有数据进行定制,以提高准确性。

Amazon Nova系列还包括两款创意内容的生成式模型,Amazon Nova Reel和Amazon Nova Canvas。
这是一个先进的图像生成模型,可生成工作室水准级别的图像,并可精确控制样式和内容,包括丰富的编辑功能,如修复、扩图和背景移除。

Amazon Nova Reel支持用户通过文本提示和图像来控制视觉风格和节奏,并生成专业品质的视频内容,用于营销、广告和娱乐。

Amazon Nova Micro、Amazon Nova Lite和Amazon Nova Pro的价格,比Amazon Bedrock中各自智能类别中性能最佳的模型至少还要便宜了75%。
而且,它们也是相比之下最快的模型。
这些模型与Amazon Bedrock集成,是一项支持完全托管的服务,可通过单个API使用来自领先AI公司和亚马逊的高性能基础模型。
而且,模型还支持自定义微调,允许客户将模型指向自己专有数据中的示例,因为这些示例已被标记,所以提高了准确性。
这样,Amazon Nova模型可以从客户自己的数据(包括文本、图像和视频)中了解对客户最重要的内容,然后由Amazon Bedrock训练一个私人微调模型,提供量身定制的响应。

除了支持微调之外,这些模型还支持蒸馏,从而能够将特定知识从更大、能力更强的「教师模型」转移到更小、更高效的模型,后者不仅高度准确,而且运行速度更快、成本更低。
并且,Amazon Nova模型与Amazon Bedrock知识库集成,还擅长RAG,就能让响应基于客户组织的内部数据,来保证最佳的准确性。
因为模型已经过优化,在代理性应用中非常易于使用,还能通过多个API与组织的专有系统和数据进行交互,从而执行多步骤任务。
在当下最炙手可热的AI芯片赛道中,挑战者们正上演着一场激烈的「造芯」革命。
据市场研究机构Omdia的数据显示,在人工智能计算领域,数据中心运营商在非英伟达芯片计算机上的支出预计将于今年增长49%,总额达到1,260亿美元。
这个数字,无疑释放出了芯片市场潜力无限的信号。
多年来,英伟达在AI芯片领域一家独大,尽管其他公司不断尝试,但始终未能撼动其霸主地位。
但如今,局面正在发生改变。「推理计算」成为这场AI技术革命的关键词。
无论是科技巨头,还是小型初创,瞄准了为AI研发定制芯片的赛道,比如Groq、Cerebras Systems等等。
Meta就是一个典型案例。虽然他们使用英伟达芯片训练了Llama3.1 405B,但在实际为用户提供服务时,采用的是AMD MI300s芯片。

不仅如此,这些新晋玩家们从英伟达身上学到了一课:单纯卖芯片完全不够了。他们开始筹谋提供完整的计算方案,让客户充分发挥AI芯片的最大潜能。
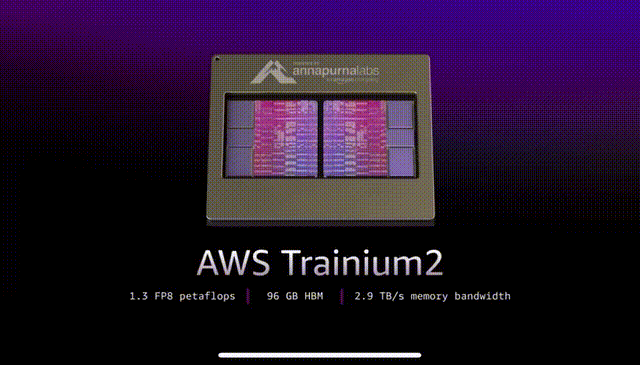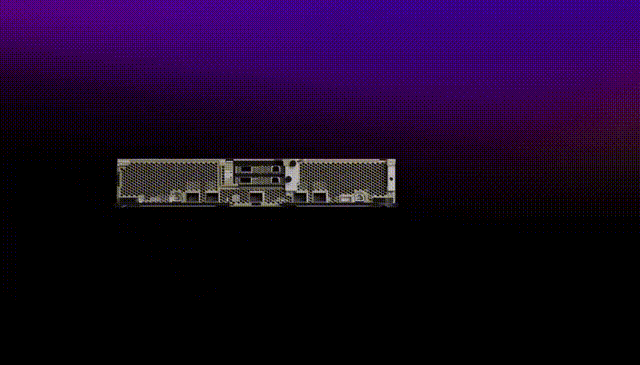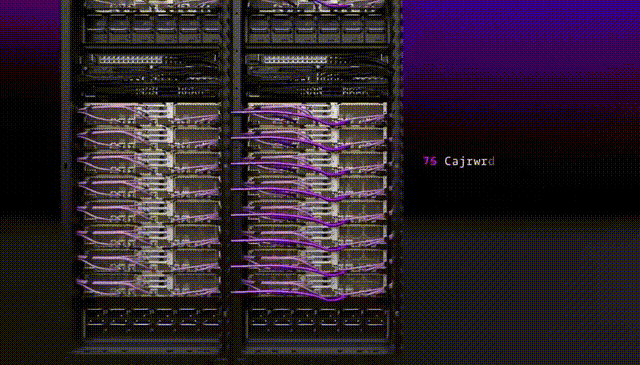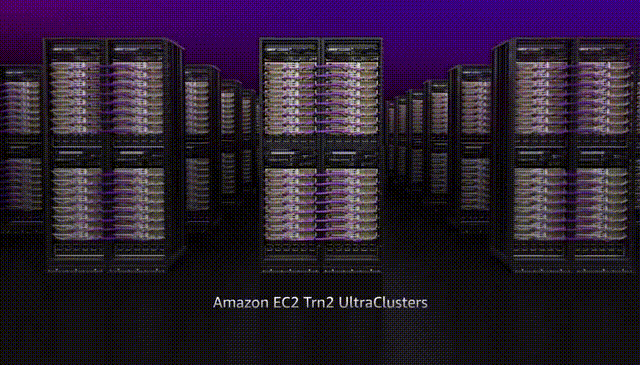
比如,AWS就在刚刚举办的re:Invent大会上,宣布了基于Trainium2芯片的计算服务正式上线。并同时公布了性能更为强大的Trainium 3芯片的研发计划。
Amazon EC2 Trn2 UltraServers是全新推出的EC2产品,配备64个互联的Trainium2芯片。
它由四台服务器构成,每台服务器装配16枚Tranium芯片。(英伟达最多为8枚)

Trainium2
服务器之间使用超高速的NeuronLink互连,最大可扩展到83.2个峰值千万亿次计算(petaflops),是单个实例计算、内存和网络能力的四倍,这使得训练和部署全球最大模型成为可能。
亚马逊表示,这已经是Ultraserver在保证散热安全的前提下所能达到的最大配置。

Amazon EC2 Trn2 UltraServers(测试单元)
这些还不够,AWS正在和Anthropic合作进行「Ultracluster」超级计算机计划。
他们正在构建一个由Trn2 UltraServers组成的EC2 UltraCluster,并将其命名为「Project Rainier」。
这个被命名为「Project Rainier」的集群配备数十万个Trainium2芯片,计算能力是当前领先AI模型训练需求的五倍多。
AWS计算和网络服务部门副总裁戴夫·布朗透露,这个集群将建设在美国境内,预计在2025年投入使用。
它将跻身全球最大规模的AI模型训练集群之列。
虽然亚马逊早期推出的AI芯片,包括第一代Trainium在内,并未在市场上获得显著反响。
但是对于新一代的Trainium2芯片,亚马逊展现出了更强的信心——其运算速度较前代产品提升了四倍。
并且,苹果也将成为其最新芯片客户之一。

类似的,AMD也宣布将于明年推出新一代AI芯片,直接与英伟达的Blackwell系列展开竞争。
目前,工程师们已经开始对芯片进行全方位的测试。

一年前发布的MI300的AI芯片,当年就创造了超500亿美元销量
与此同时,谷歌、微软和Meta等科技巨头也都在开发自己的人工智能专用芯片,旨在提升特定计算任务的处理速度并降低运营成本。
本月,谷歌将开始推出基于其第六代自研芯片Trillium的云服务,该芯片的性能较前代产品提升了近5倍。
不过,这些公司仍在使用英伟达芯片构建大规模计算集群。
尽管AI芯片新秀们群雄逐鹿,但这并不意味着英伟达即将会失去霸主地位。
黄仁勋曾在斯坦福大学演讲台上,掷地有声地表示,「即便竞争对手的芯片免费赠送,在性价比上仍然无法与我们相提并论」。
这句话,道出了英伟达十足的底气。
毕竟,如今市场中,在人工智能软件和推理计算方面,能打的芯片非英伟达莫属。
黄仁勋进一步指出,虽然新一代Blackwell人工智能芯片的能耗有所提升,但其单位能耗的计算效率大幅提高。目前市场对这款芯片的需求异常火爆。
另有据场研究机构IDC统计数据佐证了这一点。
数据显示,2024年全球人工智能半导体市场规模预计将达到1,175亿美元,并预计在2027年底进一步扩大至1,933亿美元。
IDC在2023年12月发布的最新研究报告显示,英伟达当前在AI芯片市场中占据着约95%的主导地位。

参考资料:
https://www.nytimes.com/2024/12/03/technology/nvidia-ai-chips.html
https://www.wsj.com/articles/amazon-announces-supercomputer-new-server-powered-by-homegrown-ai-chips-18c196fc
https://aws.amazon.com/cn/ec2/ultraclusters/
https://x.com/ArtificialAnlys/status/1864023052818030814
文章来自微信公众号“新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
