# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

长文本向量模型能够将十页长的文本编码为单个向量,听起来很强大,但真的实用吗?
很多人觉得... 未必。
直接用行不行?该不该分块?怎么分才最高效?本文将带你深入探讨长文本向量模型的不同分块策略,分析利弊,帮你避坑。
首先,让我们看看将整篇文章压缩成单一向量会存在哪些问题。
以构建文档搜索系统为例,单篇文章可能包含多个主题。 比如这篇关于 ICML 2024 参会报告的博客,就包含会议介绍、Jina AI 的工作展示 (jina-clip-v1) 以及其他研究论文总结。如果将整篇文章向量化成单一向量,该向量将混合三个不同主题的信息:
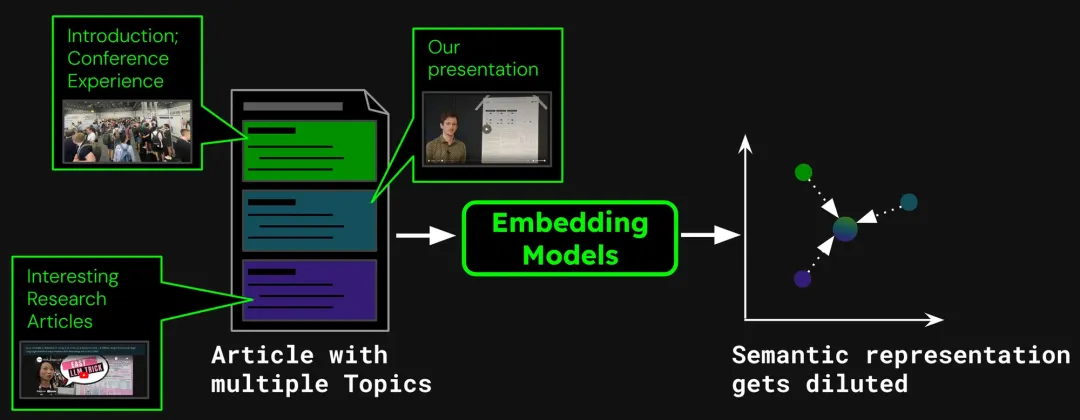
这会导致以下问题:
1. 表示稀释(Representation Dilution)
表示稀释会削弱文本向量的精度。虽然博客文章包含了多个主题,但用户的搜索查询往往只关注其中一个。用单个向量表示整篇文章,相当于将所有主题信息压缩到向量空间中的一个点。随着更多文本添加到模型的输入中,这个向量会逐渐代表文章的整体主题,稀释特定段落或主题的细节。这就像把多种颜料混合成了一种颜色,用户想找到某种特定颜色时,就很难从混合色中识别出来。
2. 容量有限
模型生成的向量维度是固定的,长文本包含大量信息,转化过程中必然会导致信息损失。就好比把高清地图压缩成邮票,很多细节都看不清了。
3. 信息丢失
很多长文本模型最多只能处理 8192 token。更好的文本得截断一部分,通常是截断后面的内容,要是关键信息在文档末尾,就可能导致检索失败了。
4. 分块需求
有些应用只需要对文本的特定片段做向量化处理,比如问答系统,只需提取包含答案的段落进行向量化。这种情况下,还是需要对文本进行分块处理。
在实验开始之前,为了避免概念混淆,我们首先定义三个分块的策略:
1. 不分块(No Chunking):将整个文本直接编码成单一向量。
2. 朴素分块(Naive Chunking):先将文本分成多个文本块,并分别进行向量化。常用的方法有固定大小分块,将文本分割成固定 token 数量的块;基于句子的分块: 以句子为单位进行分块;基于语义的分块: 根据语义信息进行分块。在本次实验,使用的是固定大小分块。
3. 迟分(Late Chunking):是一种先通读全文再分块的新方法,包含两个主要步骤:
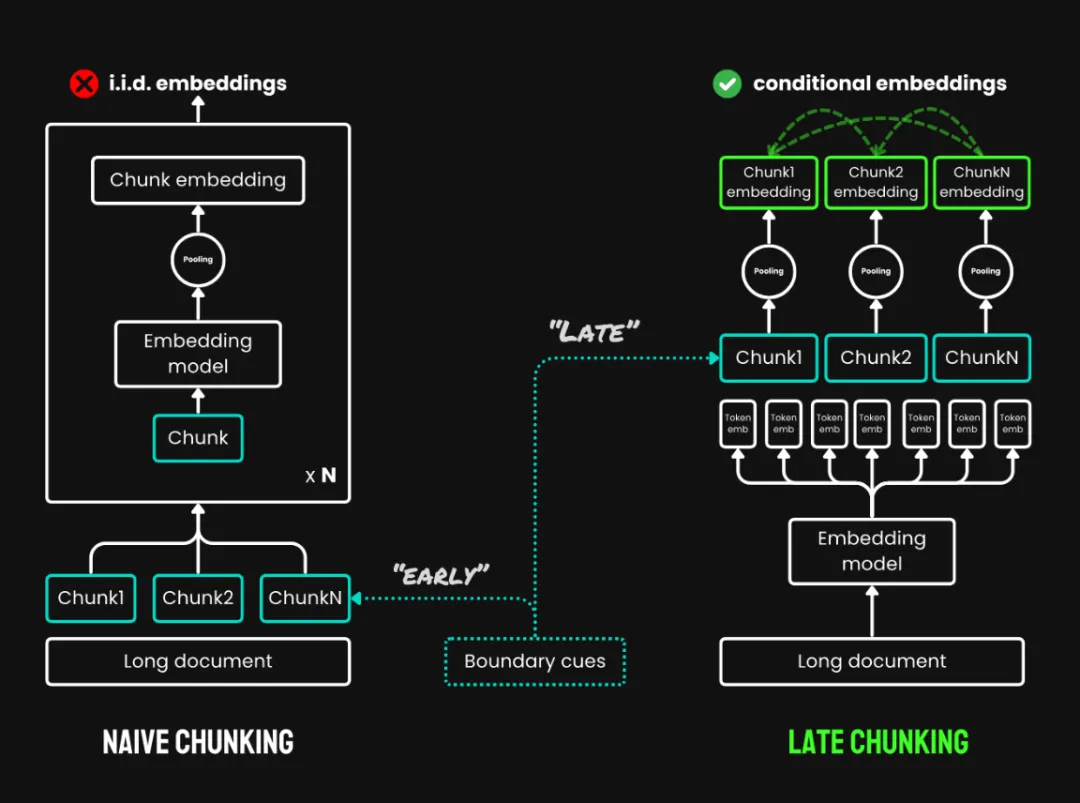
迟分与朴素分块的对比
对于超过模型最大输入长度 (例如 8192 tokens) 的超长文本,我们采用 长文本迟分(Long Late Chunking),在迟分的基础上增加了预分割步骤,先将文档分割成多个重叠的宏块,每个宏块的长度都在模型可处理范围内。然后,在每个宏块内部应用标准的迟分策略(编码和池化)。宏块之间的重叠部分用于确保上下文信息的连续性。
迟分具体实现代码:https://github.com/jina-ai/late-chunking
在 Notebook 体验:https://colab.research.google.com/drive/1iz3ACFs5aLV2O_uZEjiR1aHGlXqj0HY7?usp=sharing
为了对比,我们在 5 个数据集上,使用 jina-embeddings-v3 进行了实验,所有长文本都被截断至模型最大输入长度 (8192 Tokens),并按每 64 个 Token 为一个文本块进行分割。

5 个测试数据集也对应 5 种不同的检索任务
下图展示了 3 种方法在不同任务上的表现差异,并没有一种方法在所有情况下都最好,选择哪种方法取决于具体的任务。
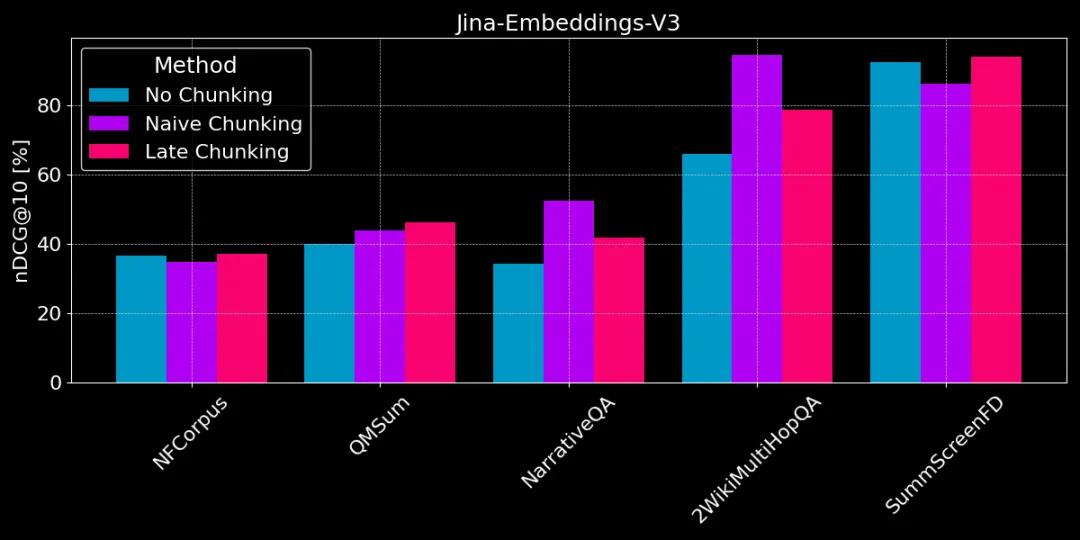
不分块 vs 朴素分块 vs 迟分
👩🏫 找具体事实,朴素分块好。
如果需要从文本中提取具体的、局部的事实信息(例如,“谁偷了东西?”),像 QMSum、NarrativeQA 和 2WikiMultiHopQA 这几个数据集,朴素分块比把整个文档向量化表现要好。因为答案通常位于文本的某个特定部分,朴素分块能够更精准地定位到包含答案的文本块,而不会被其他无关信息干扰。
但是朴素分块也会因为切断了上下文,可能丢失全局信息,无法正确解析文本中的指代关系和引用。
👩🏫 文章主题连贯,迟分更好。
如果文章主题很清晰,且篇章结构连贯,迟分方法会更有效。因为迟分考虑了上下文,能更好地理解每个部分的意义和关联,包括长文本里面的指代关系。
但如果文章里夹杂着很多和主题无关的内容,迟分反而会因为考虑了这些“噪音”导致性能回退,准确率下降。像 NarrativeQA、2WikiMultiHopQA,迟分表现不如朴素分块,就是因为这些文章里无关信息太多了。
下图展示了不同分块大小下,朴素分块和迟分方法在不同数据集上的表现:
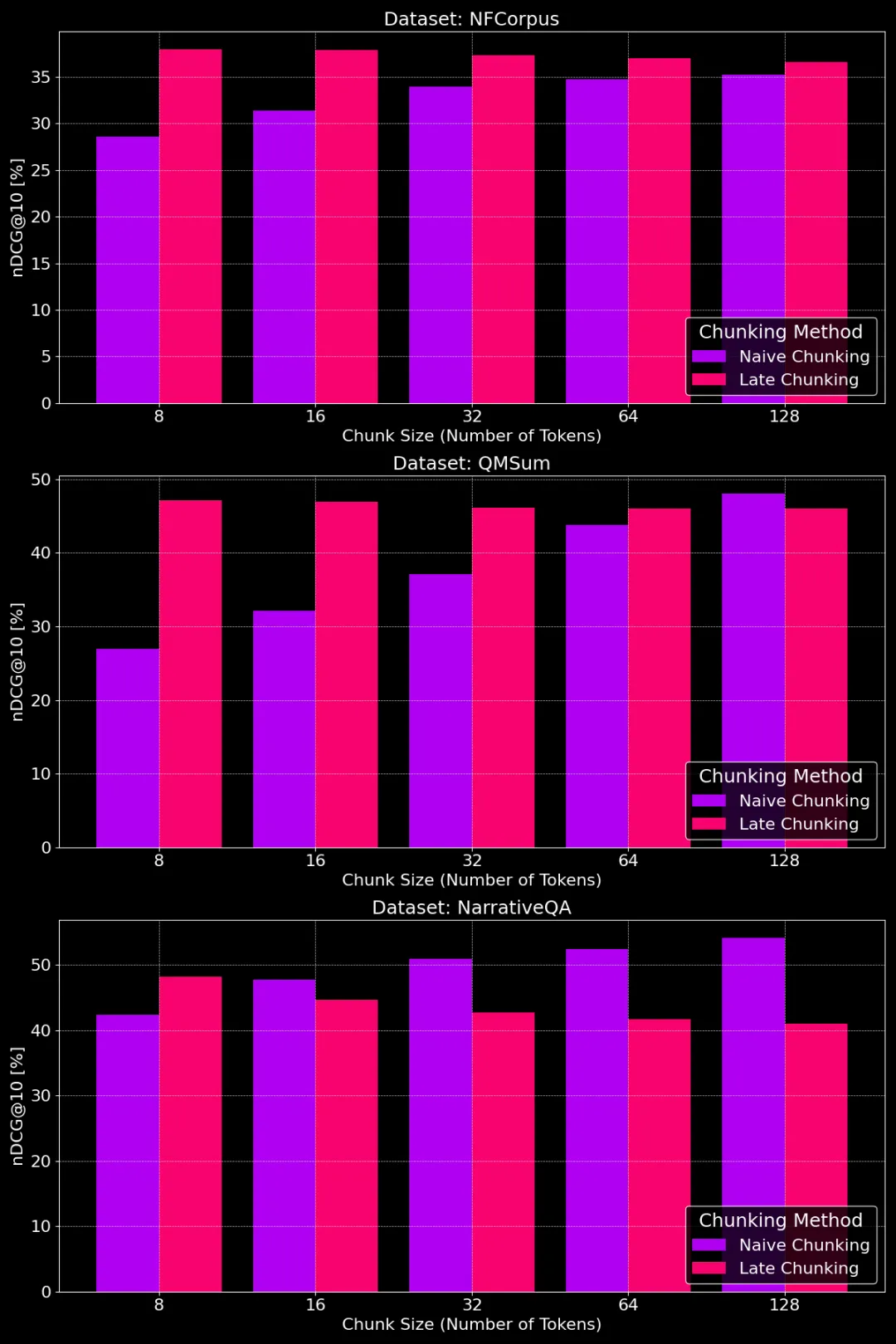
不同分块大小下朴素分块和迟分的性能对比
从图中我们可以看出,最佳的分块大小其实要看具体的数据集是什么样的。
对于迟分方法,较小的分块能更好地抓住上下文信息,所以效果更好。尤其是,如果数据集里有很多和主题无关的内容(就像 NarrativeQA 数据集那样),过大的上下文反而会引入噪音,损害性能。
对于朴素分块,大一些的分块有时效果会更好,因为包含的信息更全面,损失也更小。但有时候,分块太大,信息又太杂乱,反而降低了检索的准确性。所以,最佳的分块大小,需要根据具体的数据集和任务来调整,没有一个一刀切的答案。
理解了不同分块策略的优缺点后,我们该如何选择合适的策略呢?
1. 全文向量化(不分块)适合哪些情况?
2. 朴素分块(Naive Chunking)适合哪些情况?
3. 迟分(Late Chunking)适合哪些情况?
长文本向量化策略的选择是一个复杂的问题,没有一刀切的最佳方案,需要考虑数据特点和检索目标,包括前面提到的文本长度、主题数量、关键信息位置。
本文希望提供一个关于不同分块策略的比较分析框架,并通过实验结果提供了一些参考。在实际应用时,大家可以多对比实验,选择最适合自己场景的策略。
如果你对长文本向量化感兴趣,jina-embeddings-v3提供了先进的长文本处理能力、多语言支持以及迟分功能,值得尝试。
🔗 https://jina.ai/embeddings
🤗 https://huggingface.co/jinaai/jina-embeddings-v3
文章来自微信公众号“Jina AI”,作者“Jina AI”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
