# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国产大模型刚刚出了一位全新选手:
参数670亿的DeepSeek。
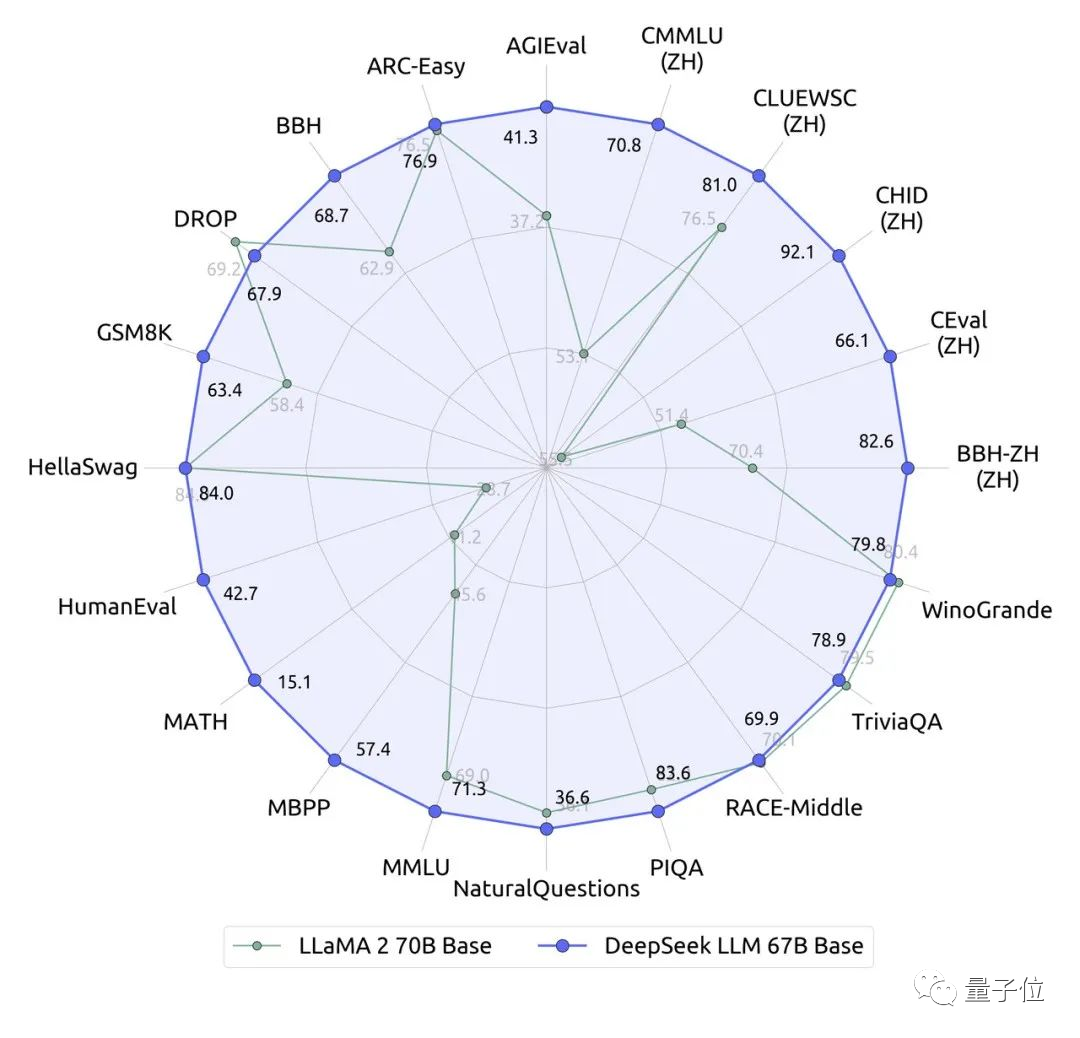
它在近20个中英文的公开评测榜单上直接超越了同量级、700亿的Llama 2。
并尤其以推理、数学和编码能力为突出。
其中在数学能力上,它测了Grok刚刚参与过的匈牙利今年最新的高中数学考试题,得了65分。
对比Grok当时公布的成绩:59分,以及GPT-4的68分,表现十分出色。
DeepSeek主打一个发布即开源:
共包含70亿和670亿两个参数版本,每个版本均含基础模型和指令微调模型,无需申请,即可免费商用。
同时,它已开放了全面内测,注册一下就能玩。
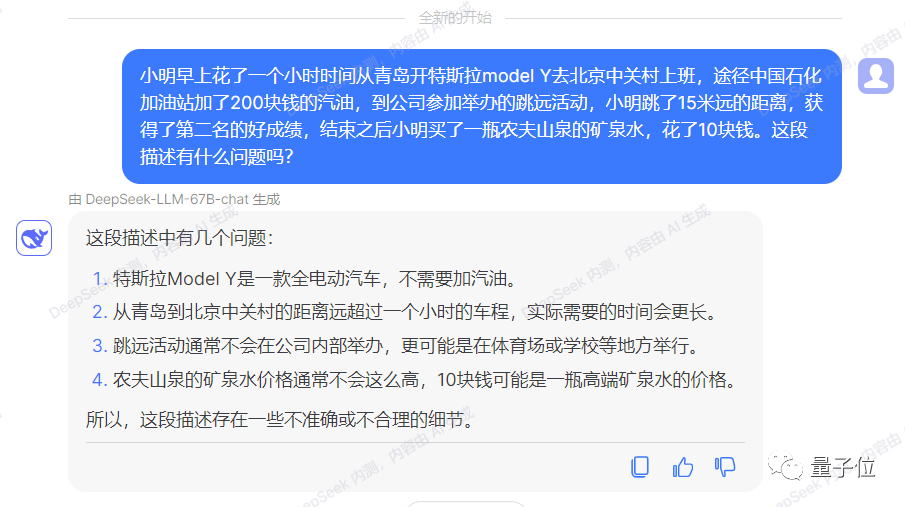
Ps. DeepSeek的中文能力在GPT-3.5之上,可以使用中文进行测试。
在推特上,DeepSeek也引起了一大批技术同行的关注:
早期测试过的人表示没毛病。
还有人赞誉DeepSeek弥补了开源LLM在数学和编码上的短板。
那么,DeepSeek是如何训练出来的?
DeepSeek使用与Llama相同的架构,即自回归Transformer解码器架构。
其中70亿参数的版本使用多头注意力,670亿参数版本使用分组查询注意力。
预训练在包含2万亿个中英文token的数据集(序列长度4096)和AdamW优化器上进行。
其中70亿参数版本的模型的训练batch size为2304,学习率为4.2e-4;670亿参数版本的模型的batch size为4608,学习率为3.2e-4。
DeepSeek的训练过程中特别采用了多步学习率计划:
先从2000个预测步骤开始,然后在1.6万亿token时逐步达到最大值的31.6%,在1.8万亿token时逐步达到最大值的10%。
有网友看完表示:
这种从1.6万亿token时开启的学习率冷却阶段有点类似于“Scaling Vision Transformers”那篇论文中的lr计划消融操作。
这也与Llama的余弦学习率衰减(要求它们提前指定步数)完全不同,非常有趣。

下图是作者发布的DeepSeek训练损失曲线以及在几个基准上的曲线图:
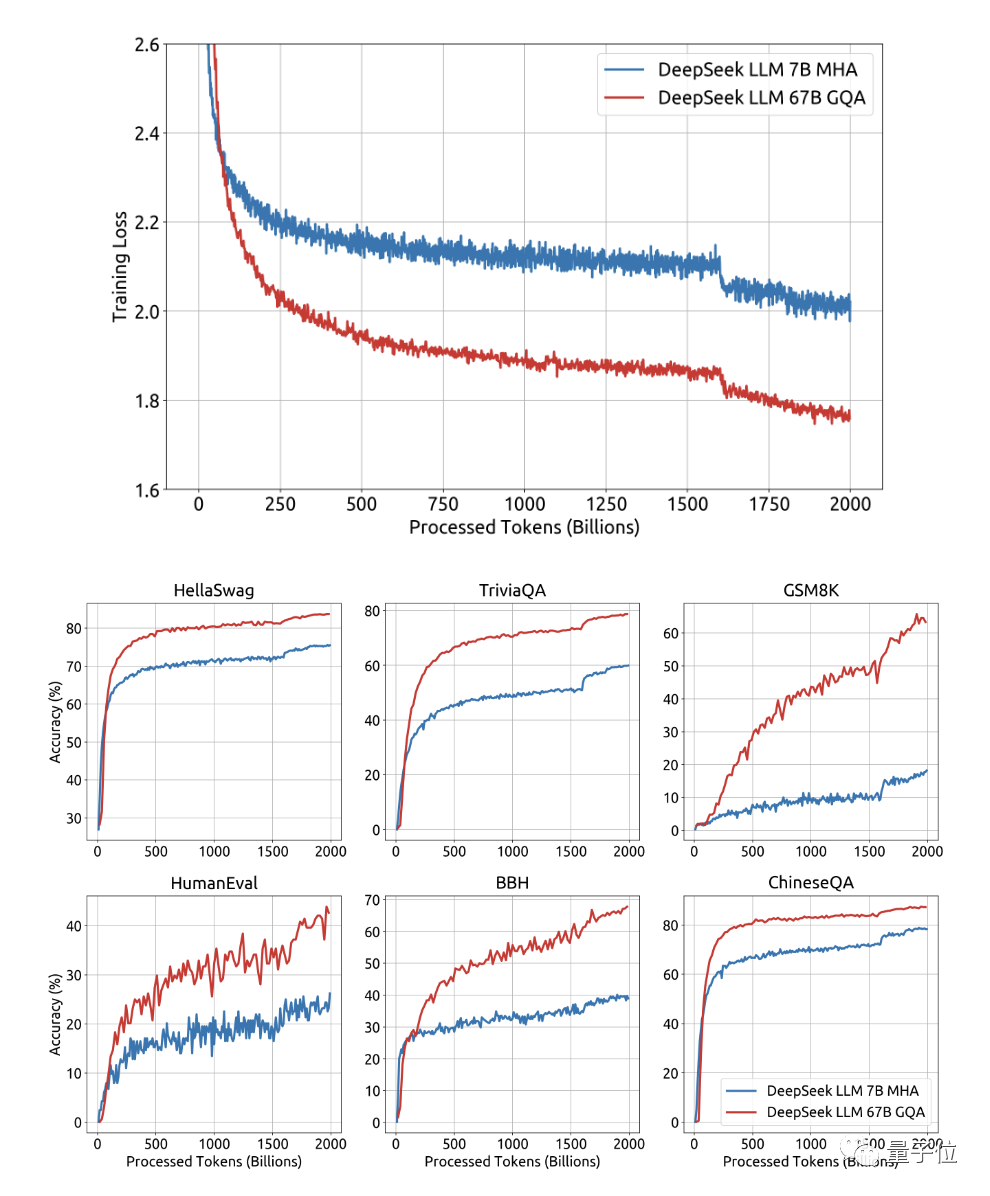
我们重点关注DeepSeek进行的如下三大类测试结果。
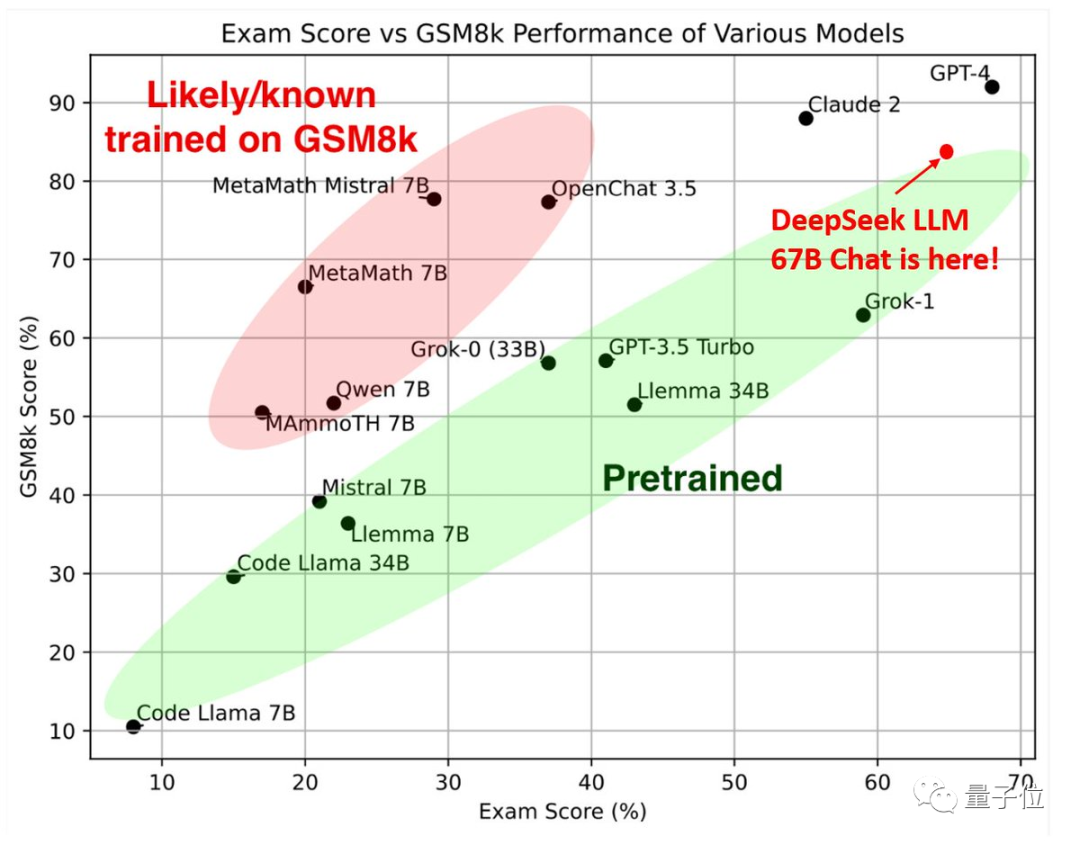
一个是今年5月才发布的2023年匈牙利高中数学考试题。
尽管DeepSeek已经在GSM8k和MATH这两个标准基准上取得了不错的成绩:
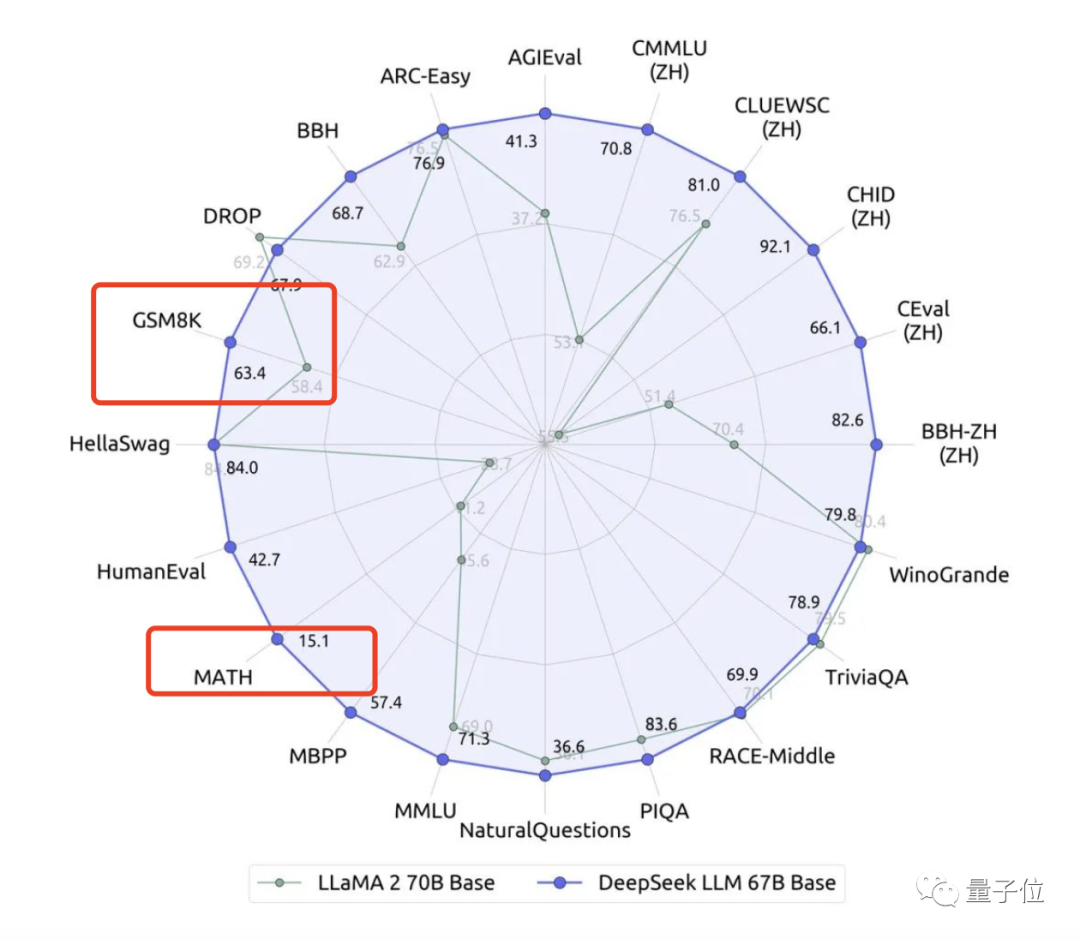
但由于存在过度拟合这些数据集的风险,作者还是决定评估一下样本外的数学泛化能力。
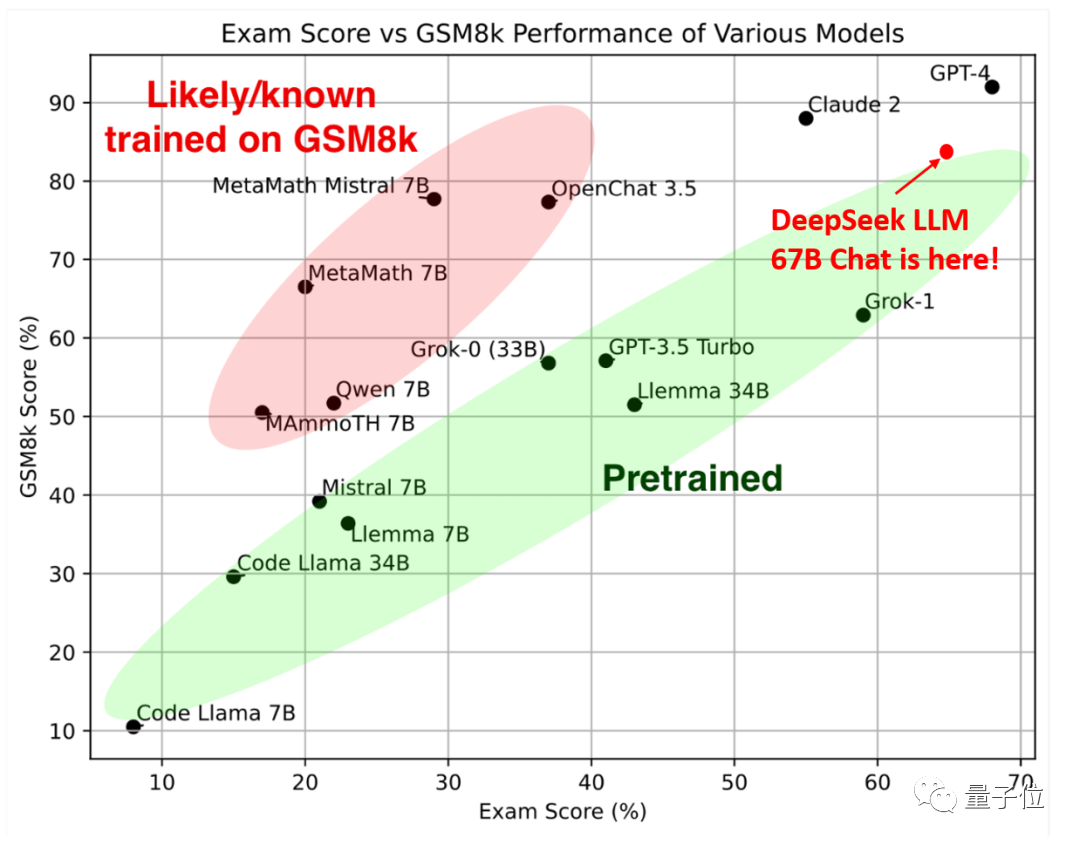
如下图所示,位于右上角的670亿参数DeepSeek最终在样本内数学能力(纵轴GSM8K)排名第三,仅次于Claude 2和GPT-4,但在样本外数学能力(横轴Exam Score)排名第二,仅次于GPT-4。
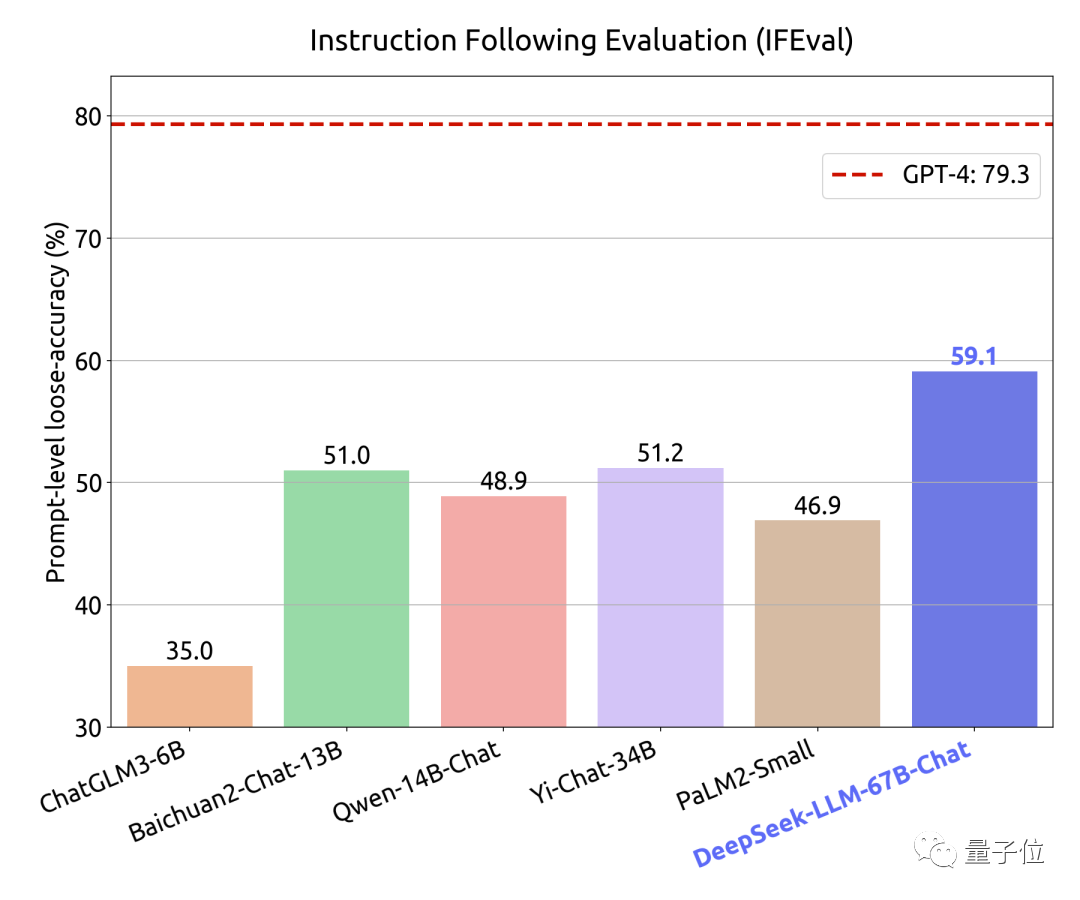
第二个是考验DeepSeek指令跟随能力的测试。
在此,作者使用了谷歌11月15日刚刚发布的指令跟随评测集,来评价模型的“听话程度”。
结果是领先一众开源模型,但59.1分的成绩与GPT-4还有20分的差距。
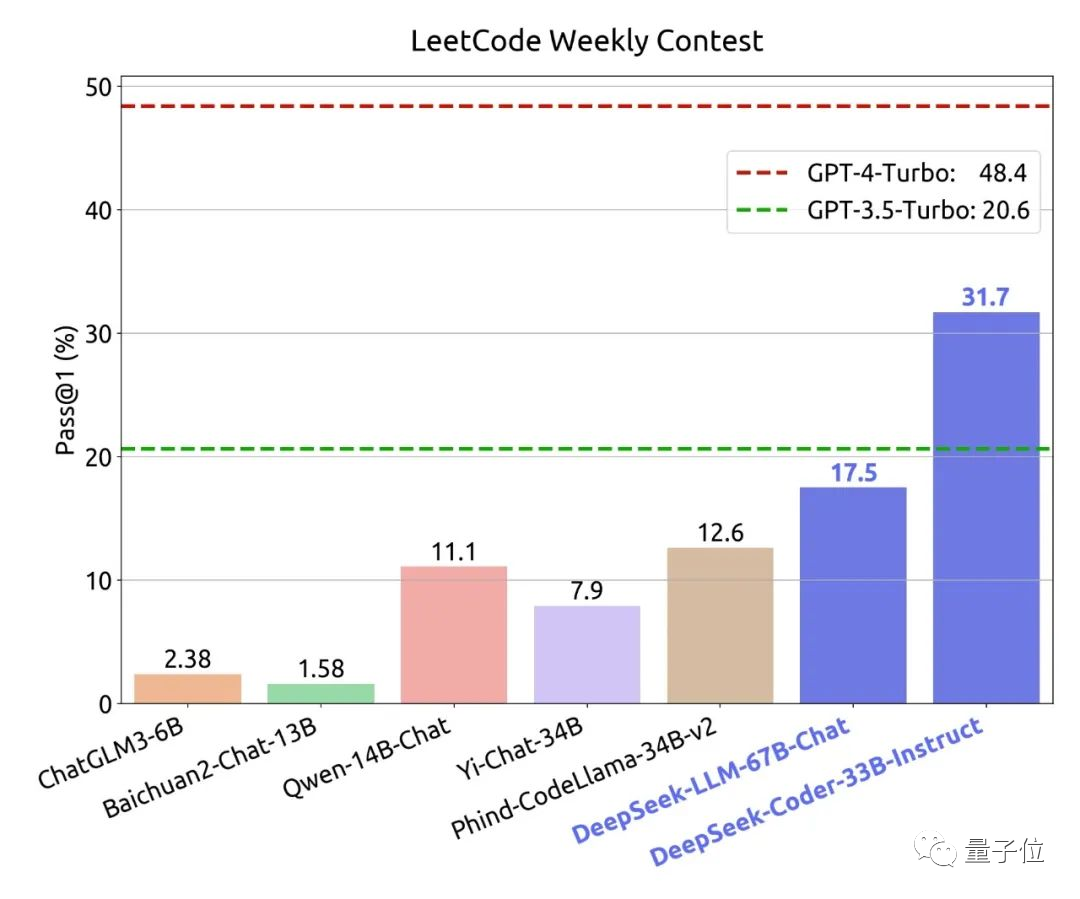
最后是代码能力测试。
同样,作者在这里重点关注了样本外能力,选择的是LeetCode今年7月2日到11月12日的最新真题进行测试。
结果是比国内常见的大模型都要好很多,并且也远远超越了GPT 3.5。
经搜索,DeepSeek背后的公司名叫深度求索。base位于北京,今年5月正式成立。
目标不止是大模型,而是AGI。
就在11月初,这家公司就发布代码大模型DeepSeek Coder。
与之前最好的开源大模型CodeLlama相比,DeepSeek Coder在代码生成任务上(使用标准数据集HumanEval、MBPP和DS-1000进行评测)分别领先了9.3%、10.8%和5.9%。
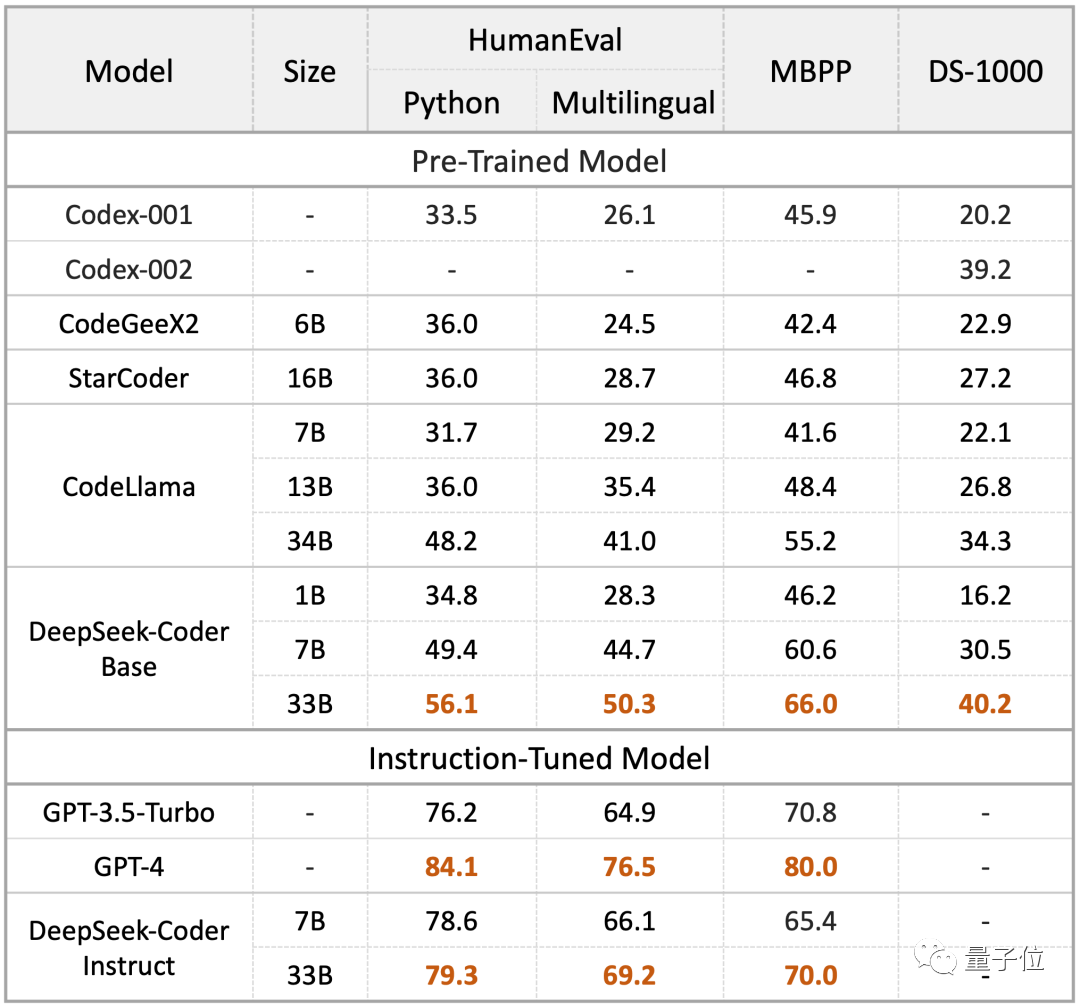
特别值得一提的是,深度求索其实是从知名私募巨头幻方旗下独立出来的一家公司。
幻方这家公司听起来和AI“八杆子打不着”,但实际上,2019年时,幻方就发布了自研深度学习训练平台“萤火一号”。
据称该项目总投资近2亿元,共搭载了1100块GPU。
后来“萤火一号”由升级为“二号”,搭载的GPU数则达到了约1万张。
参考链接:
[1]https://mp.weixin.qq.com/s/Zj7gPGqJ8UTTxp1umfWjKQ
[2]https://twitter.com/johannes_hage/status/1730075189428494842
[3]https://twitter.com/jeremyphoward/status/1730113946345205970
[4]https://twitter.com/bindureddy/status/1730248977499762740
[5]https://zhuanlan.zhihu.com/p/636451367
文章来自于 微信公众号“量子位”(ID: QbitAI),作者 “丰色”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
