# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型(LLM)的发展历程中,思维链(Chain of Thought,CoT)推理无疑是一个重要的里程碑。这种通过"思考过程显式化"来提升模型推理能力的方法,让AI在数学问题求解、多步骤推理等任务上取得了显著进展。然而,随着应用规模的扩大,CoT推理的效率问题日益凸显:生成详细的推理步骤会带来巨大的延迟开销。以GPT-4为例,使用CoT推理解答一个数学问题需要21.37秒,而直接输出答案仅需2.81秒。这种近10倍的性能差异,在实际应用中往往令人难以接受。

约翰霍普金斯大学的研究团队最近提出了一种突破性的解决方案:压缩思维链(Compressed Chain of Thought,CCoT)。这种方法通过在连续向量空间中进行推理,巧妙地平衡了推理性能与计算效率之间的矛盾。

本文将深入剖析这一创新框架的技术原理、实现方法及其重要意义。
思维链推理技术的发展大致经历了以下几个重要阶段:
1. 早期探索(2021-2022)
2.零样本突破(2022-2023)
3.效率优化探索(2023-2024)
目前主流的思维链优化方法可以分为以下几类:
1.并行化方法
2.模板化方法
3.蒸馏方法
下表总结了不同思维链方法的主要特征:
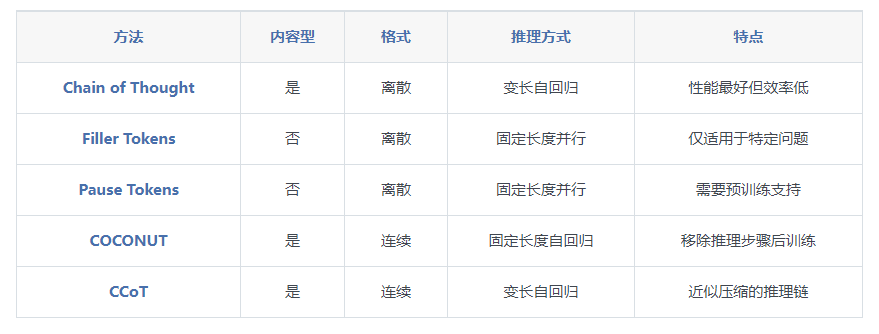
1.计算效率问题
2.性能瓶颈
CCoT的核心创新在于将传统CoT中的离散文本推理步骤,转化为连续向量空间中的"压缩表示"(Compressed Representations)。
这种转化不仅大幅降低了推理过程的token长度,还保留了关键的推理信息。研究者们发现,通过精心设计的压缩机制,模型能够在显著减少计算开销的同时,保持甚至提升推理准确性。
以一个具体的数学问题为例:
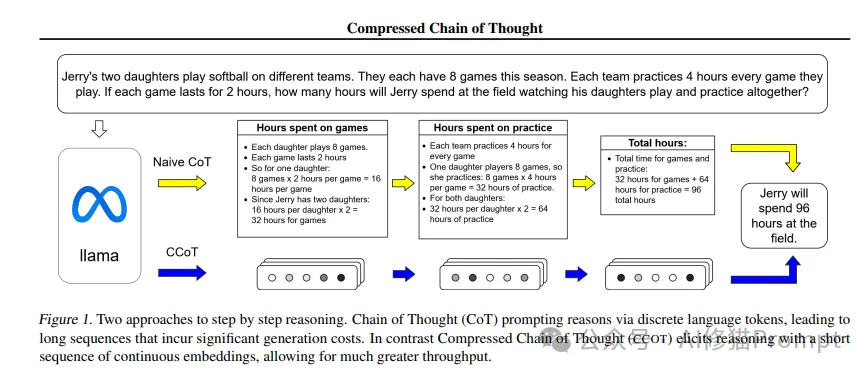
问题:Jerry有两个女儿在不同的球队打垒球。本赛季每人有9场比赛。每场比赛球队要练习4小时。如果Jerry花2小时观看每场比赛和训练,他一共要在球场花多少时间?
传统CoT推理过程:
CCoT方法:通过连续向量表示压缩这个推理过程,将离散的推理步骤转化为密集的向量序列。这种压缩不仅保留了关键的推理信息,还显著减少了生成和处理的token数量,从而大幅提升了推理效率。
1.压缩表示的形式化定义
设输入序列为w1:n,对应的推理链为t1:m,CCoT的目标是学习一个映射函数f,将完整推理链压缩为k个连续向量(k << m):
f: R^{m×d} → R^{k×d}
其中d为隐藏状态的维度。这个映射需要满足以下性质:
2.自回归生成机制
在生成第i个压缩表示时,模型使用前i-1个表示的第l层隐藏状态作为输入:
z_i = g(z_{1:i-1}^l)
其中g是生成函数,z^l表示第l层的隐藏状态。这种设计允许模型在生成新的压缩表示时考虑之前的推理信息。
CCoT框架包含两个核心模块:
1.CCOTφ模块
2.DECODEψ模块
以下是传统CoT和CCoT推理过程的算法对比:
传统CoT推理算法:
1. 输入查询序列w,进行嵌入
2. 计算隐藏状态
3. 循环生成推理步骤,直到遇到<ANS>标记
4. 基于推理步骤生成答案,直到遇到<EOS>标记
5. 返回答案
CCoT推理算法:
1. 输入查询序列w,进行嵌入
2. 计算隐藏状态
3. 使用第l层隐藏状态自回归生成压缩表示
4. 基于查询和压缩表示生成答案
5. 返回答案
关键区别在于:
1.CCOTφ模块训练
2.DECODEψ模块训练
1.数据集
2.基线模型
3.评估指标
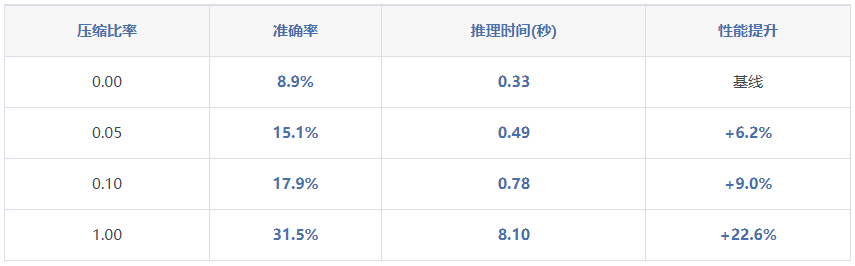
1.不同压缩比率下的性能(r值)
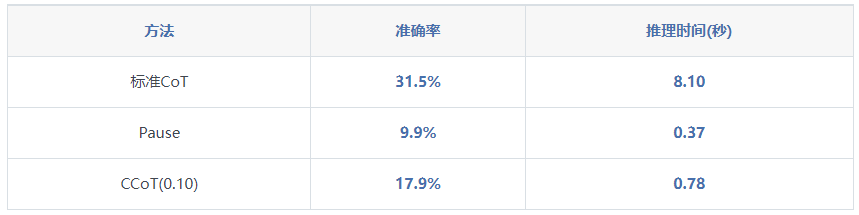
2.与现有方法的对比
3.不同自回归层的影响
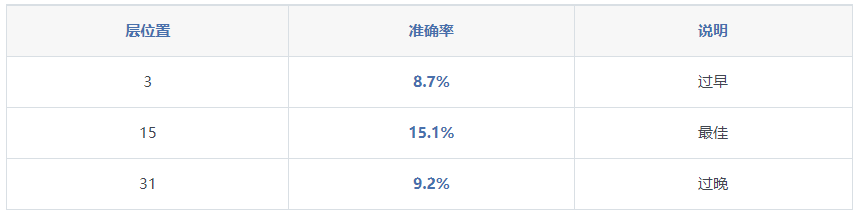
1.压缩比率的影响
2.自回归层选择的重要性
3.与现有方法的优势
1.空间复杂度
2.时间复杂度
1.表示能力定理
对于任何需要D步计算的任务,使用L层Transformer时:
2.信息保持定理
在合适的压缩比率r下:
1.理论限制
2.实践限制
1.环境准备
2.模型训练
3.部署优化
1.推理效率优化
2.内存优化
3.质量控制
1.通用领域
2.专业领域
3.新兴应用
压缩思维链(CCoT)的提出代表了AI推理技术的一个重要突破。这种方法通过在连续向量空间中进行推理,巧妙地解决了传统思维链推理中的效率问题。实验结果表明,CCoT能够在保持较高推理准确性的同时,显著提升推理效率。对于Prompt工程师而言,CCoT提供了一个强大的工具,能够帮助他们构建更高效的AI系统。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
