Kimi K3设计榜登顶焚诀公开:就藏在思维链里
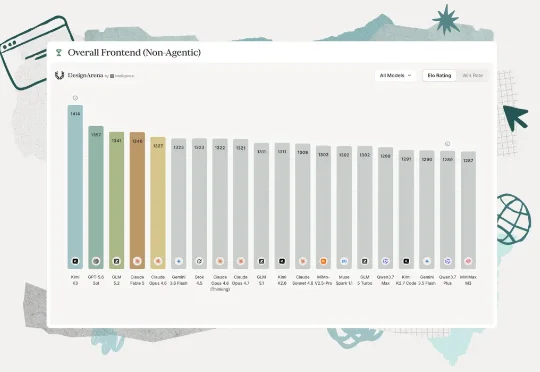
Kimi K3设计榜登顶焚诀公开:就藏在思维链里停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。
来自主题: AI技术研报
9473 点击 2026-07-25 11:37
 搜索
搜索
停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。
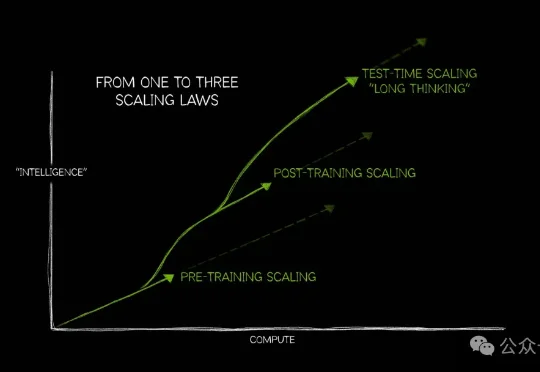
新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca

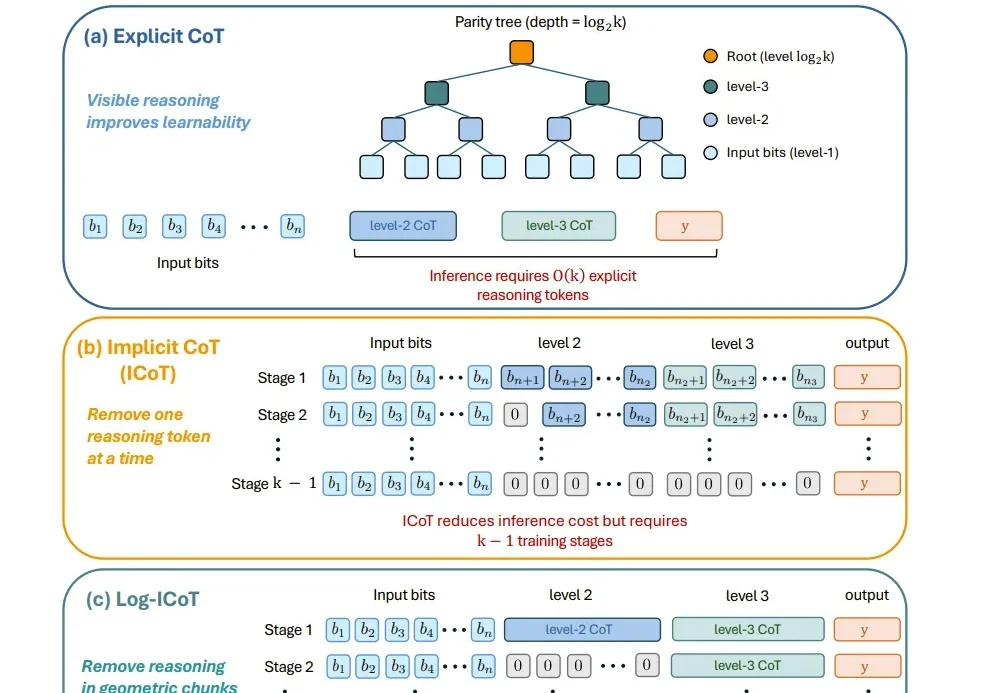
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
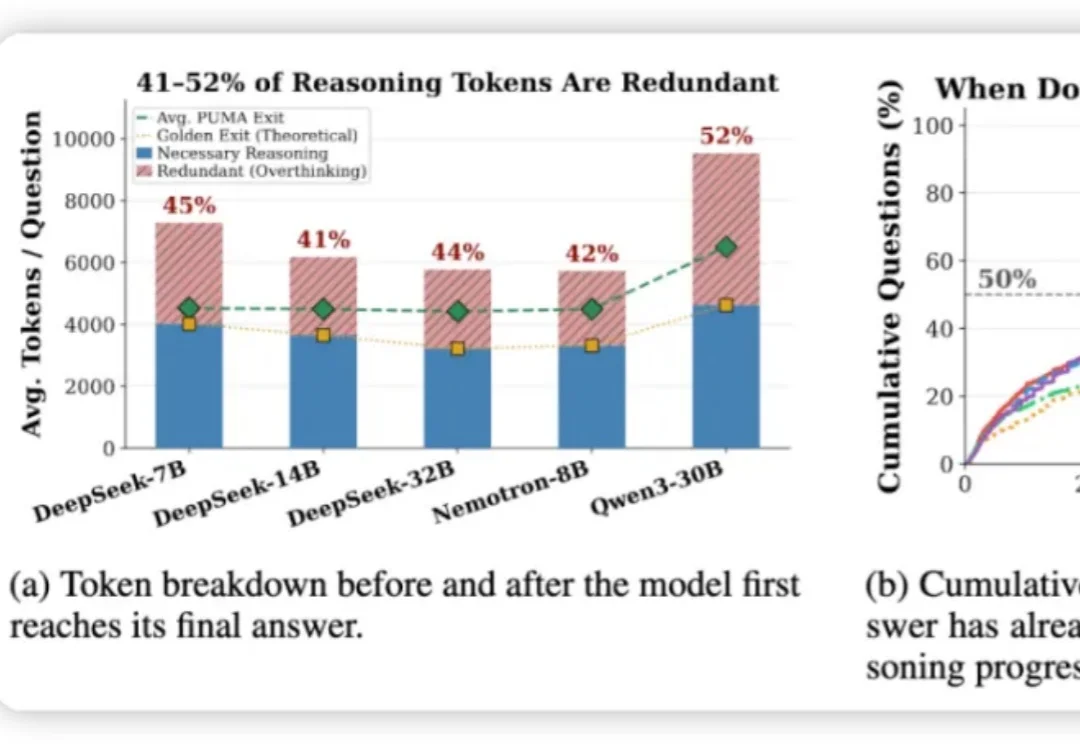
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
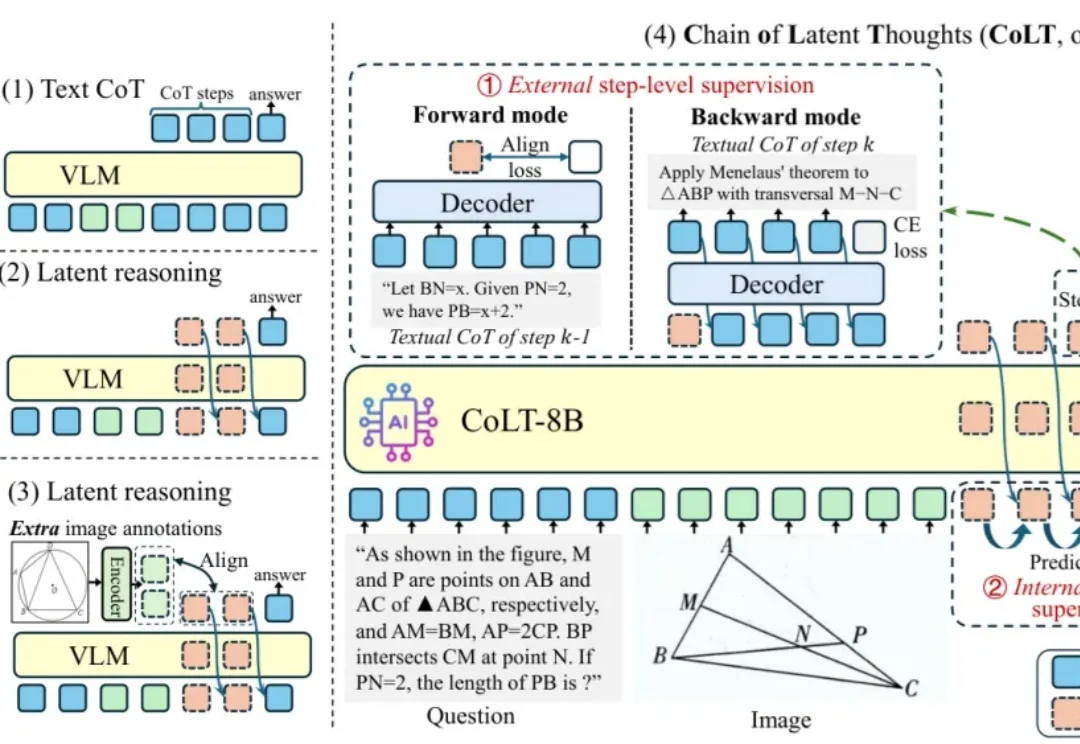
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
过去一年,AI 推理模型的使用成本让不少开发者叫苦。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。
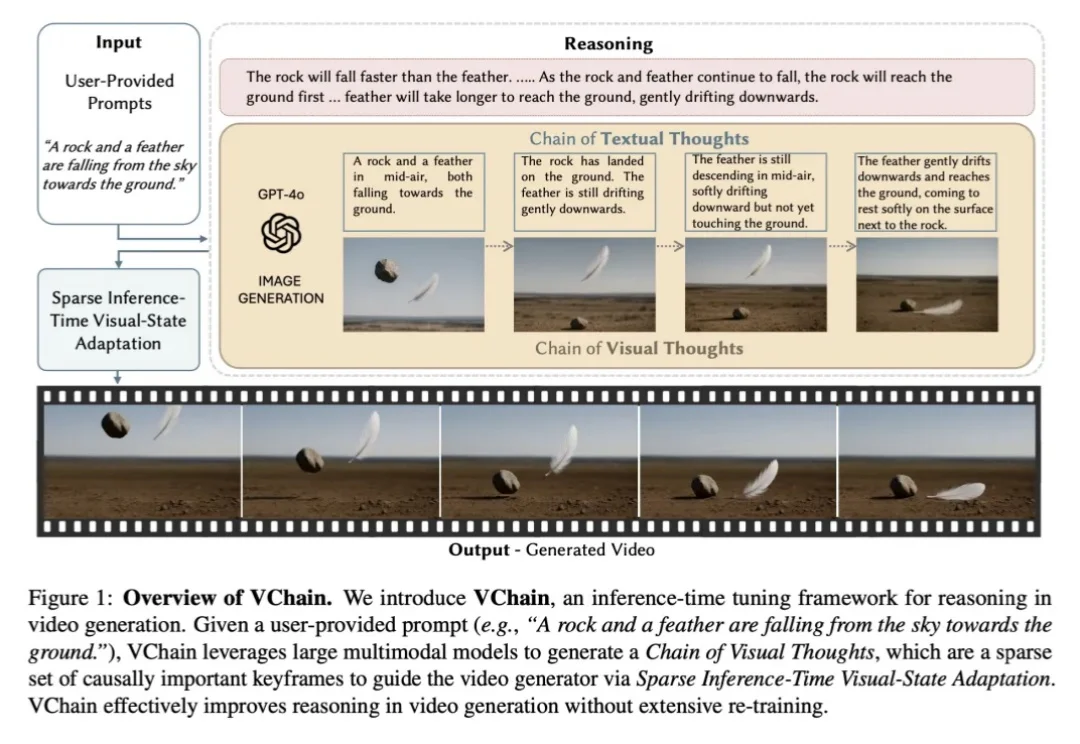
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。