ICLR 2026|隐式思考模型LRT:「隐式思维链」推理,更快更强!
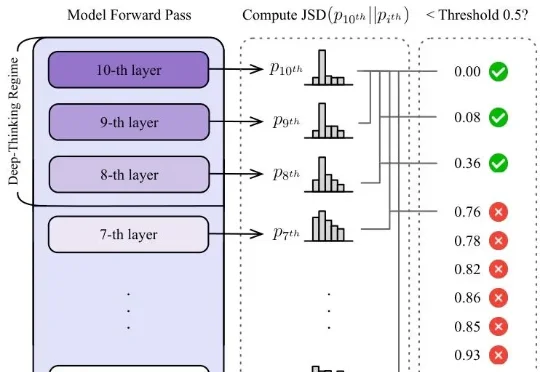
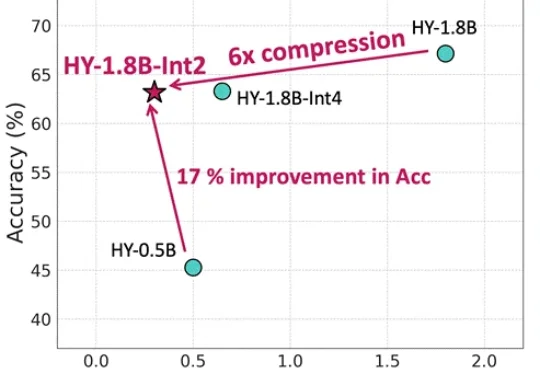
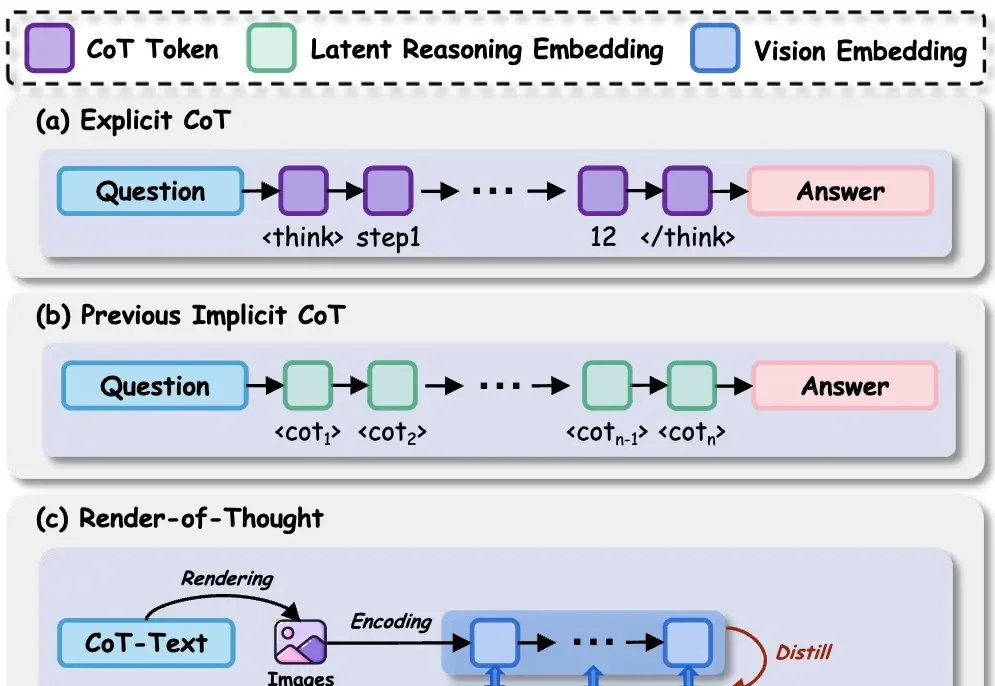
ICLR 2026|隐式思考模型LRT:「隐式思维链」推理,更快更强!近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
来自主题: AI技术研报
10486 点击 2026-04-13 09:35