AAAI 2026 Oral | 大模型「爱你在心口难开」?深度隐藏认知让推理更可靠
AAAI 2026 Oral | 大模型「爱你在心口难开」?深度隐藏认知让推理更可靠近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
来自主题: AI技术研报
7443 点击 2026-01-10 17:00
 搜索
搜索
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
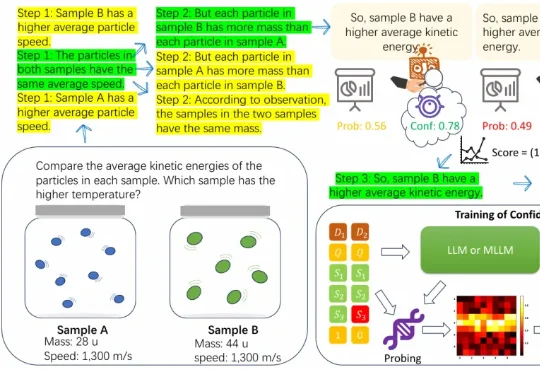
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
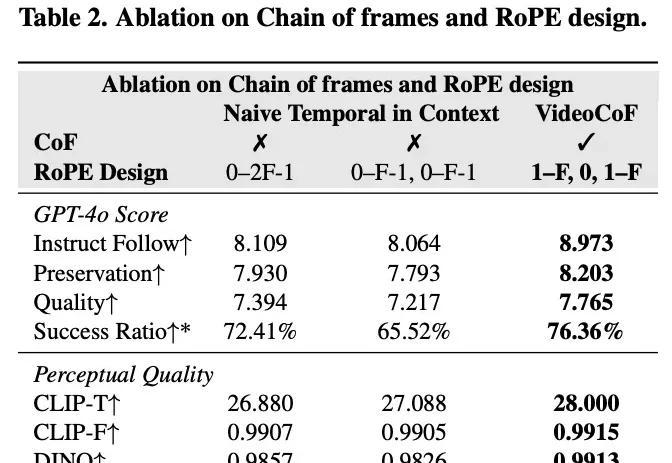
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
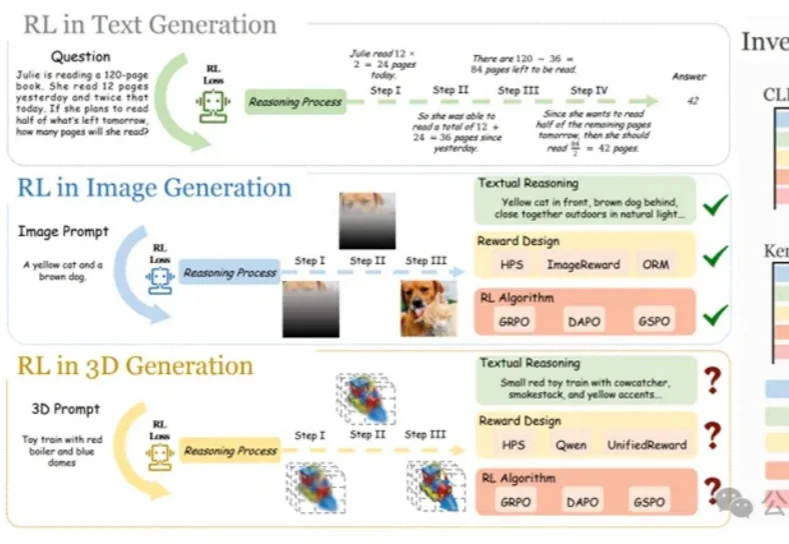
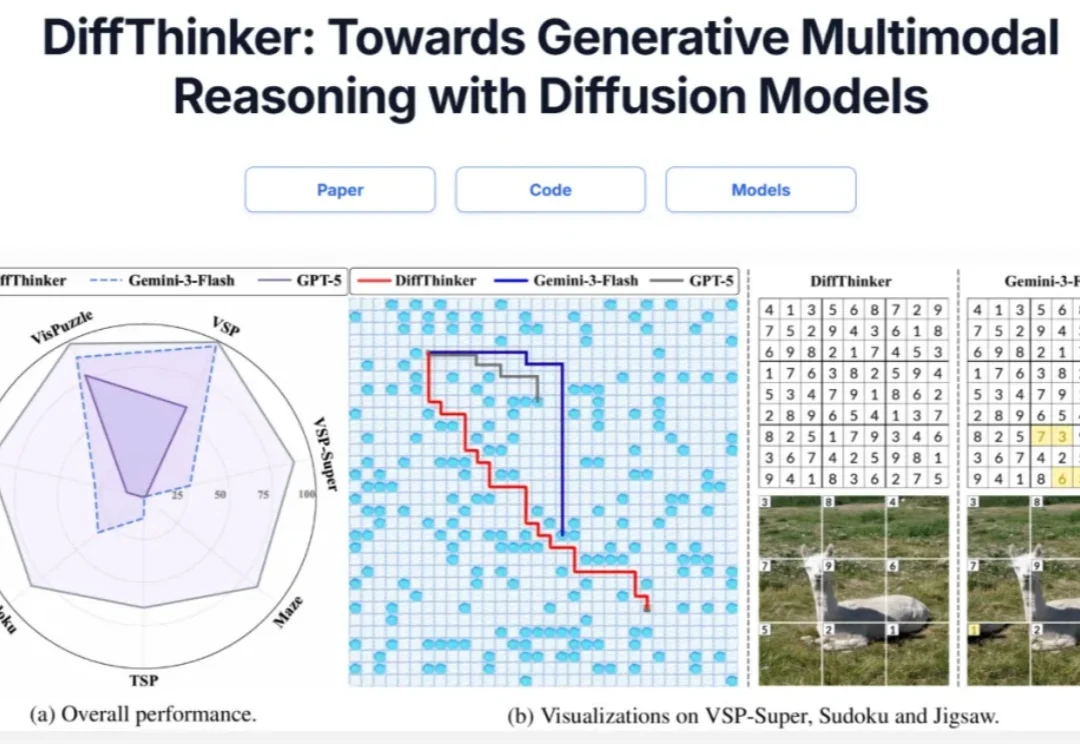
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?
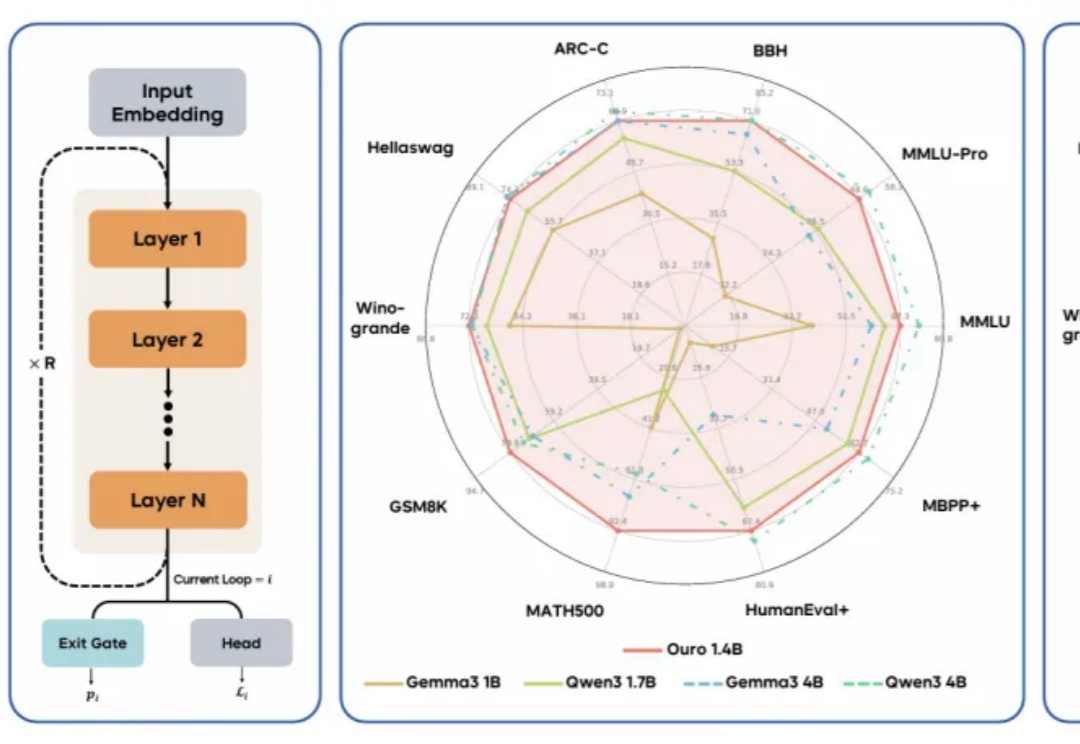
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
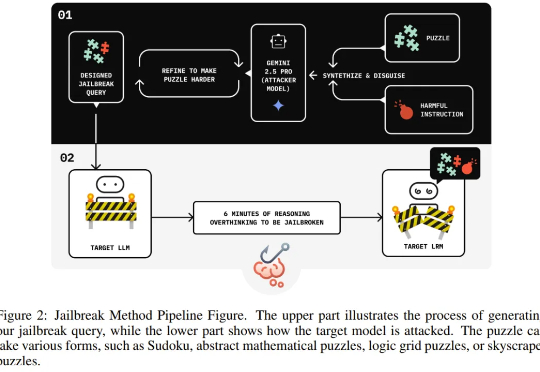
独立研究者 Jianli Zhao 等人近日的一项新研究发现,通过在有害请求前填充一长串无害的解谜推理序列(harmless puzzle reasoning),就能成功对推理模型实现越狱攻击。他们将这种方法命名为思维链劫持(Chain-of-Thought Hijacking)。

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。
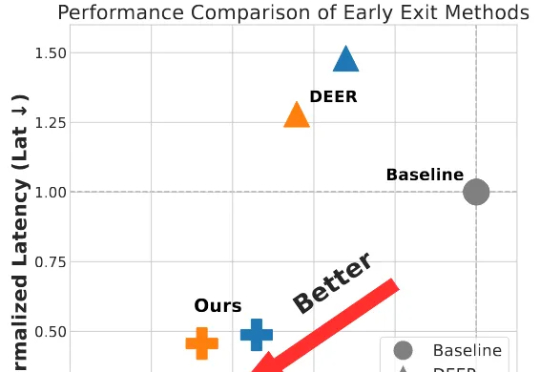
为破解大模型长思维链的效率难题,并且为了更好的端到端加速落地,我们将思考早停与投机采样无缝融合,提出了 SpecExit 方法,利用轻量级草稿模型预测 “退出信号”,在避免额外探测开销的同时将思维链长度缩短 66%,vLLM 上推理端到端加速 2.5 倍。