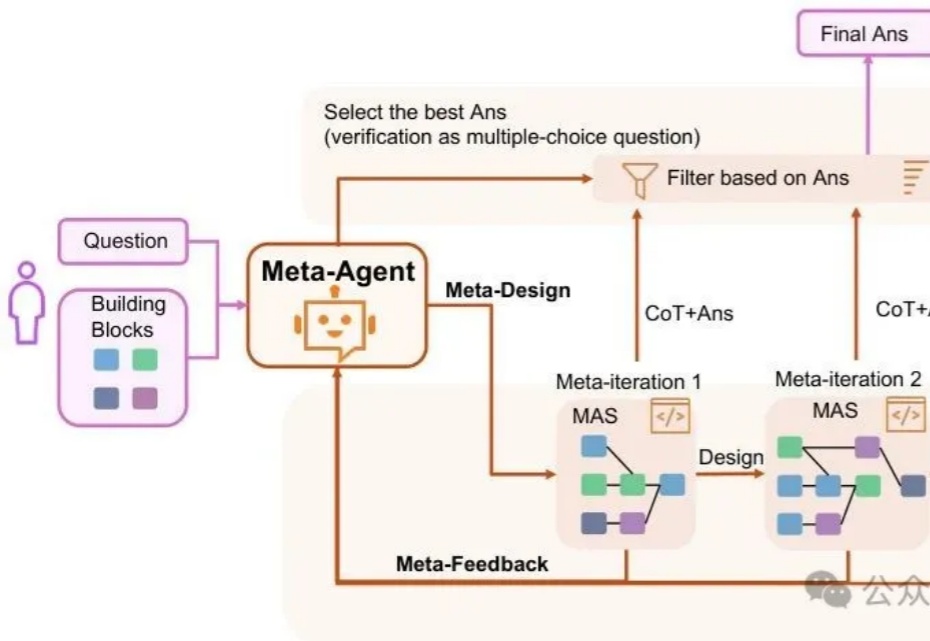
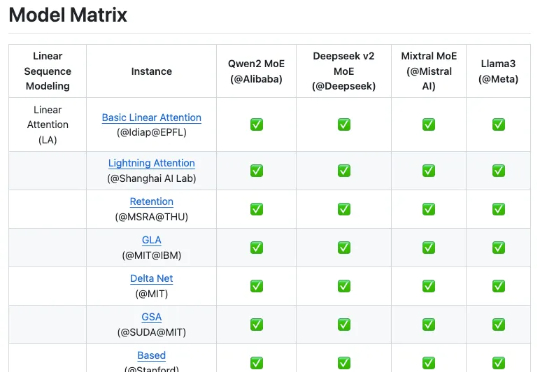
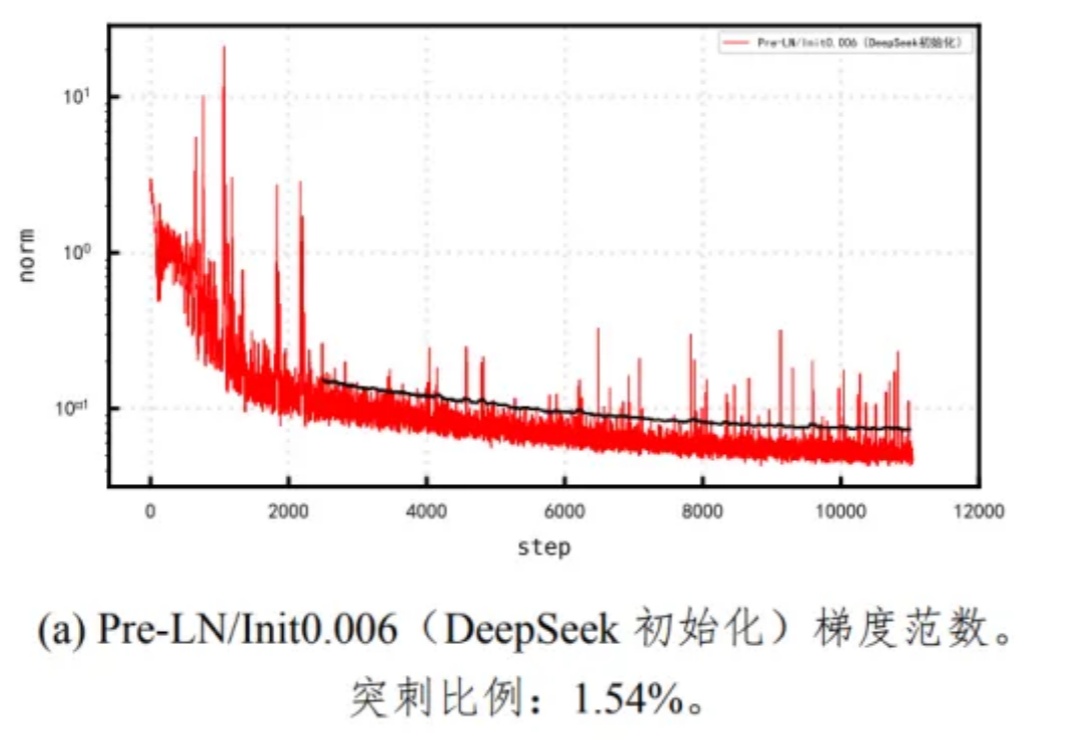
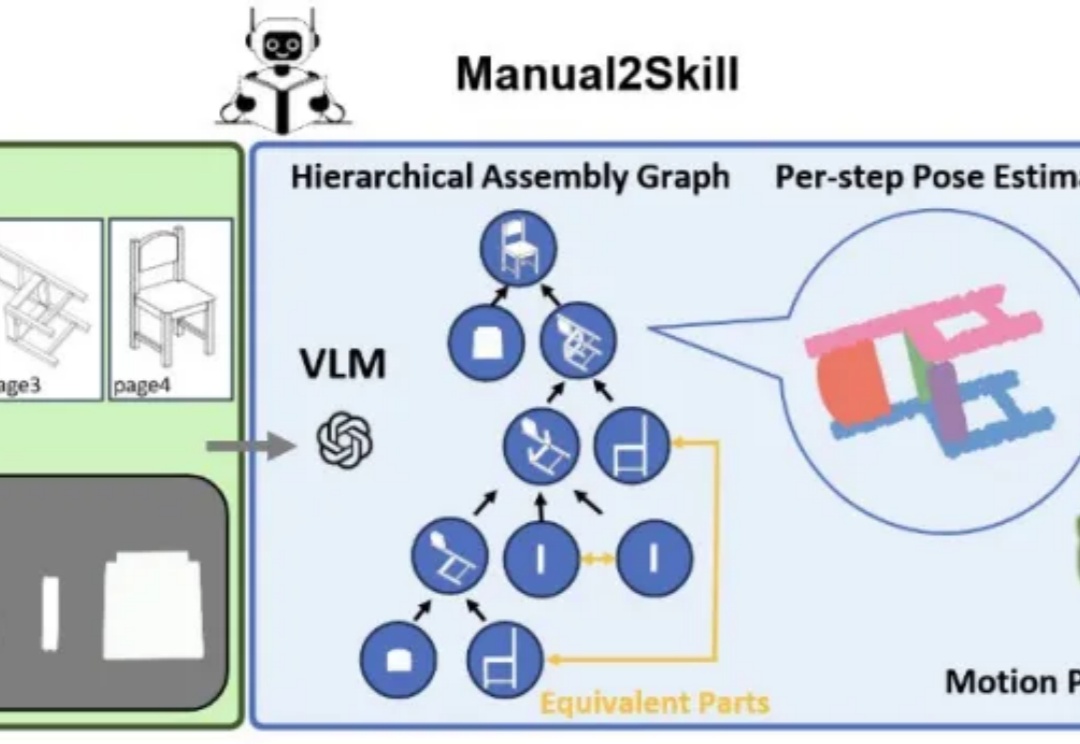
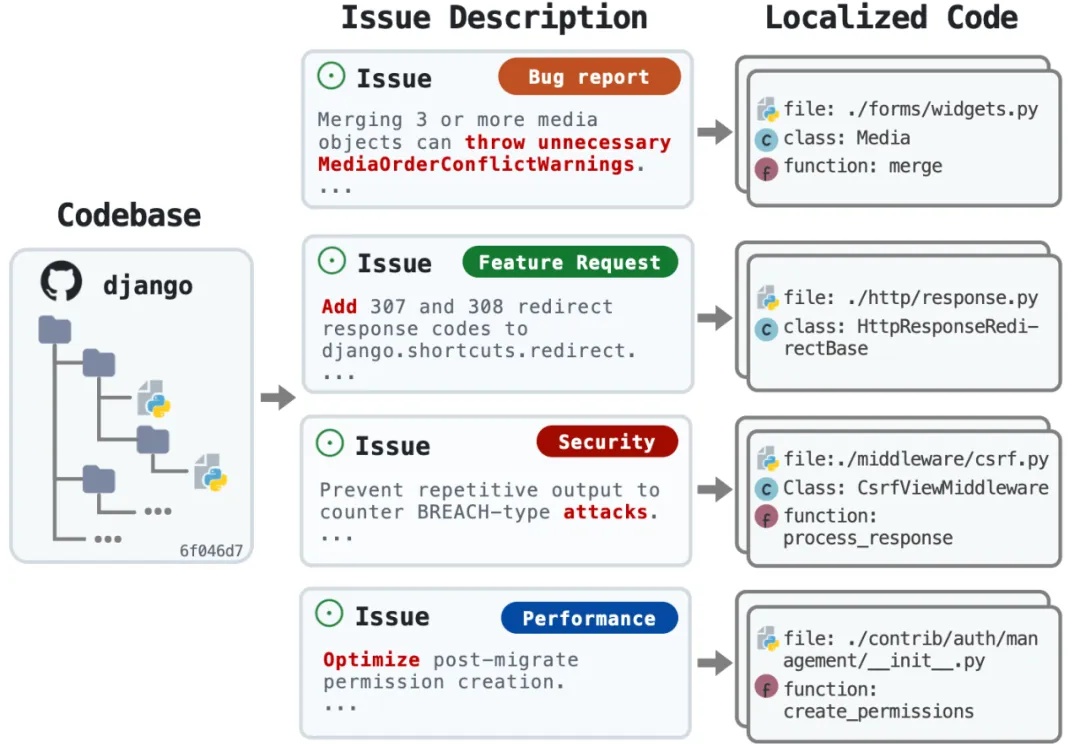
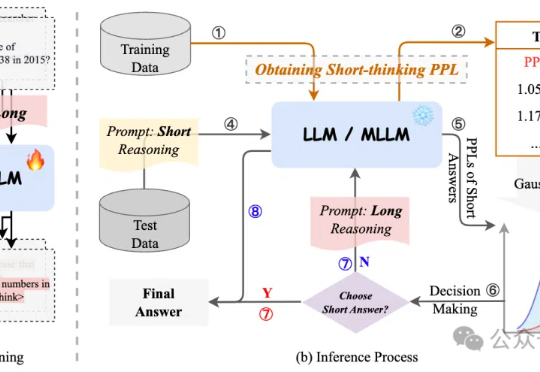
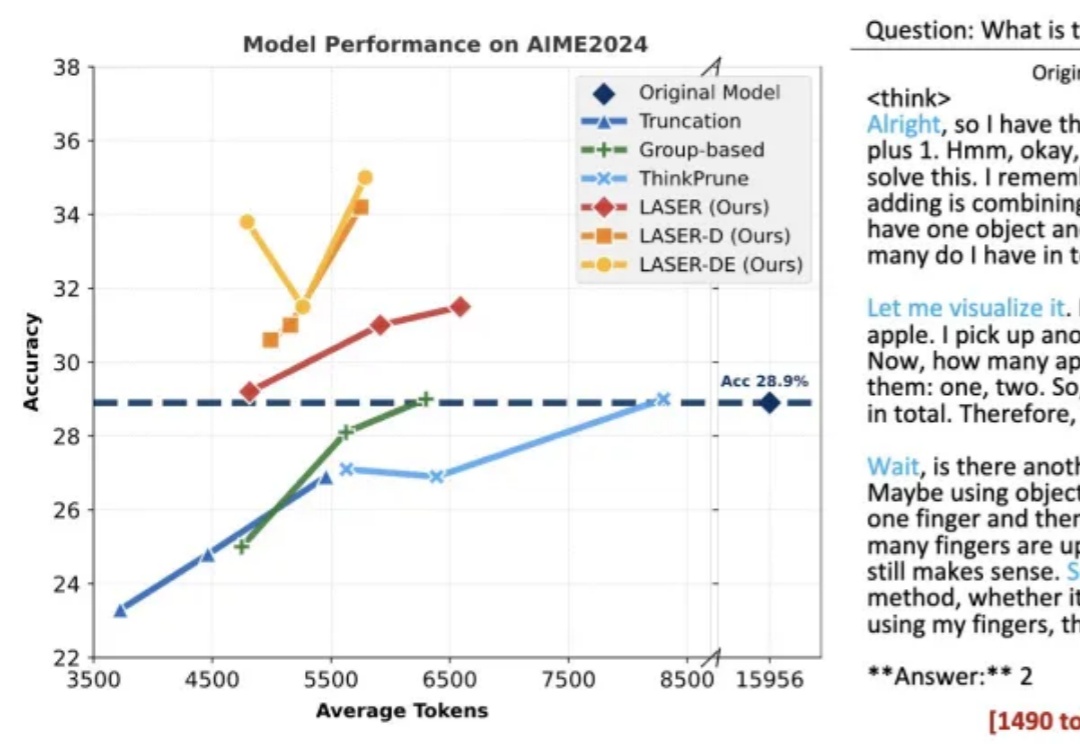
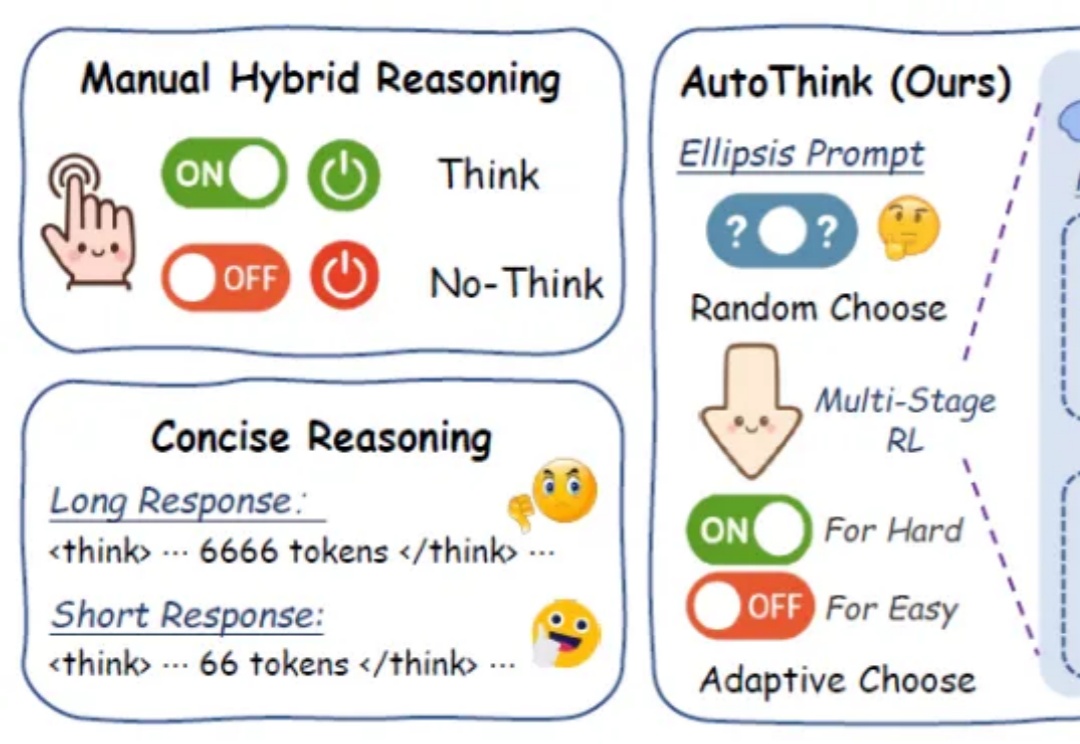
谷歌之后,英伟达入局扩散大语言模型,Fast-dLLM推理速度狂飙27.6倍
谷歌之后,英伟达入局扩散大语言模型,Fast-dLLM推理速度狂飙27.6倍近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。
来自主题: AI技术研报
7364 点击 2025-05-30 12:08