
硅谷大佬集体下场做 Neo Labs | 盘点估值最高的20家
硅谷大佬集体下场做 Neo Labs | 盘点估值最高的20家它不同于我们认知中传统的「学术机构」or「创业公司」。它要在同一个屋顶下,同时扛住四件事:科学路径是否成立、工程能不能跑通、市场有没有人买单、资本能不能撑到关键节点。硅谷现在有个非正式叫法:Neo Labs。
来自主题: AI资讯
7465 点击 2026-06-07 10:53
 搜索
搜索
它不同于我们认知中传统的「学术机构」or「创业公司」。它要在同一个屋顶下,同时扛住四件事:科学路径是否成立、工程能不能跑通、市场有没有人买单、资本能不能撑到关键节点。硅谷现在有个非正式叫法:Neo Labs。

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。

在人工智能与体育产业深度融合的浪潮中,高尔夫这项传统运动正迎来一场由“物理AI”驱动的技术革命。近日,专注于高尔夫运动科技创新的XintLabs宣布完成数千万元天使轮融资,由高瓴创投独家投资。资金将主
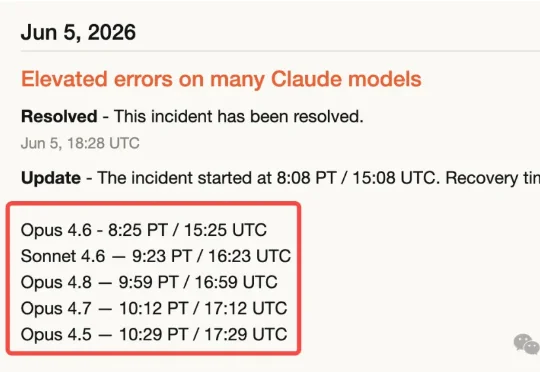
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。

最近,一个叫 Emergence AI 的团队做了一场社会实验。它们建了一个持久化的虚拟小镇,把市面上最顶级的几个大模型扔了进去,赋予它们行动的权限。它们想看看,当 AI 真正拥有了不受限制的 15 天,它们会建立一个乌托邦,还是一个疯人院。

1985 年,教育部高考语文研究组编了一本书,《全国高考作文评分系统与各类标准卷选》,那是一个关注语言水平、写作创造力和文字如何反映生活的时代,高考作文既是一种考察写作能力的方式,也是教书育人理念的延
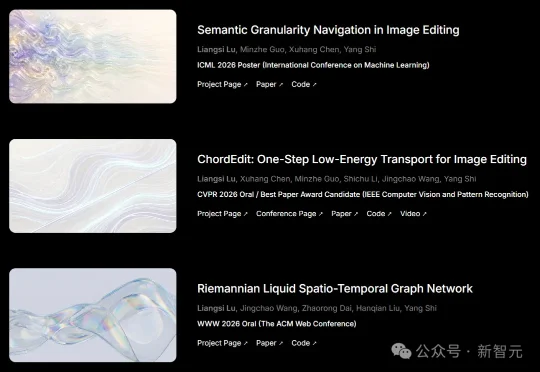
CVPR 2026全部奖项揭晓!最佳学生论文荣誉提名颁给了ChordEdit,一作和通讯都是广东工业大学本科在读生。他们用一块7年半前的老Titan,跑完了全部实验。
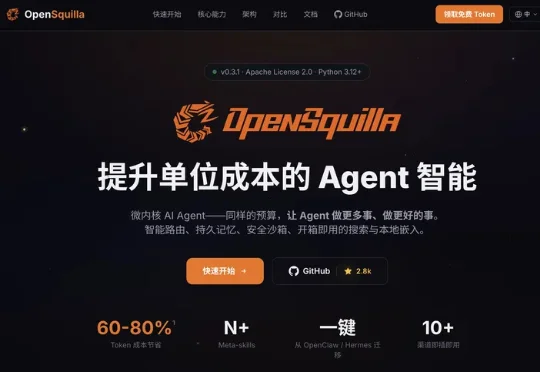
OpenSquilla 是一个开源 Agent Harness 框架(https://github.com/opensquilla/opensquilla)。它在 Agent 应用和模型之间加了一层运行中枢。OpenSquilla 由上海基元律动科技有限公司开发。基元律动成立仅几个月后,已完成首轮融资,估值高达1亿美元。

据彭博社报道,美国总统特朗普表示有意让美国政府持有领先AI公司的股权,并称他计划最早下周与AI公司高管讨论合作的想法。周五,特朗普在空军一号上被记者问到此事时谈道:“有些方案可以将部分股份赠予美国公众,让美国公众实际上成为合作伙伴。这很有意思,它几乎可以与美国公众建立伙伴关系,我们会研究一下。”