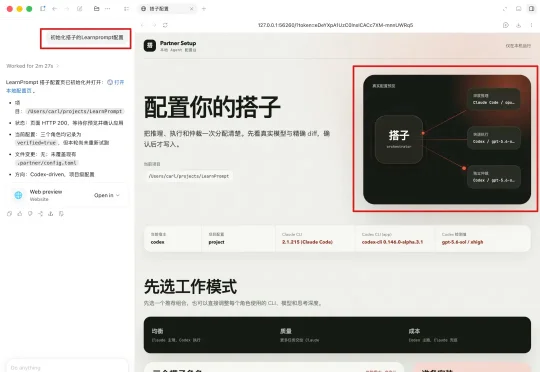
烧了一万块API后,我找到了同时适用于Fable5和GPT5.6的AI工作流
烧了一万块API后,我找到了同时适用于Fable5和GPT5.6的AI工作流就是上个月我开源的让Claude Code和Codex搭配使用的Skill搭子的1.4版,当时的定位是把Claude Code出计划然后直接在当前对话调用Codex,不需要复制黏贴,由Fable5自己写交接文档自己从CodeX那读取输出。
来自主题: AI资讯
8894 点击 2026-07-30 10:43
 搜索
搜索
就是上个月我开源的让Claude Code和Codex搭配使用的Skill搭子的1.4版,当时的定位是把Claude Code出计划然后直接在当前对话调用Codex,不需要复制黏贴,由Fable5自己写交接文档自己从CodeX那读取输出。
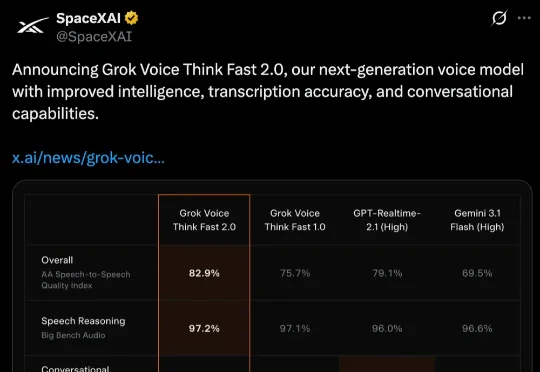
今日,马斯克旗下SpaceXAI宣布推出新一代语音模型Grok Voice Think Fast 2.0,这是该公司迄今能力最强的语音到语音(speech-to-speech)模型。马斯克连发两条推文,第一条宣布“Grok Voice现在在智能体性能方面排名第一”,第二条则直接喊话网友“试试新的Grok Voice”。

业界首个国产芯片上跑出的万亿参数模型LongCat-2.0于近日发布。

7 月的上海,世博展览馆 H3 馆的过道比往年拥挤许多。 入口处停着宇树的载人变形机甲 GD01,观众排队坐进驾驶舱拍照。往里走,300 多台机器人真机散在 200 多家具身智能企业的展台之间,具身智

2026年10月1日,IROS 2026 Workshop——Physical World Models for Scaling Embodied AI将在美国匹兹堡举行。论文征集现已开放,8月10日截止;WorldArena 2.0 Challenge三大赛道已于7月10日开赛,总奖金$7500。

刚刚,钛动科技在 WAIC 上发布了 Navos 2.0,把多智能体产品从网页对话框升级为智能体工作流架构。本月初,钛动还与 OpenAI 正式达成了合作并签约。创始人兼 CEO 李述昊给公司取了两个词拼成的名字——Tec-Do(用技术做生意),后面挂着版本号 2.0,含义是「像做产品一样做公司」(Develop Company as Product)——Tec-Do 2.0。
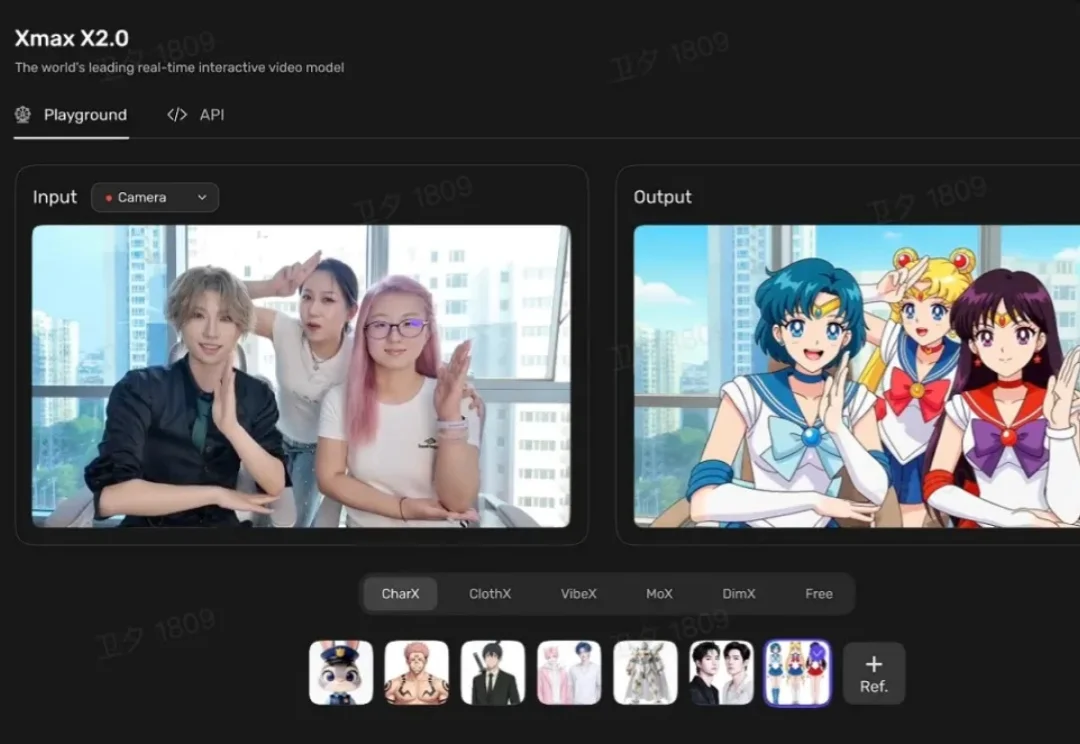
我们先来看两个画面。

WorldArena 1.0 的核心意义,在于将世界模型评测从 “好不好看” 推进到 “是否真的有用”。它不再只关注视频观感,而是把物理一致性、可控性、3D 准确性和具身任务功能性纳入统一评测框架,使许多看似流畅的生成结果第一次在机器人具身任务中接受检验。
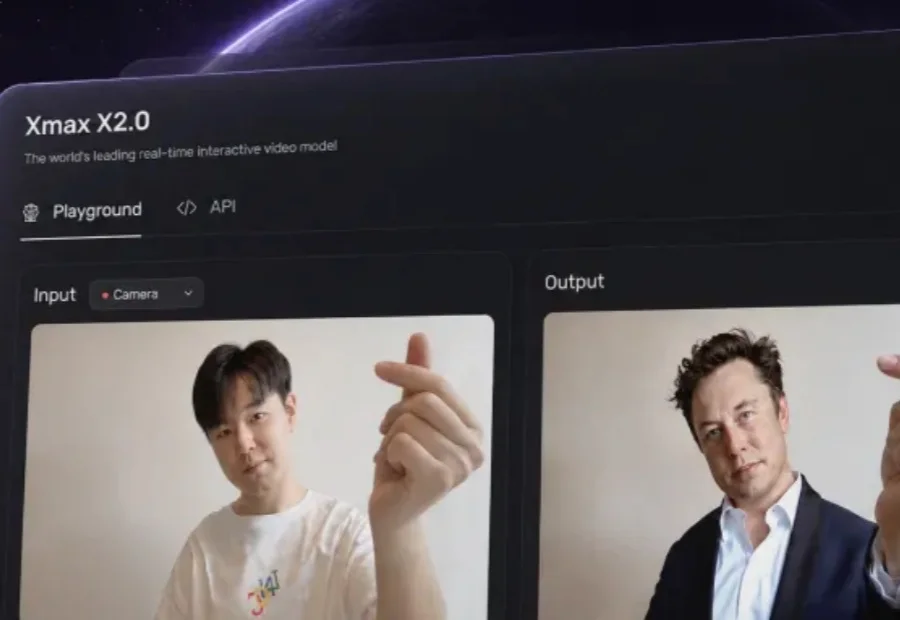
对着摄像头比了个手势,桌上凭空多了只企鹅
终于!和我的二次元老公!成!功!约!会!