
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。
来自主题: AI资讯
8608 点击 2026-07-25 21:16
 搜索
搜索
最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。

今年 6 月,Google DeepMind 宣布与电影公司 A24 建立长期研究合作,并向其投资约 7500 万美元。成立于 2012 年的 A24,以开发独具文艺气息的小众电影见长。它的代表作包括奥斯卡最佳影片《月光男孩》和《瞬息全宇宙》、全球票房大卖的《至尊马蒂》,以及今年热映的恐怖片《后室》。14 年间,A24 早已把片厂名字做成品牌:A24 三个字,本身就是人气的保证。

7月16日,Nature刊出消息:科学家用AI造出了自然界里从来没有过的CRISPR酶,切基因比「天然版本」更利索。论文同日发表在Science。带队的人,是2020年因为CRISPR拿下诺贝尔化学奖的Jennifer Doudna。

2023 年他在深圳创立听象科技,推出自有品牌昂听 ELEHEAR(下文统一简称 ELEHEAR)。前期发布 Alpha 系列产品试水助听器市场,2024 年 10 月推出旗舰产品 Beyond,凭借全栈自研的 AI 助听器+远程实时验配的新模式,用 1 年时间做到了美国亚马逊助听器类目 Top1,年销超 1500 万美元,市场份额从 1% 迅速增长至 18%。

近日,专注于第二代人工智能制药技术的元示科技有限公司完成近亿元最新一轮融资。公司由北京大学前沿交叉学科研究院2017级博士吴佳奇创立,核心研发方向为人工智能虚拟细胞与通用细胞大模型,是国内较早布局细胞级AI药物研发的初创团队。
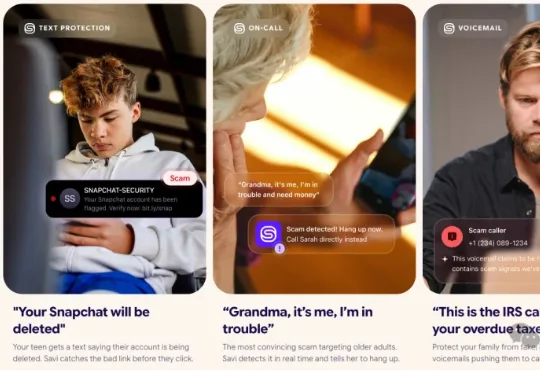
两年前,Patrick Coughlin 的母亲接到了一通电话,来电显示是女儿的号码,电话里也出现了女儿的声音。随后,一名男子声称绑架了她,要求立即支付 1200 美元,否则就会在当地一家沃尔玛的停车场伤害她。
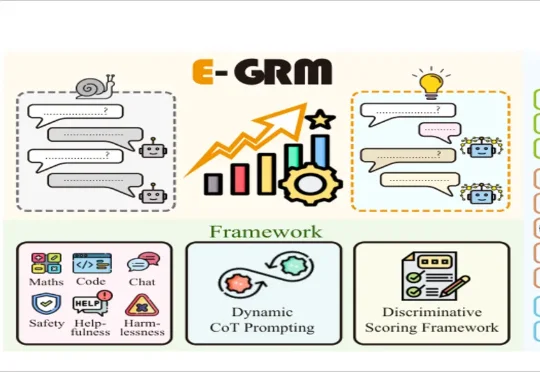
E-GRM的核心思路就是让模型自己判断输入复杂度——通过多次采样看答案是否收敛。收敛了就直接回答,不收敛再触发CoT。在RM-Bench、RMB、RewardBench三个基准上,约58%的样本被智能路由到“直答”,延迟降低62%,同时准确率还有提升。
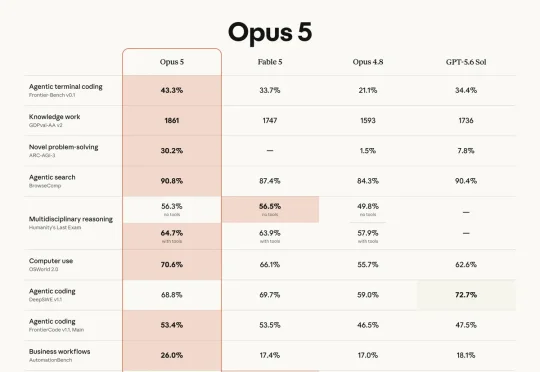
就在刚刚,Anthropic正式发布了Opus 5。这款定位是「深思熟虑且积极主动」的模型,不仅成本只要Fable 5的一半,而且在大多数跑分上直接碾压。在最近的IMO 2026中,它不靠任何外部工具和Agent框架,就拿下了42/42的满分!

金涛今年 26 岁,还是清华在读博士。真正把他带进「推理加速」的,是一个很朴素的判断——当大家都默认 FlashAttention 已经把 Attention 算子做到极致时,他却发现:显卡上明明还有更快的计算单元没被用起来 ——「这么明显的收益,为什么没人做?」
7 月 24 日,Vivix 正式发布两款激活参数约 30B 的模型 Vivix-A1(开放世界演员)和 Vivix-W1(开放世界剧情)。这次发布试图回答的问题不是"生成能不能更快",而是更前一步的:模型在持续生成音视频的同时,能不能随时接住用户的新输入,并即时改变正在生成的内容?