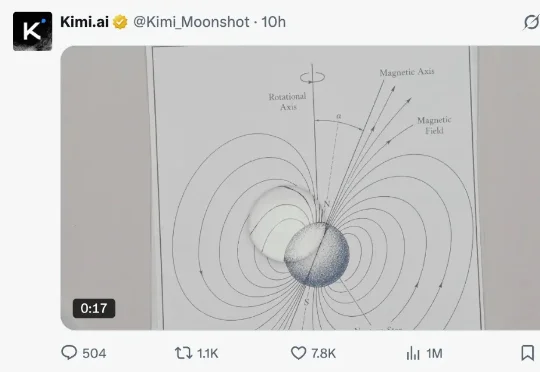
匿名模型Kivine外网刷屏,开发者们都在猜:这是Kimi-K3?
匿名模型Kivine外网刷屏,开发者们都在猜:这是Kimi-K3?这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。
来自主题: AI资讯
9523 点击 2026-07-16 20:21
 搜索
搜索
这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。

很多人以为,把一个大模型放进手机或电脑,就像下载一个 App 一样简单。实际上,手机、电脑和智能硬件的芯片各不相同,同一个模型换一台设备,往往就要重新适配。Nexa AI 做的,就是解决这部分最麻烦也最容易被忽视的工作。

困扰统计学界整整20年的核心悬案,被AI击碎了。

全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。
Emergent 是一家帮助小型企业利用人工智能构建应用程序的初创公司,近日完成 1.3 亿美元融资,跻身为数不多达到独角兽估值的印度 AI 初创公司之列。据该公司介绍,目前已有逾 1200 万个 AI 应用程序通过 Emergent 平台构建完成。Emergent 的运营总部位于班加罗尔。

昨天刚完成2亿美元Pre-IPO轮融资,逐际动力没有急着讲资本故事,而是立马甩出一段全尺寸人形机器人Oli全自主做家务的视频:
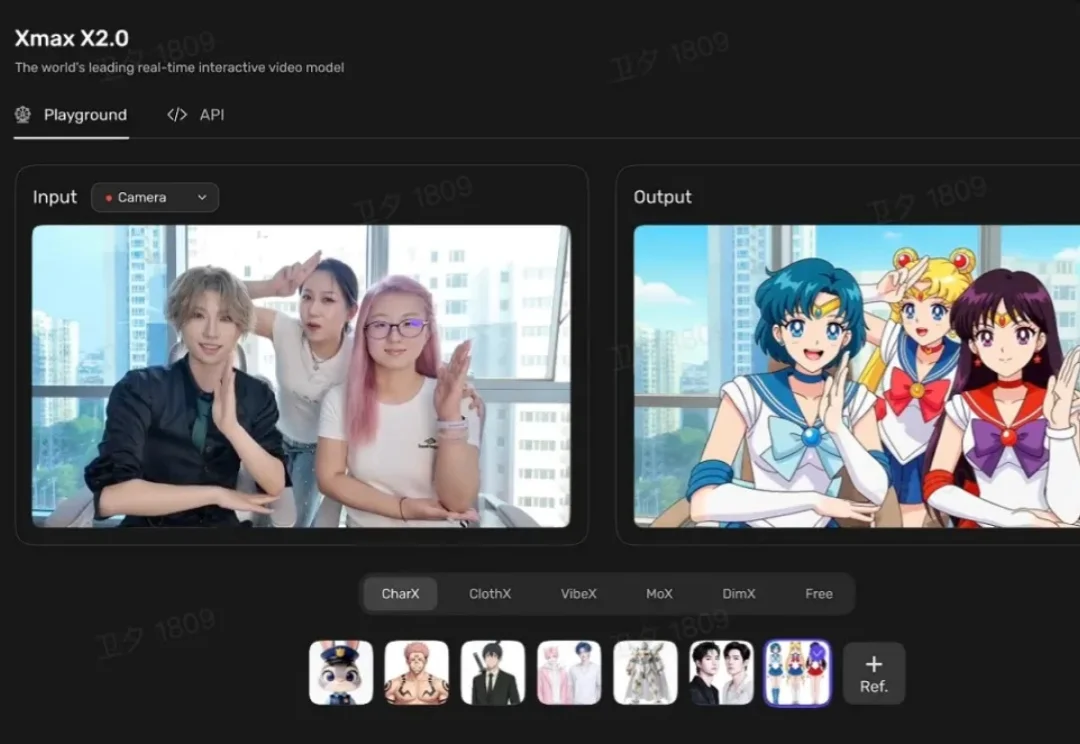
我们先来看两个画面。

WorldArena 1.0 的核心意义,在于将世界模型评测从 “好不好看” 推进到 “是否真的有用”。它不再只关注视频观感,而是把物理一致性、可控性、3D 准确性和具身任务功能性纳入统一评测框架,使许多看似流畅的生成结果第一次在机器人具身任务中接受检验。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
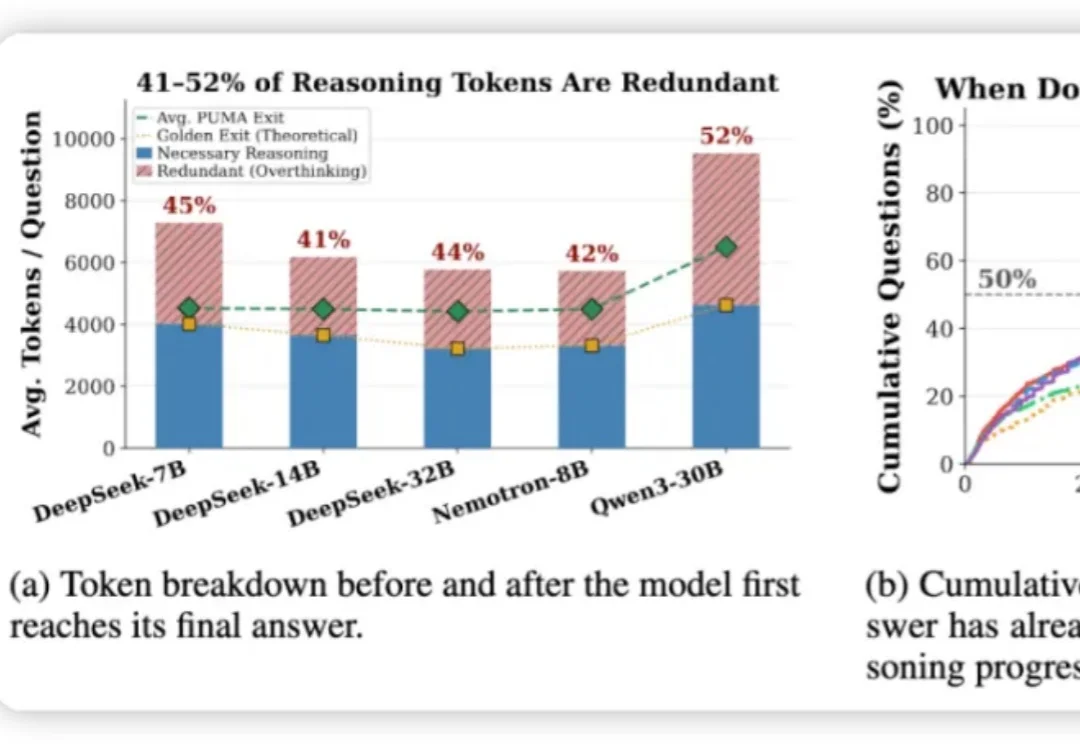
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。