
Claude 进军 K12,AI 巨头终于开始抢学校了
Claude 进军 K12,AI 巨头终于开始抢学校了7 月 14 日,Anthropic 正式发布 Claude for Teachers,面向美国 K12 教师免费开放高级功能,支持备课、课程设计、学习分析等教学场景。而在此之前,OpenAI 已经推出 ChatGPT for Teachers,同样聚焦教师教学支持,并计划向美国 K12 学区开放。
来自主题: AI资讯
8416 点击 2026-07-18 10:11
 搜索
搜索
7 月 14 日,Anthropic 正式发布 Claude for Teachers,面向美国 K12 教师免费开放高级功能,支持备课、课程设计、学习分析等教学场景。而在此之前,OpenAI 已经推出 ChatGPT for Teachers,同样聚焦教师教学支持,并计划向美国 K12 学区开放。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。

曾推出 RoboTwin 系列基准的团队发布了 RoboDojo,一套统一覆盖仿真与真实机器人操作的具身智能评测体系。它包含 42 个仿真任务、18 个真实机器人任务,并将 30 个代表性机器人策略放到同一套标准下比较。

7 月 17 日,2026 世界人工智能大会在上海开幕。展览首次扩展至「三地四馆」,总面积超过 10 万平方米,1100 余家企业带来 3000 余项展品,其中超过 300 款产品在大会期间全球首发。智算与具身智能首次成为并列的核心赛道,各自聚集超过 200 家企业。从开展后的排队人流,到机器人展台前层层举起的手机,AI 依然是当下关注度最高的科技议题之一。
随后,SpaceXAI 兑现了承诺,在 GitHub 上正式开源了这套智能体编程框架。该公司在一篇 X 帖子中表示:“开源 Grok Build 可以让任何人都能参与构建可靠且强大的框架。”开源不到 20 个小时,Grok Build 已在 GitHub 上收获 1.21 万颗 Star。

ICML 2026落幕了。

8万块积木,15个小时!
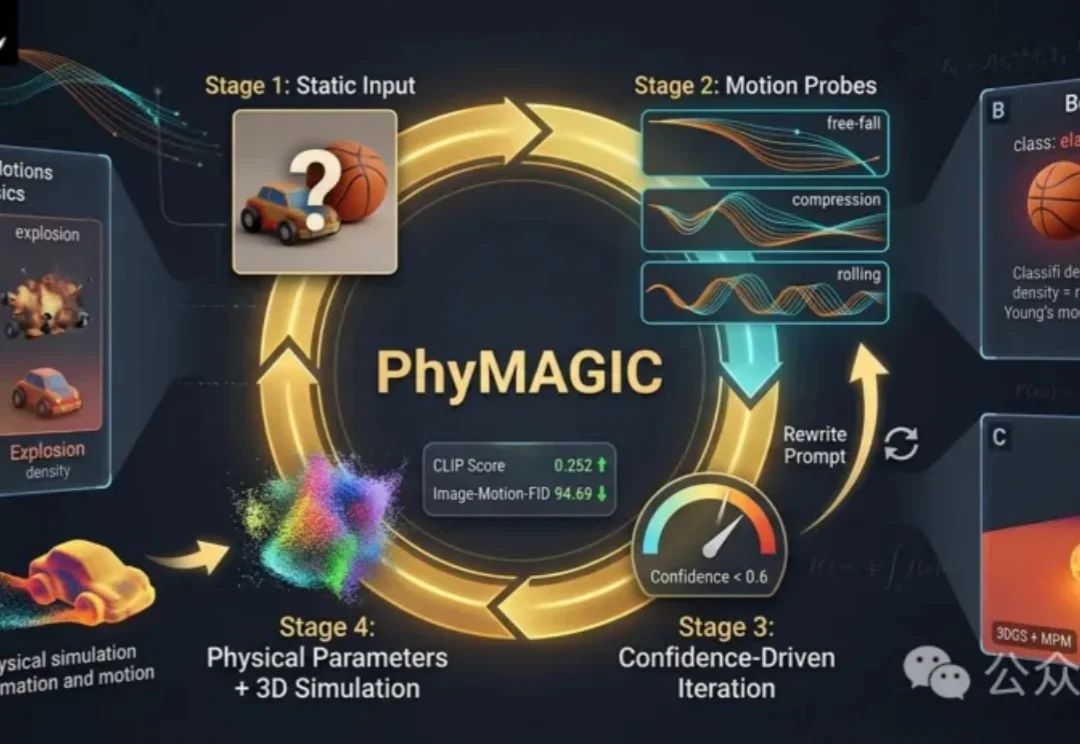
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。

刚刚,机器人顶会RSS 2026论文奖项出炉!

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。