# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在文章开始前,请您先打开Claude code,输入/skill,检查一下您的Claude code有多少个skills?是20个?50个?还是已经突破了100个?自从Anthropic推广Agent Skills以来,我们都爱上了这种“即插即用”的模块化体验。它把臃肿的多智能体编排(MAS)变成了一组优雅的Markdown文件调用,让API账单和延迟同时暴跌了50%以上。

看起来我们已经找到了Agent开发的圣杯。只要给一个Agent挂载上几十甚至上百个Skill,好像它就能包打天下。
但事实并非如此,Anthropic文档鼓励大家创建各种Skills,但没有明确说如果在 .claude/skills/ 里放了200个Skills会发生什么。


就像CPU有缓存未命中一样,LLM的技能检索也存在物理极限。来自UBC、Vector Institute和CIFAR的最新论文模拟了这个场景,并发现了“Agent Skills的扩容墙”。这项研究用数据证明,随着技能库规模的线性增长,Agent的清醒程度会经历一次非线性的“相变”,并据此总结了6条用于开发的黄金法则。
这篇文章将带您深入剖析这项研究,揭示单体智能体的“认知极限”,并为您在2026年构建稳健的Agent系统提供一套基于科学的避坑指南。
在Agent Skills普及之前,解决复杂问题的主流方法还是多智能体系统(MAS)。但近半年来,行业发生了从MAS到SAS(单智能体)的迁移。
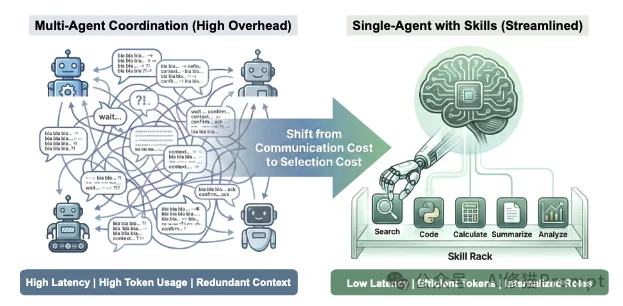
过去,为了解决复杂推理任务,业界倾向于使用多智能体系统。比如一个编码任务,可能需要:
这种架构虽然有效,但存在显著的计算开销:
论文提出了一种名为“编译”的视角。研究者认为,多智能体系统可以被“编译”成一个等价的单体系统。
在这个过程中,原本独立的“智能体角色”被内化为单体智能体的一个技能(Skill)。

一个标准的技能包含三个要素:

研究者在GSM8K(数学)、HumanEval(代码)和HotpotQA(问答)三个基准上进行了对比实验。结果显示,经过编译后的单体智能体在保持准确率(甚至提升 +0.7%)的同时,实现了效率的飞跃:
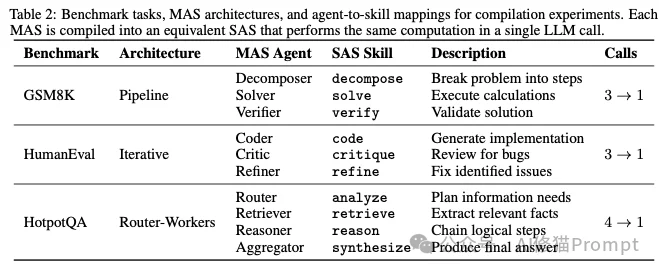
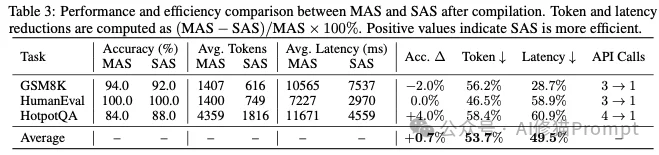
这意味着,在小规模场景下,用Skills取代Multi-Agents是绝对正确的工程选择。
尽管将多智能体系统(MAS)编译为单体技能(SAS)能带来显著的效率红利,但研究者强调,这种转换并非总是数学上可行的。论文提出了“可编译性”(Compilability)的严格定义:只有当编译后的单体系统能产生与原多智能体系统完全一致的输出分布时,编译才是合法的。

为了判断您的系统是否适合“降维打击”,研究者给出了三个充分且必要的判定条件(Proposition 3.1)。只要违反其中任何一条,就必须保留多智能体架构,否则会导致功能失效:
典型的不可编译反例:
基于上述边界,研究者明确指出以下三类架构不可使用Skills替代:
如果您在用CC或者Codex做开发,绝大多数企业业务流程(审批、ETL、文档生成)都满足上述条件,因此都可以“降本增效”转为Skills。但如果您在做博弈模拟或隐私计算,请保留多智能体架构。
既然单体智能体如此高效,我们是否可以无限制地向其中添加技能?比如将整个公司的500个业务流程都写成Skill丢给Claude?
论文给出的答案是否定的。研究者发现,大语言模型(LLM)在选择技能时,表现出了与人类高度相似的有界理性(Bounded Rationality)。
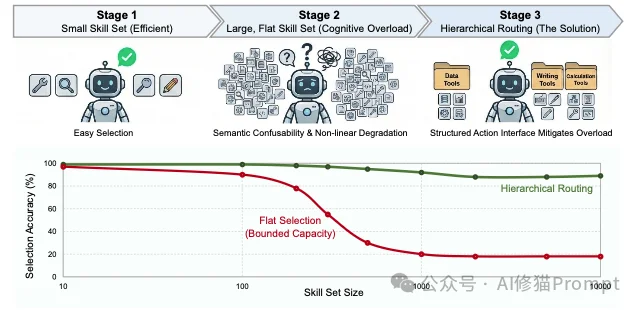
研究者构建了包含5到200个技能的合成库进行压力测试。实验结果揭示了一个非线性的“相变”模式:
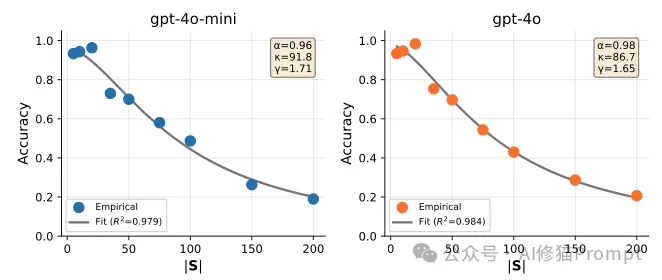

为什么单纯增加技能数量会让AI变笨?为了解释这一现象,研究者没有生造新的AI术语,而是从人类认知心理学的故纸堆中找出了两个经典理论。他们发现,LLM在面对海量选项时的表现,像极了超负荷运转的人类大脑。


这一发现给所有Agent开发者敲响了警钟:智能体不是无限的容器,它的注意力带宽是有物理边界的。
如果仅仅是数量多,模型为什么会选错?研究者进一步剖析了导致崩溃的根本原因。
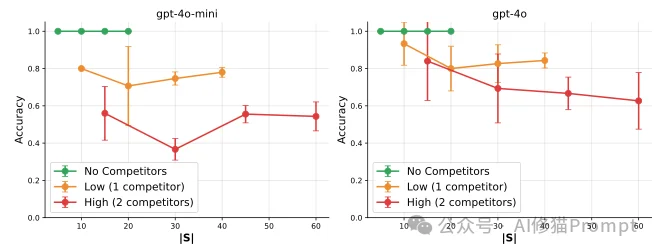
实验表明,技能之间的相似度比技能的总数更致命。
研究者设计了一组对照实验:

一个反直觉的发现是:技能的具体执行指令(Policy)长短,并不影响选择准确率。
研究者测试了三种复杂度的指令:
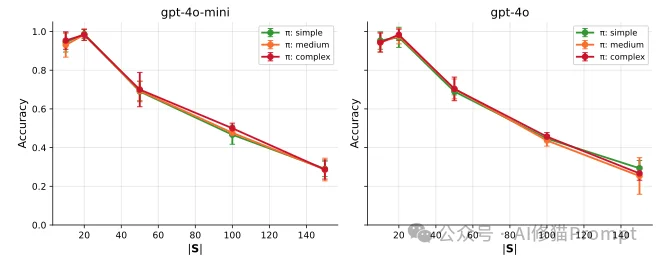
结果显示,这三条曲线几乎重合。这表明,模型在选择阶段(Level)主要依赖技能的描述符(Descriptor),而不会被加载进来的长篇大论的执行细节(Level)挤占认知带宽。
对开发者的启示:您可以在 SKILL.md 的正文里尽情编写详细的Prompt,这不会降低模型“找到”这个技能的能力;但请务必精简和优化YAML头部的 description。

为什么人类能管理成千上万个概念而不崩溃?论文引用了两个关键心理学理论:

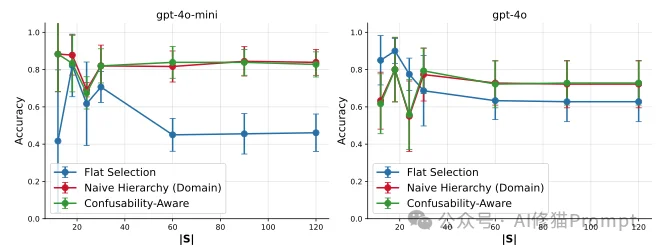
论文并没有止步于理论,而是设计了两种具体的工程实现:
1.朴素领域分层(Naive Domain Hierarchy)
2.抗混淆分层(Confusability-Aware Hierarchy)
search_user 和 find_person 可能被分到同一个文件夹,导致第二步选择依然困难。calculate_sum vs compute_total)高度混淆,但因为选项数量极少(通常<5个),模型可以集中注意力进行精细的语义比对。实验数据证明了这种“分而治之”策略的威力:


这套指南是基于研究者在实验中发现的“认知缩放定律”和“混淆度效应”总结出来的工程最佳实践,对于 2026 年正在构建复杂 Agent 的开发者来说含金量极高。如果您正在使用的Agent Skills或类似架构开发应用,以下建议至关重要:



这篇论文实质上是一篇 《Agent Skills架构扩容指南》。好消息是它证实了 Anthropic 提倡的 "Context efficiency" 和 "On-demand loading"是真实有效的,能大幅降低企业成本。坏消息是它警告我们,模型的“选择注意力”是有上限的(约 50-100 个)。如果你给Claude code配了200个Skills,Claude可能会看着那一堆 YAML description 发呆,然后开始乱选,或者该用的时候不用。随着2025下半年Skills的爆发,现在大家的库里肯定装满了Skills。这项研究说明现在的任务不是写更多Skills,而是重构 (Refactoring),按照论文提出的分层路由原则,整理那些扁平的文件夹,避免模型陷入“选择困难症”是最佳行动方向。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
