Hugging Face遭攻击取证受阻,只能靠国产GLM 5.2救场?白宫AI顾问急眼喊话:我们在失去竞争力
Hugging Face遭攻击取证受阻,只能靠国产GLM 5.2救场?白宫AI顾问急眼喊话:我们在失去竞争力近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。
来自主题: AI资讯
6194 点击 2026-07-21 10:31
 搜索
搜索
近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。
7月20日,AI记忆科技公司红熊AI宣布完成数亿元人民币A+轮融资,投后估值近30亿元。本轮由浙江九纬私募基金、嘉兴彰元创业投资与老股东格睿丰联合投资。 这是红熊AI成立以来完成的第6轮融资。过去15个月,公司估值从2025年Pre-A轮的5亿元,到2026年4月A轮超过15亿元,再到此次接近30亿元。

截至今年6月底,我国智能算力规模达2185EFLOPS(每秒执行2185百亿亿次浮点运算)。全国算力设施整体上架率达71.4%,建成万卡以上智算设施52个。传输通道持续拓宽,近两年围绕国家算力枢纽节点建设超70条算力大通道,相关算力枢纽节点间网络性能提升10%。
我刚刚 AGI Bar 小程序里建了一个共享钱包,并往里面充了 1 万块,未来 24h可点开领取

2026 年的 WAIC,人形机器人依然是展馆里最密集的品类。后空翻、跳舞、格斗,各类单机演示轮番上阵,技术完成度一年高过一年。

凌晨两点,城市睡着了,前置仓还醒着。

WAIC 2026 期间,我们和另外几家媒体(机器之心是其中唯一的专业媒体)共同对来到中国的强化学习奠基人、2024 年图灵奖得主 Richard Sutton 做了一场群访。
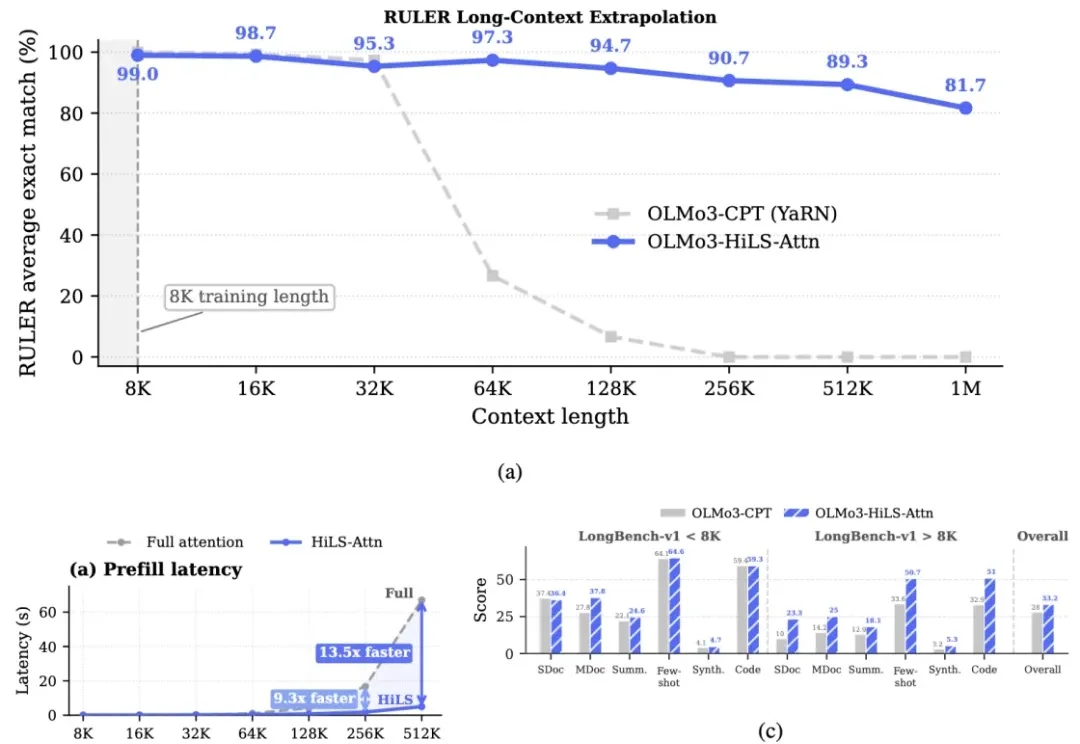
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

如果你走进2026 WAIC的现场,最直观的感受可能只有一个“卷”字。

在计算历史的绝大部分时间里,编程的本质是一项翻译工作:开发者需要在人类理解的维度上剖析问题,设计抽象方案,随后将其转译为机器能够执行的语法。当前的软件工程领域正在经历自高级编程语言问世以来最为显著的变化。