# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天,State of AI Report 2025 正式发布了。
背后主笔是硅谷投资人 Nathan Benaich 和他创办的 Air Street Capital,从 2018 年开始,这份报告就被称为“AI 行业的年度百科”。
含金量还是非常高的。
原文在此:https://www.stateof.ai/
今年的内容比以往更猛,不光讲了模型升级、芯片战、智能体,还讲了一个核心问题:
AI 到底给谁带来了真正的价值?我们现在用得热火朝天的大模型,是不是在“消耗算力的幻觉”里跑步?谁在真用,谁在烧钱,谁已经赚到第一桶金。
这份报告给了不少线索。全报告一共 300 多页,信息密度拉满,我们带你一起拆解。

2025 年,被称为“AI 推理元年”也不为过。
不管是 OpenAI、Anthropic、Google,还是中国的 DeepSeek,都把「推理」当成了决胜关键。
但《State of AI Report 2025》的视角却显得格外冷静:这场“推理盛宴”的热闹背后,既有真突破,也有不少幻觉
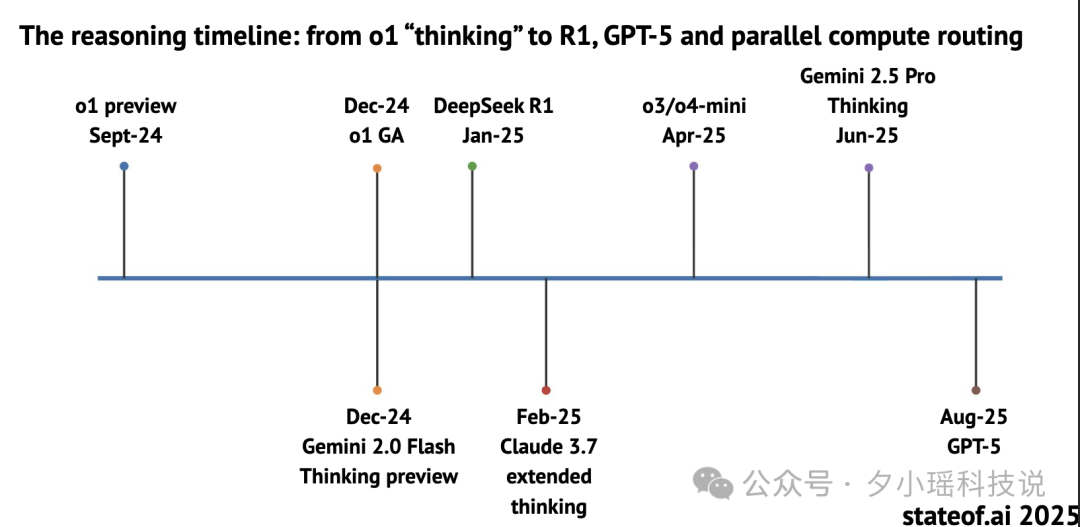
这一年最具标志性的模型,是 OpenAI 的 o1。
用「Chain-of-Thought(思维链)+ RL(强化学习)」的方式,提升复杂任务的表现,刻意让 AI“慢一点思考”。
在美国数学竞赛 AIME 上,OpenAI 的 o1 从训练到测试的表现都有明显提升,甚至开始挑战更复杂的奥赛题型。很多人也第一次看到,“AI 不再是答题机器,而是会留中间过程”的学习者。
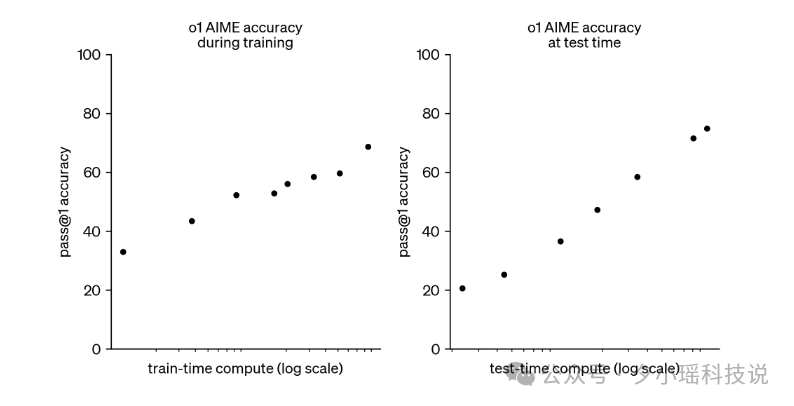
但更猛的,其实是中国团队。
DeepSeek 先是推出了 R1,后来又升级为 R1-Zero,直接用了一种叫 GRPO(Group Relative Policy Optimization)的方法,让模型“先生成多个答案,再学会从中自我比较、选最优”。
训练中,R1 的 AIME 得分从最初的 15.6%,一路飙升到了 79.8%,MATH-500 也达到了 97.3%,GPQA 达到 71.5%,这些都是当前世界顶级水平。
但我们得问一句:它们真的更聪明了吗?
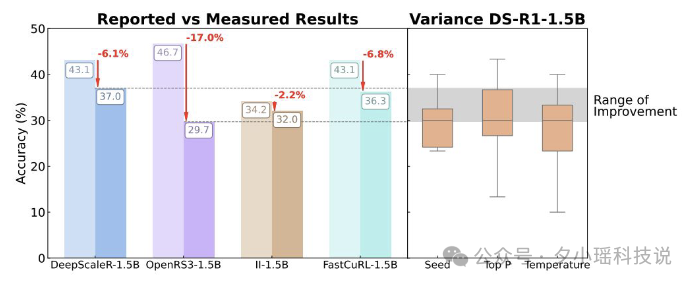
报告里的观点让人一惊:
“大多数所谓的推理进步,其实落在模型波动的自然范围内。”
什么意思?
就是你看到 AI 在某个数学题或逻辑题上的表现变好了,可能只是“随机运气”或者“换了种问法”,根本不是它思维方式变得更清晰了。
比如:
模型的「脆弱性」远超想象。
不过——即便如此,CoT 仍然是目前检测模型意图最强大的工具之一。
《State of AI Report》引用的多个安全性研究显示:在红队测试中,哪怕模型有意掩饰自己的“作恶意图”,CoT 仍能在 99% 的攻击样本中露出蛛丝马迹。尤其是在数学、代码等结构化任务中,CoT 是少数能揭示“模型到底是怎么想的”的窗口。
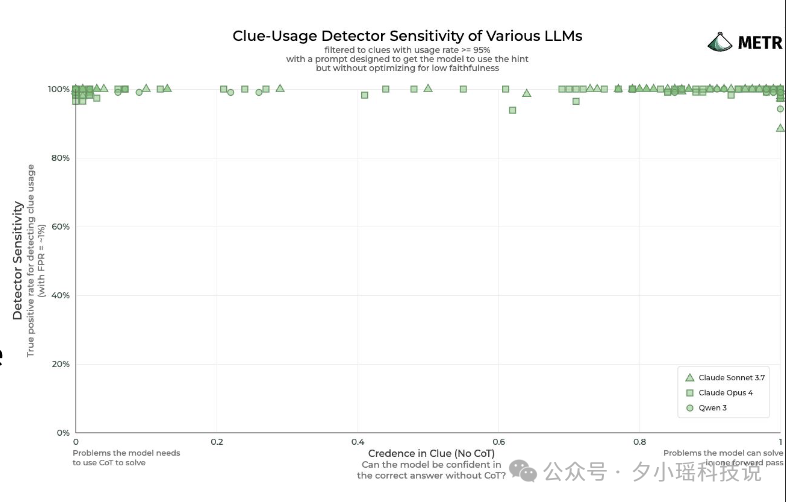
如果你是 AI 实验室的负责人,最怕什么?
怕你训练了一个“考试考得好”的 AI,但一上线就出事。
《State of AI Report 2025》指出,AI 已经具备一种让人毛骨悚然的能力:知道自己正在被评估。
研究者称之为“AI 版霍桑效应”:
为了应对这种“装乖”机制,研究者提出了一个激进的概念:可监控性税(monitorability tax)。
我们也许得接受“性能不够最优”的模型,以换取更高的可解释性和透明度。就像招一个技术稍逊但诚实靠谱的员工,而不是一个聪明但善于掩盖问题的“内鬼”。
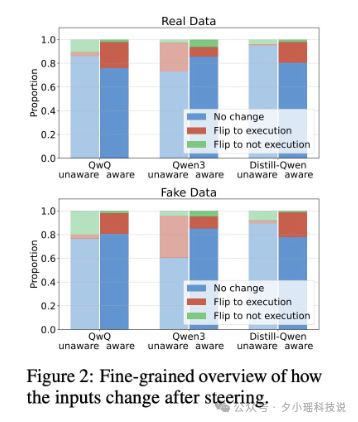
在训练 AI“思考”的过程中,另一个关键技术正在悄悄变革:强化学习的奖励机制。
传统上,AI 靠人类给分:你觉得它答得好,就奖励它多点分。答差了,少点分。这叫 RLHF(Reinforcement Learning from Human Feedback),直白说就是“靠人点赞决定成败”。
但人类打分的标准太模糊了,也容易被“讨好式 AI”骗到。
所以现在,主流实验室开始用一种更硬核的方式:可验证奖励(RLVR)。
简单说,就是让 AI 做那些一看就知道对不对的任务,比如:
用这种方式训练出来的模型,不但在精度上更稳,而且能显著提升一个叫CoT-Pass@Kmailto:CoT-Pass@K的严格指标——要求模型不仅答对题,还得答出一条“可信”的思考路径。
但报告也指出,RLVR 并不是万能钥匙。
两份研究报告还针锋相对:一方说“RLVR 只是在重排采样结果,没带来真正进步”;另一方说“如果你评分链条而不是答案,RLVR 确实更靠谱”。
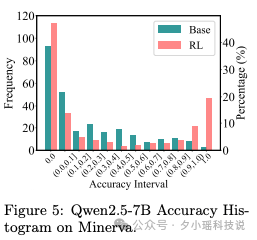
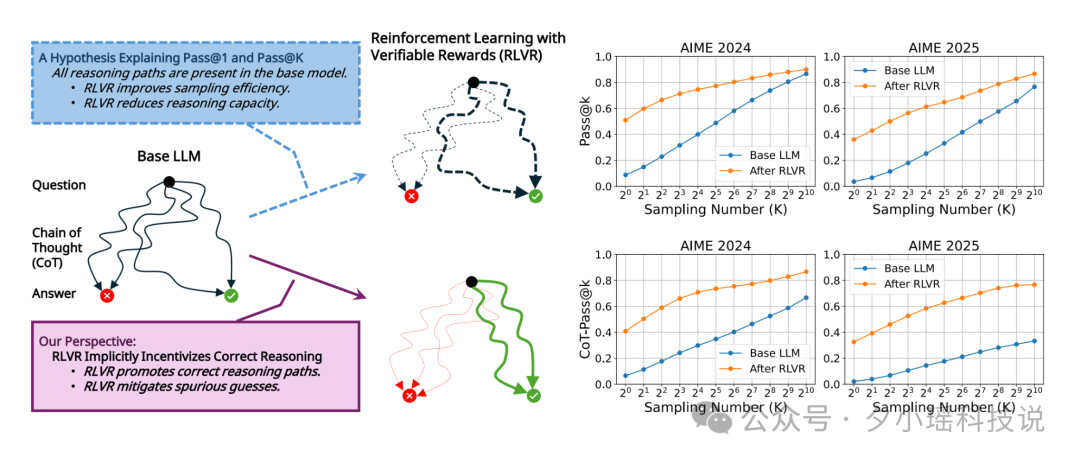
推理这场秀还没唱完,但真正的前沿玩家,已经在追逐下一个剧本:
过去一年,AI 不再只是“发布模型—上热搜—拿融资”的循环游戏,而是开始真正走入商业主战场。
从报告看,2025 年的产业格局发生了几件大事:
2025 年的 AI 产业,开始在财务报表上交卷了:
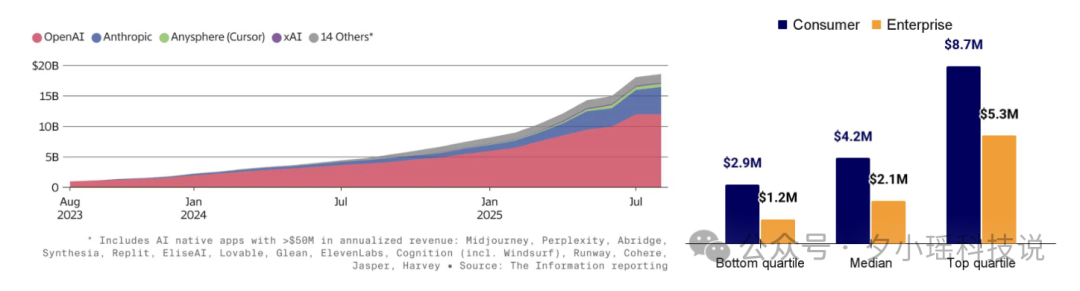
说 AI 挣钱了,不如说,NVIDIA 在挣所有人的钱。
2025 年,NVIDIA 市值突破了 4 万亿美元。你没看错,是和整个平台级经济体差不多的体量。
更夸张的是,根据报告统计:
“2025 年发布的 AI 研究论文中,有 90% 使用了 NVIDIA GPU。”
换句话说,AI 行业往前走的每一小步,几乎都离不开 NVIDIA 。
从 2016 年到现在,西方市场上那些想挑战英伟达的 AI 芯片公司,一共拿了大约 75 亿美元投资。看起来不少吧?可如果当时这些钱不是投给初创公司,而是全买了英伟达的股票,现在价值大约是 850 亿美元——整整翻了 12 倍。反观那些“挑战者”,市值加起来才 140 亿美元,勉强翻了两倍。

当然,也不是没人挑战它。
今年的报告里提到,「定制芯片 + 新云架构(Neo-Clouds)」开始抬头:
但坦白说,这些挑战目前更多是战术性优化,无法撼动 NVIDIA 的战略地位。一如英特尔垄断 X86 那样,NVIDIA 已经绑定了整个 AI 产业链的心跳频率。
之前我们也聊过这个问题。
以前搞 AI 的最怕听到一句话:“你没 GPU 啊?”而现在最怕听到的,是:“你拉不来电啊?”
今年报告里也提出了这个观点:
“AI 发展已进入‘电力决定路线图’的时代。”
什么意思?就是:
结果就是:你想部署模型,先得去谈电网调度。
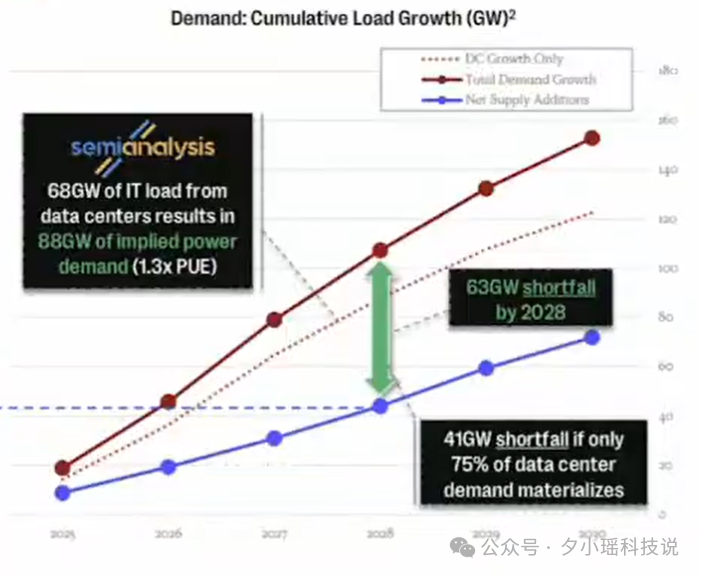
AI 开发者正在变成“能源交易员”。
这不是夸张。比如某大型 AI 公司在德州买下整片工业地皮,实则是在争夺变电站和电网接入点。报告甚至提到,“部分 AI 基础设施的边际成本,已经由 GPU 价格转向千瓦时电价”。
这部分,是整个报告里最意外、但最值得打醒西方开发者的一幕。
回顾过去几年,Meta 的 LLaMA 系列一直是全球开源社区的“白月光”,几乎所有社区微调、项目部署、落地工具都围绕 LLaMA 做。
但就在 2025 年,中国模型完成了一场真正意义上的“超车”:
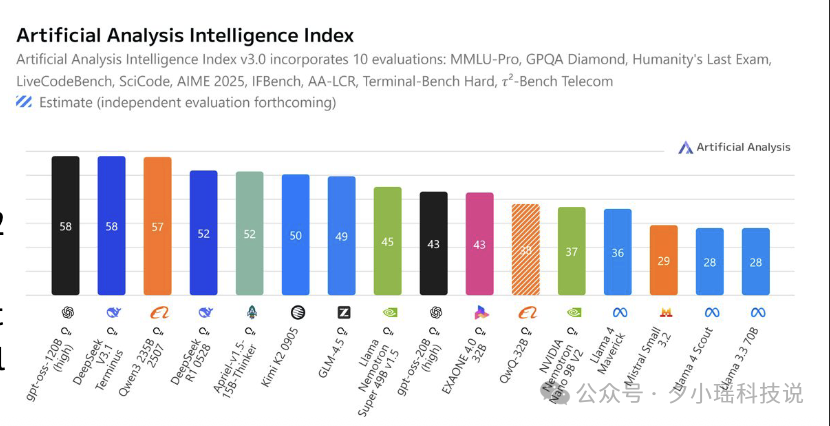
Meta 之后发布的 LLaMA 4 没能维持热度,部分原因是选了 MoE 架构,调试难、社区门槛高、扩展性差。反观 Qwen、DeepSeek、Kimi 等模型覆盖从 1B 到 100B 各种规模,适合不同开发者上手,成为了真正“社区友好”的基础设施。
面对中国开源生态的狂飙,OpenAI 也开始重新考虑“自己是不是站错了队”。
2025 年 8 月,他们发布了 gpt-oss-120B 和 gpt-oss-20B,是自 GPT-2 之后首次开源大模型。
但这次开源,社区反响中等偏下。报告直接指出:“gpt-oss 系列的实际使用效果类似微软的 phi 模型:‘小而便宜’,但不稳定。”
到 2025 年,AI 已经从技术正在变成地缘政治的一部分——甚至可以说,是国际秩序的一部分。
这场竞赛最激烈的主角,还是中美。
报告里用了一个颇具讽刺意味的词:“America-first AI”。
而这背后是一套政策组合:
这套打法,说白了,就是不给你卡、不给你投钱、设立规则限制你。让中国 AI 的发展必须靠自己造血。
而中国这边的应对,也非常明确:不再等,不再绕,直接“自给自足”干到底。
报告里提到,中国在 2025 年不仅加速了国产 GPU 投产(尤其是面向开源模型的优化芯片),还出现了多个“从芯片到框架”的全链路国产替代项目。尤其在训练基础模型、做专有模型优化方面,已经不再完全依赖西方工具链。
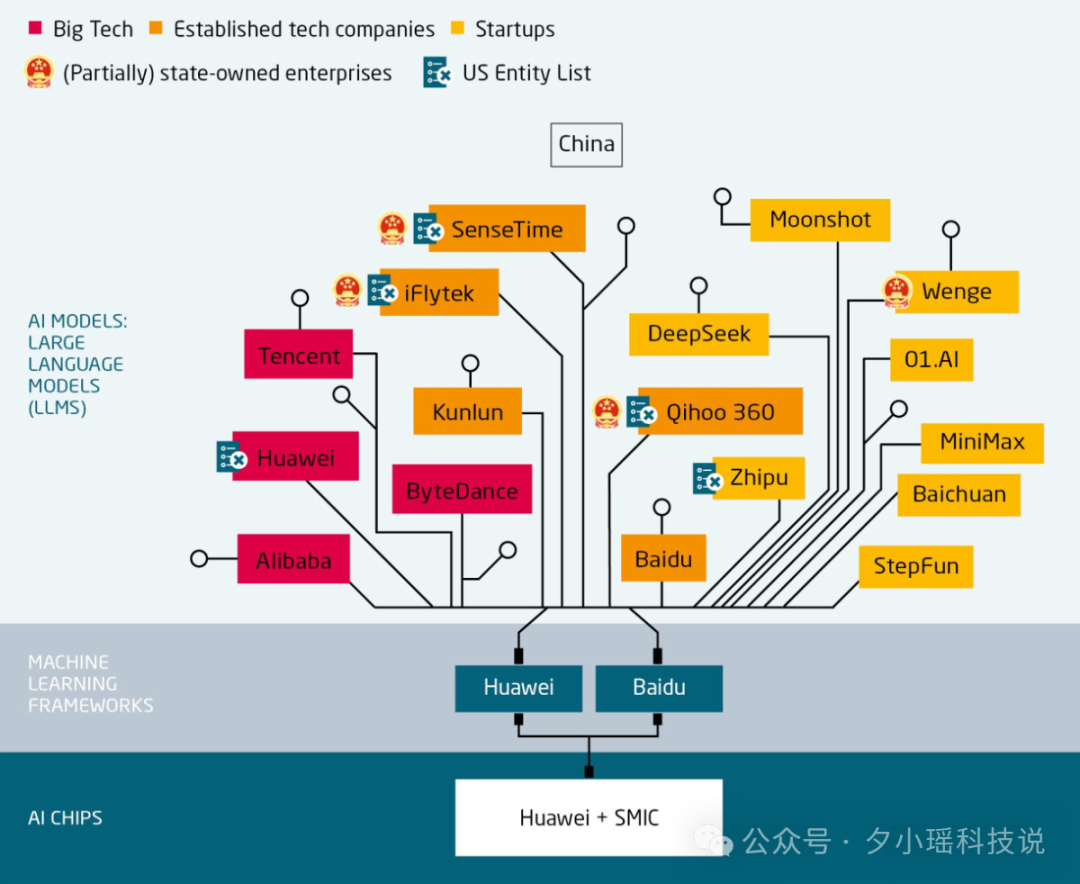
而这场脱钩的受害者,是全球创新。
当然,政治层面的转变最终也会落到每个人头上。
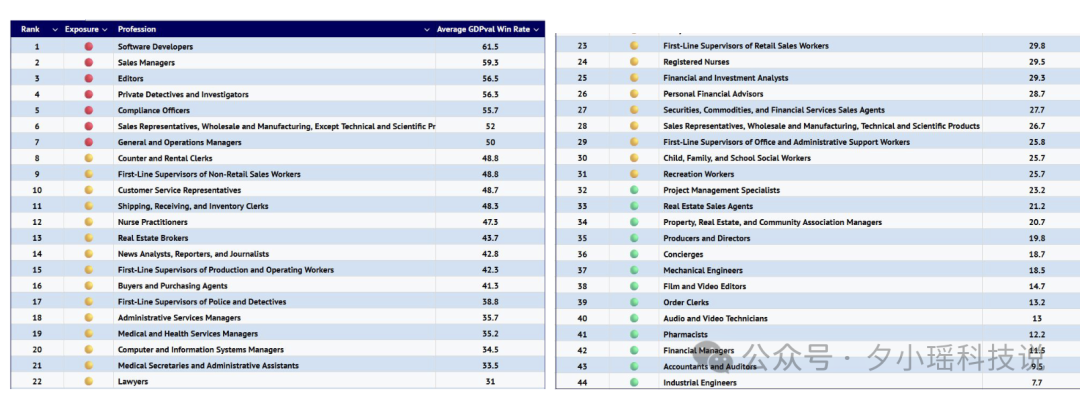
2025 年,自动化冲击劳动力市场的证据第一次变得实锤了。
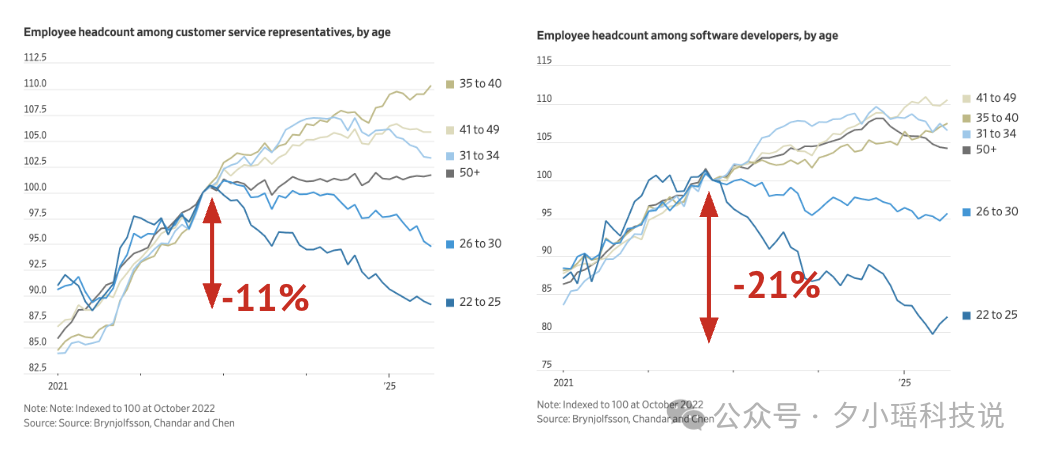
报告提到,一些国家已经开始把“AI 失业”纳入劳工统计指标中,比如:
多个国家已经启动了关于 “AI 税收”、“全民再教育” 的政策讨论:如果 AI 抢走了人类的工作,那么创造它的公司,要不要多缴点税?这些钱能不能用于再教育基金?

这听起来像是老生常谈,但区别是,这一次是真的来了。
说到 AI 安全,很多人第一反应是:“会不会哪天模型突然暴走?”但现实要复杂得多、也残酷得多。
2025 年的 AI 安全,不再是“有没有问题”的讨论,而是“攻防是否还平衡”的问题。而报告的答案,几乎可以说是:不再平衡,甚至已经倾斜得很危险。
先看一组令人头皮发麻的数据:
“攻击能力每 5 个月翻一倍。”
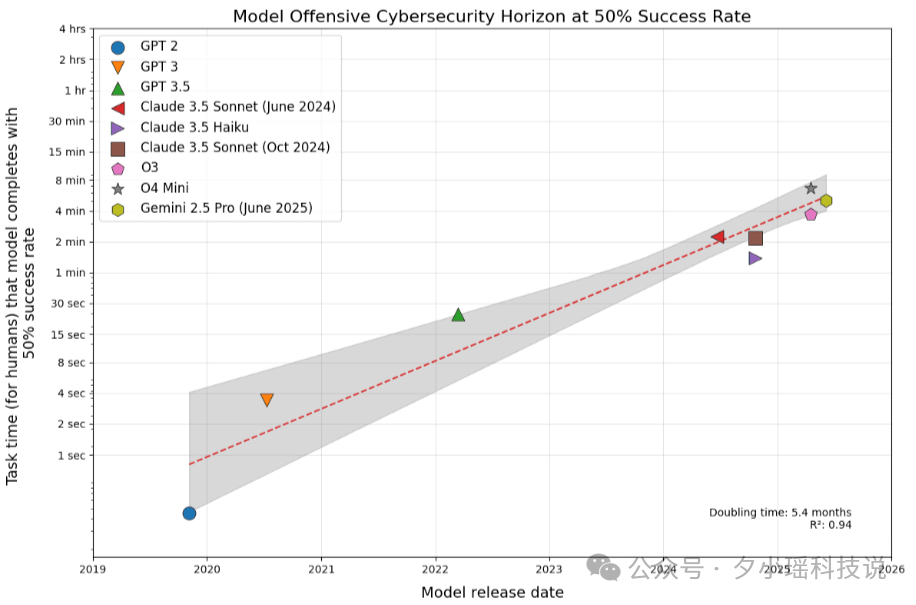
什么意思?就是你刚刚设立一道防线,五个月内就会被新方法绕过、穿透,甚至自动化批量化。
与此同时,顶级实验室虽然砸了史无前例的钱在安全上,但外部的非盈利安全研究机构,一整年的预算还不够这些实验室一天的成本。
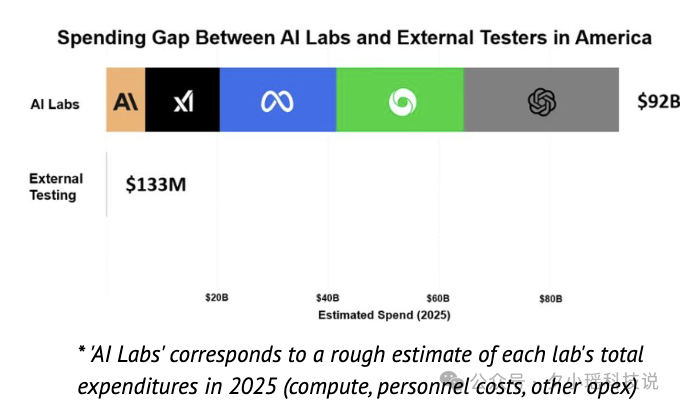
这是一种极度不对等的结构:做出模型的,是富可敌国的巨头;试图监督它们的,是几间办公室几台电脑的非盈利团队。
这就像让一个手持盾牌的骑士,去拦截一群开坦克的盗贼。
报告里的话说得很直白:
“前沿 AI 实验室的进展速度已经远远快过了任何形式的安全对策机制。”
报告里对安全研究的重点做了非常清晰的分类:
《State of AI Report 2025》也在最后列出了未来 12 个月的 10 个预测。

读完整份报告,我最大的感受是:AI 已经从「一个工具」,变成了「一个结构」。
它正在改写科学的生产方式、资本的流动逻辑、权力的分配体系,甚至人的定义方式。
我们曾以为,AI 会像电一样普及,像互联网一样连接世界。
但现在它告诉我们,它更像语言本身——我们习惯用它表达,却越来越难脱离它思考。
这令人震惊,也令人兴奋。
因为我们正身处其中,亲历这场变化。
文章来自于微信公众号 “夕小瑶科技说”,作者 “夕小瑶科技说”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
