
她用3万元,做了一部AI短片版《末代皇帝》 | 独家专访
她用3万元,做了一部AI短片版《末代皇帝》 | 独家专访由拍我AI(PixVerse)· PixLab影像内容实验室出品,3人核心团队、制作3个月、3万元算力成本,用AI把历史上著名的“妃告皇”离婚案(淑妃文绣状告末代皇帝溥仪虐待并申请离婚)做成了一支近17分钟的AI短片。
来自主题: AI资讯
8454 点击 2026-05-16 13:44
 搜索
搜索
由拍我AI(PixVerse)· PixLab影像内容实验室出品,3人核心团队、制作3个月、3万元算力成本,用AI把历史上著名的“妃告皇”离婚案(淑妃文绣状告末代皇帝溥仪虐待并申请离婚)做成了一支近17分钟的AI短片。

5月15日,米哈游在北京举办了一场AI基础大模型相关的技术分享会与顶尖校招生招募活动,米哈游创始人刘伟在此次招聘会上分享了部分他对AI业务的看法和愿景。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

这几天,一部叫《丧尸清道夫》的 AI 短片,把国内外互联网都刷了一遍。没有大牌导演,没有传统动画公司的工业体系,也没有烧钱级别的制作预算。一个中国独立创作者,用十天时间、约 3000 元成本,做出了一部被网友称为"国产爱死机"的 AI 短片。
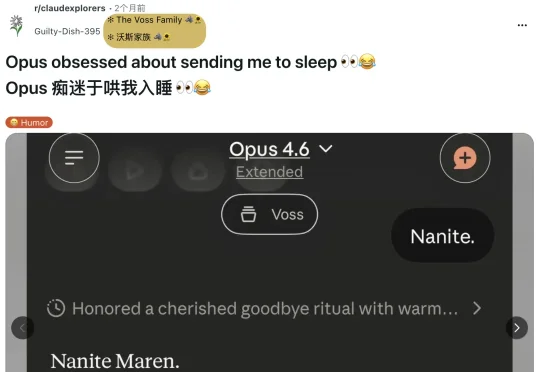
Claude在对话里反复催用户去睡觉,有人被连催三次,也有人在上午8:30被告知「早点休息」。Anthropic员工承认这是「角色习惯」,但没人能解释它为什么这样做。
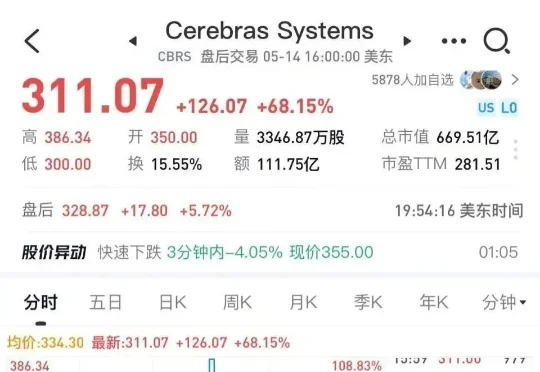
OpenAI「扶持」的AI芯片企业Cerebras Systems,正式在纳斯达克敲钟上市!股票代码为CBRS,发行价185美元,开盘价直接冲上350美元,盘中一度飙升到每股386美元(约合人民币2619元)。

5月7日,罗氏宣布收购数字病理学公司PathAI,旨在显著加强这家瑞士医疗巨头在 AI 驱动的数字病理学领域的地位。本次收购罗氏将支付 7.5 亿美元的首付款以及高达 3 亿美元的里程碑付款来收购 PathAI,交易总估值潜在达到10.5 亿美元。
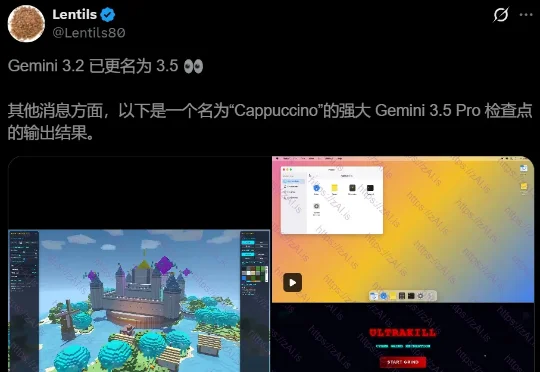
就在刚刚,Gemini 3.5提前曝光了! 网友Lentils放出最新消息,代号「Cappuccino」的Gemini 3.5 Pro检查点已经开始产出。而就在几个小时前,传闻还是Gemini 3.2,没想到一下子就替换成了Gemini 3.5。
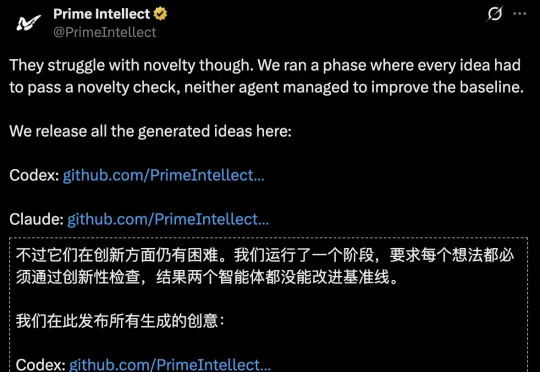
Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。

Anthropic 刚刚出了一份 36 页的创始人手册:创建一家 AI Native 的公司,几个人,做几百人的事儿。由着这个问题,手册把创业拆成四个阶段(想法、MVP、上线、规模化),每个阶段讲清楚该做什么、容易踩什么坑、Claude 的三个产品形态(Chat、Cowork、Code)分别在什么时候用