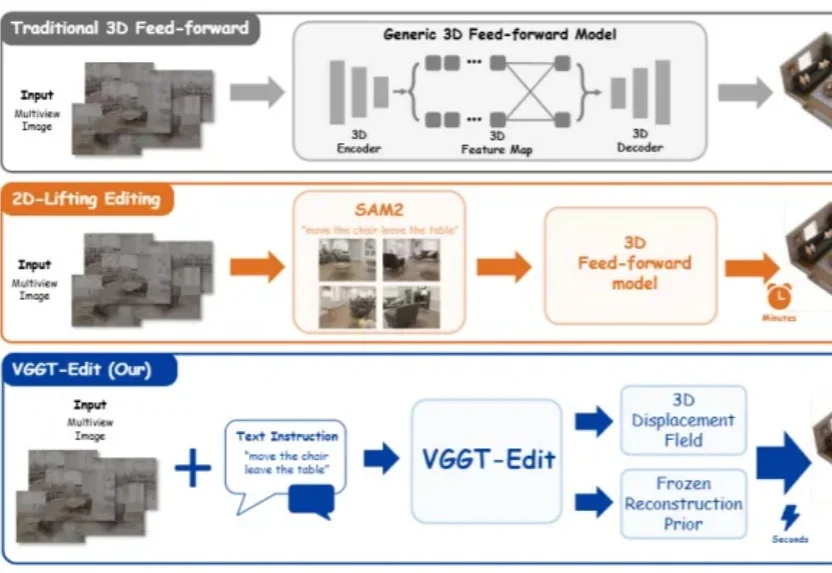
5秒完成3D场景编辑,北大&港中文&上海AI Lab搞出VGGT-Edit,120倍加速太炸了
5秒完成3D场景编辑,北大&港中文&上海AI Lab搞出VGGT-Edit,120倍加速太炸了3D世界“会看”了,但还不会“改”。
来自主题: AI技术研报
8801 点击 2026-05-28 09:52
 搜索
搜索
3D世界“会看”了,但还不会“改”。
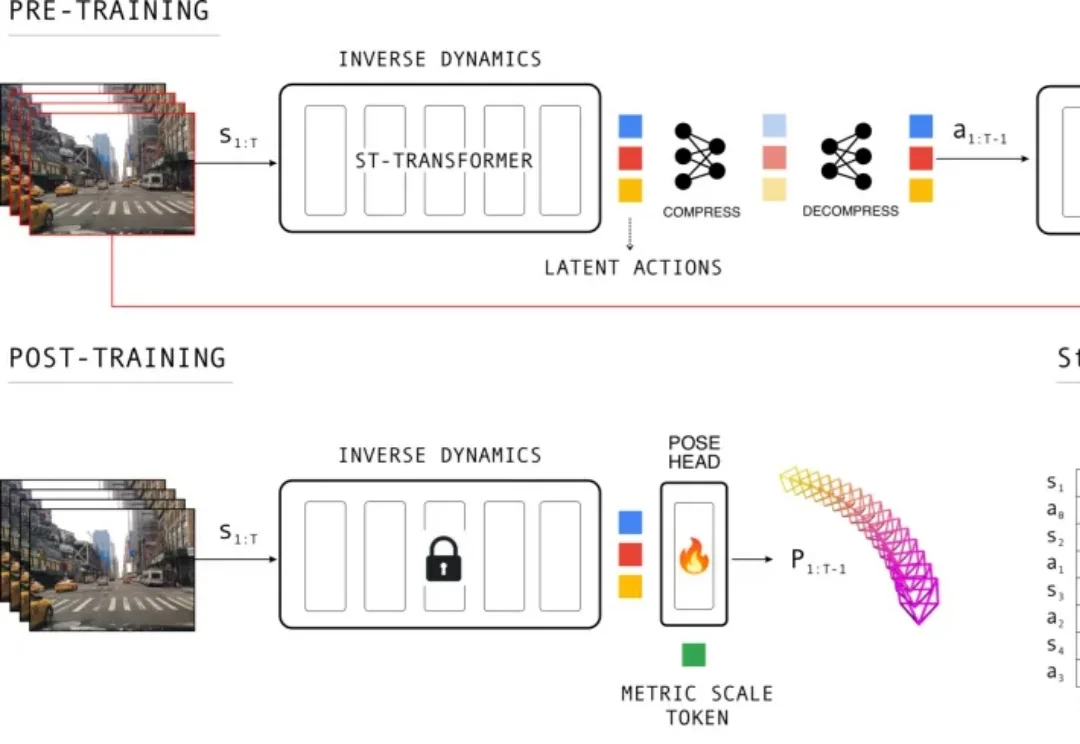
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。
我们知道,世界是三维的。
这两天刷 X 的时候,发现一类项目特别火,就是用 Codex + Blender + 3D 生成工具做的交互式 3D 模型网站。
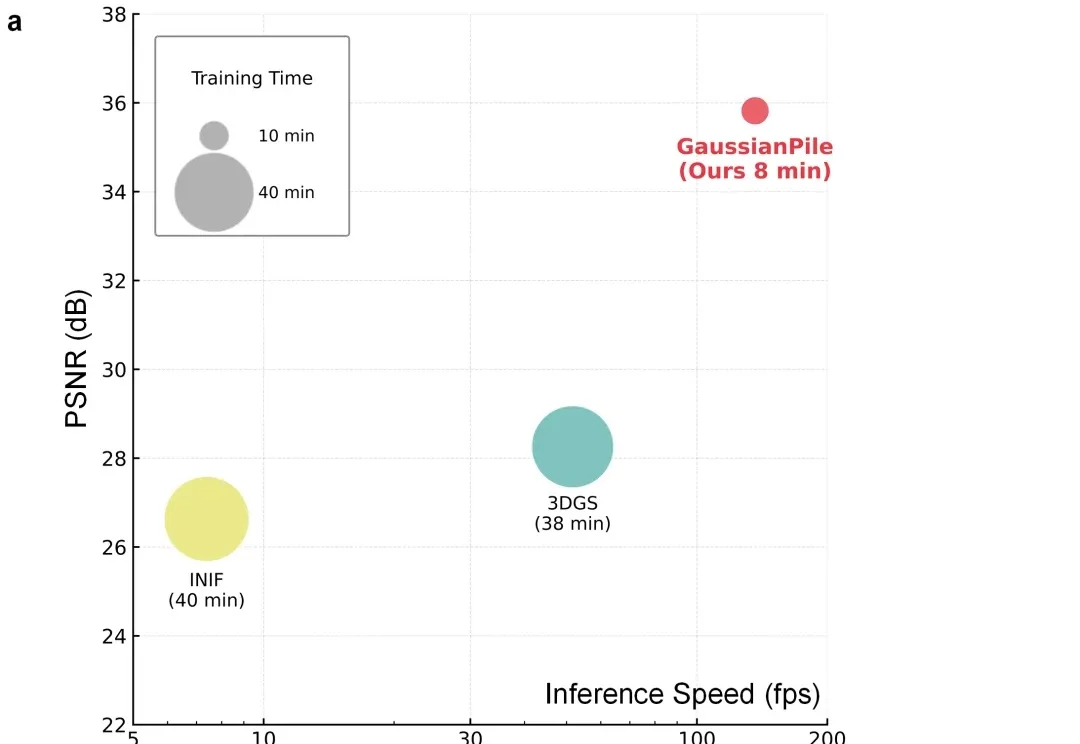
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
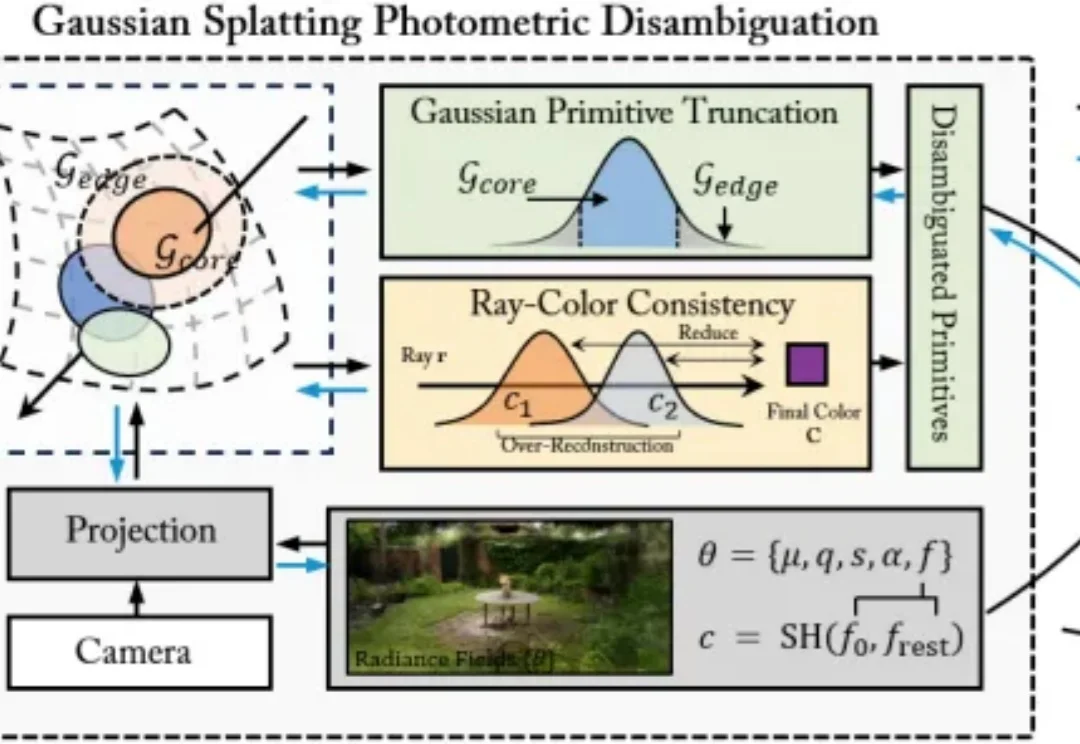
近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。

当下,在Codex、Claude code等AI产品,对设计、代码等行业碾压过后,AI又对游戏这个复杂行业“降临”了。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

2021 年,陈天润还在浙江大学读本科。那一年 ChatGPT 不存在,大语言模型远没有破圈。“世界模型”这个概念刚刚冒头,但陈天润做了一个当时看起来相当激进的决定:成立一家公司,做 3D 和 AI。