
千问AI眼镜首次重大升级:看一眼扫单车,学会主动服务,首次实现3D空间显示
千问AI眼镜首次重大升级:看一眼扫单车,学会主动服务,首次实现3D空间显示刚刚,阿里旗下首款AI眼镜——千问AI眼镜S1迎来开售后的首次重磅更新,发布了海量新功能升级。从AI主动编排执行复杂任务、AI制定运动计划、AI订票点外卖到AI扫单车、AI拍照解题等,智东西第一时间现场体验了这些新功能。
来自主题: AI资讯
8922 点击 2026-05-08 21:09
 搜索
搜索
刚刚,阿里旗下首款AI眼镜——千问AI眼镜S1迎来开售后的首次重磅更新,发布了海量新功能升级。从AI主动编排执行复杂任务、AI制定运动计划、AI订票点外卖到AI扫单车、AI拍照解题等,智东西第一时间现场体验了这些新功能。
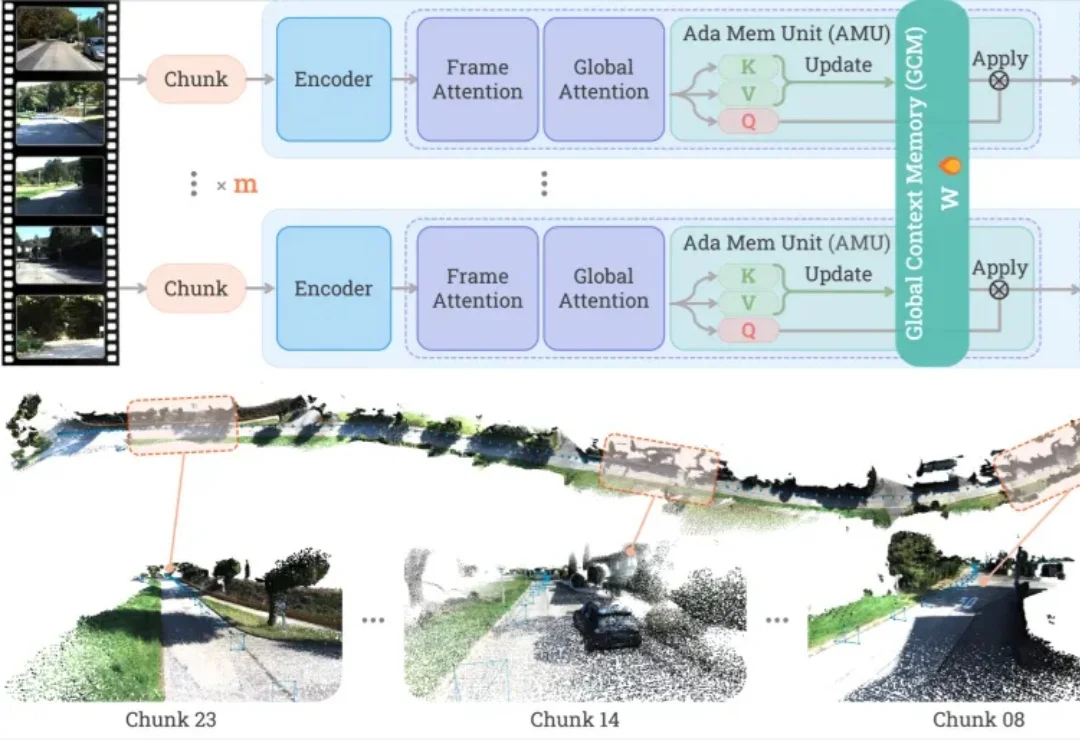
长视频 3D 重建最怕的,其实不是 "看不清"。
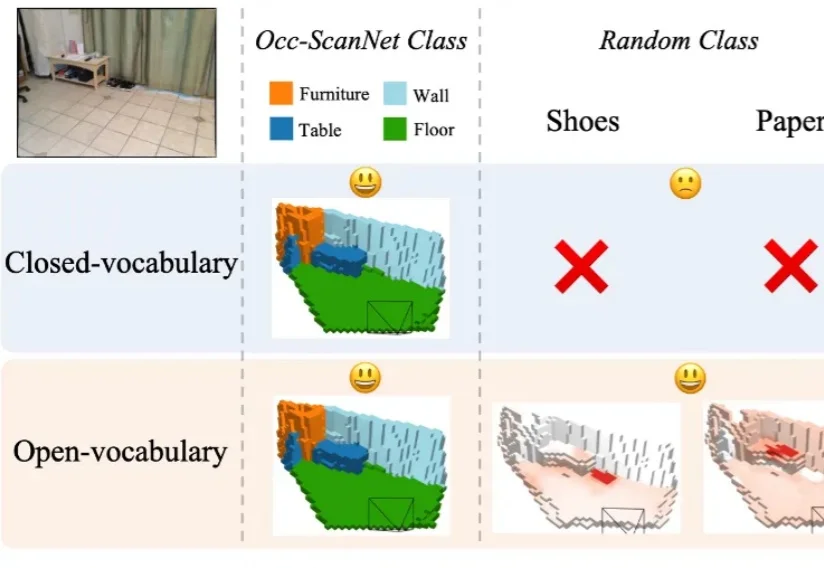
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」
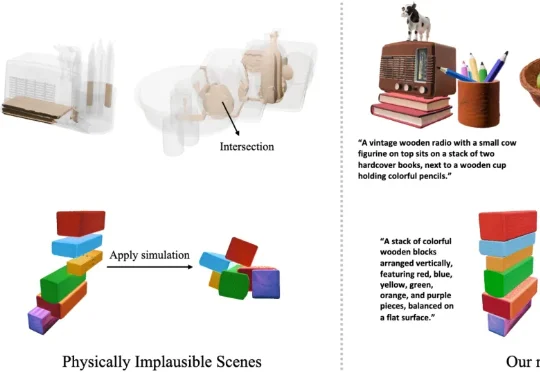
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。
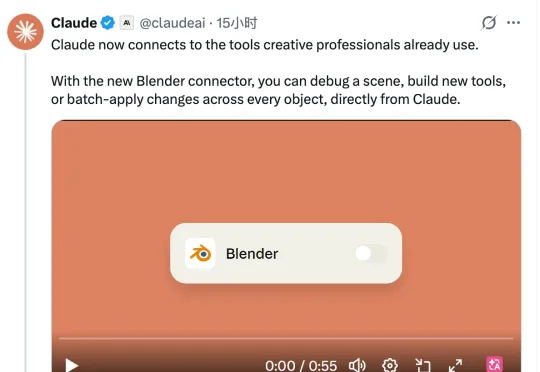
今天,Anthropic一口气甩出9个设计师专属连接器,以后可以直接在Blender、Photoshop、Premiere这些专业设计软件中使用Claude了。与先前推出的Claude Design不同,这次Anthropic不是要在自家软件里大包大揽,而是把Claude塞进了各大设计软件,用户可以用自然语言在Claude中使用这些专业设计软件,实现对3D模型、平面设计以及音乐等文件的创造和修改。

Anthropic今天宣布与Blender、Autodesk、Adobe、Ableton、Splice等多家合作伙伴联合推出一批连接器,涵盖了3D建模、平面设计、音乐制作和现场视觉等多个领域的创意工具,让Claude能够直接在创意专业人士日常使用的软件中运行。

在真正熟悉3D高斯泼溅技术的圈子里,“大规模3D高斯模型在移动端打开” 的技术早已不是什么新鲜事。两年前就有一家深圳创业公司,做出来并推出完整产品,甚至开源至GitHub。
今日,蚂蚁灵光App上线“体验世界模型”功能,成为业界首个可在移动端体验世界模型的智能助手,实现了分钟级一致性和实时可交互体验。用户只需上传一张图片,即可在手机上探索最长60秒的3D世界,并通过手游摇杆操控视角,像玩游戏一样在其中走动。从触发指令到开始探索,整个过程仅需秒级。