# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从单张图像生成灵活视角3D场景的技术来了,在考古保护、自主导航等直接获取3D数据成本高昂或不可行的领域具有重要应用价值。


这一任务本质上是高度不适定的:单一的2D图像无法提供足够的信息来消除完整3D结构的歧义,
尤其是在极端视角(如180°旋转)下,先前被遮挡或缺失的内容可能会引入显著的不确定性。
生成模型,特别是扩散模型,为解决这一问题提供了一种潜在的技术路径。
尽管现有方法通常依赖预训练的生成模型作为新视角合成的先验,但它们仍面临显著挑战。
例如,基于图像的扩散方法容易累积内容误差,基于视频的扩散方法则难以处理可能生成的动态内容构建静态3D场景的影响。
最近的研究尝试通过在视频扩散模型中引入点云先验来提升一致性,虽然取得了一定进展,但在可扩展性方面仍存在局限,尤其是在大视角变化下的表现有待提升。
针对上述问题,人大高瓴李崇轩、文继荣团队、北师大王一凯团队与字节跳动的研究员提出了一种新方法FlexWorld,用于从单张图像生成灵活视角的3D场景。
与现有方法不同,FlexWorld通过合成和整合新的3D内容,逐步构建并扩展一个持久的3D表示。

该方法包含两个核心组件:
(1) 一个强大的视频到视频(video-to-video, V2V)扩散模型,用于从粗糙场景渲染的不完整图像生成完整的视角图像;
(2) 一个几何感知的3D场景扩展过程,用于提取新的3D内容并将其整合到全局结构中。
研究团队在精确深度估计的训练数据上对先进的视频基础模型进行了微调,使其能够在大幅度相机变化下生成高质量内容。
基于V2V模型,场景扩展过程通过相机轨迹规划、场景整合和细化步骤,逐步从单张图像构建出支持灵活视角观察(包括360°旋转和缩放等)的3D场景生成。
通过大量实验,研究团队验证了FlexWorld在高质量视频和灵活视角3D场景合成方面的性能。
FlexWorld在生成大幅度相机变化控制下的视频中展现了出色的视觉质量,同时在生成灵活视角3D场景时保持了较高的空间一致性。
为促进学术交流和技术推广,团队已开源相关代码仓库与训练权重,供研究社区进一步探索和应用。
在多种不同来源的输入图像和相机轨迹下,FlexWorld 中微调的视频模型可以生成较高质量且3D一致的视频内容。
受益于较好的一致性,这些视频可以直接用于3D重建,为后续生成灵活视角的场景提供了较好的视觉内容。

灵活视角的场景生成
根据单张图片输入,FlexWorld可以生成灵活视角下的3D场景,这些生成的场景可以在360度旋转,前进和后退等视角进行探索。
这些场景通过多段视频逐渐构筑生成,旨在扩展出更大的可探索区域,而非仅关注前方区域。

下图展示了FlexWorld的整体框架。
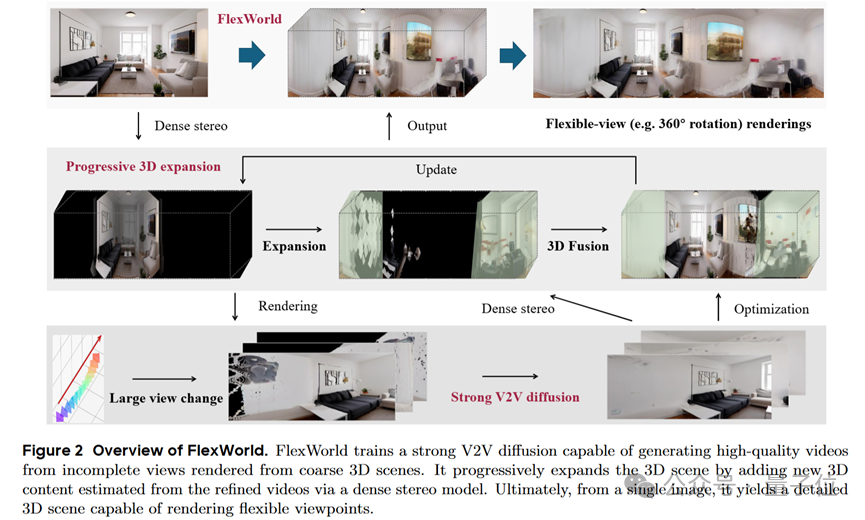
逐步构建场景
FlexWorld采用多段视频逐步构建出一个具有更大可探索区域的场景。
在场景内容不足的区域,FlexWorld渲染出该区域的残缺场景视频,并通过一个经过微调的视频到视频模型,获得补完的场景视频。
在场景融合阶段,视频中的关键帧将会被填充置入场景的不足区域,其他帧则会作为场景表示(即3D Gaussian splatting)的参考图像优化整体场景表征。
支持大转角的视频到视频模型
FlexWorld中包含一个经过微调的视频模型,该模型以视频作为条件,可以从残缺的输入视频中捕捉到相机运行轨迹,
输出符合输入轨迹的完好视频,保持良好的3D一致性。该视频模型选用CogVideoX-5B-I2V作为基座模型,并构造了一系列深度良好的残缺视频-良好视频训练对。
不同于依赖深度估计模型获得的训练对,FlexWorld构建的训练对来自于同一场景密集重建提供的深度,
这种训练对使模型始终明确应该修复的区域,从而能够在推理时支持更大转角的相机运动。
基于视频内容的场景融合
FlexWorld一方面通过高斯优化将多段视频内容融合进持久化的3D表征中,另一方面通过密集立体模型和深度融合策略,
将多段视频的关键帧直接作为初始三维高斯加入表征作为初始化,以充分利用深度估计模型提供的先验和视频内部的一致性。
本文介绍了FlexWorld,这是一个从单张图像生成灵活视角3D场景的框架。
它结合了一个微调的视频到视频扩散模型,用于高质量的新视角合成,以及一个渐进的灵活视角3D场景生成过程。
通过利用先进的预训练视频基础模型和精确的训练数据,FlexWorld能够处理大幅度的相机姿态变化,
从而实现一致的、支持360°旋转和前进后退观察的3D场景生成。大量实验表明,与现有方法相比,FlexWorld在视角灵活性和视觉质量性能方面表现优异。
我们相信FlexWorld具有广阔的前景,并在虚拟现实内容创作和3D旅游领域具有重要潜力。
本文由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队、北京师范大学人工智能学院王一凯副教授和字节跳动共同完成。
共同一作陈路晰和周子晗分别是中国人民大学高瓴人工智能学院的博士生与硕士生,导师为李崇轩副教授。王一凯副教授、李崇轩副教授为共同通讯作者。
论文链接:https://arxiv.org/abs/2503.13265
项目地址:https://ml-gsai.github.io/FlexWorld/
代码仓库:https://github.com/ML-GSAI/FlexWorld
文章来自于微信公众号 “量子位”,作者 :FlexWorld团队



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
