

本地LLM万字救场指南来了!全网超全AI实测:4卡狂飙70B大模型
本地LLM万字救场指南来了!全网超全AI实测:4卡狂飙70B大模型AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。
来自主题: AI技术研报
8713 点击 2025-07-03 18:53
AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。

让游戏行业真正成为创意产业,而不是劳动密集型产业。

2023 年 7 月,《晚点 LatePost》曾独家披露,字节 AI Lab 旗下机器人团队正推进机器人量产。当时曾定下到 2023 年年底,量产 200 台的目标。

刚刚,一支华人主导的AI团队打破硅谷融资纪录。

在AI音乐创作工具日益涌现的当下,近期,一款叫作Mozart AI的应用闯进土耳其iOS音乐榜前十,引发了笔者的关注。它以“图生乐”这一模式切入AI音乐赛道,在过去一年的实现了400万下载量,并创造出超过170万美元的年收入(iOS与Google Play合计)。
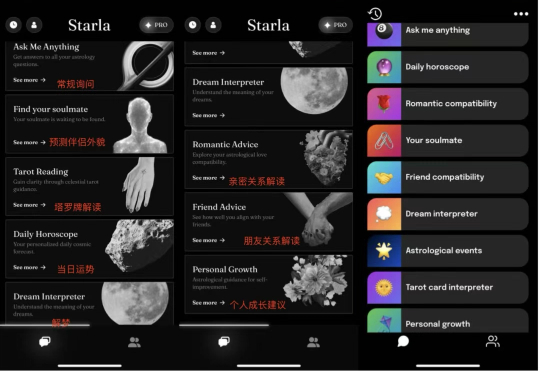
6 月 17 日,一款 AI 占星产品 Starla-Call the Universe 进入了 iOS 美国下载总榜前 10,当笔者以为这又是一个昙花一现的产品时,它不仅能够持续坚守榜单 Top 10 长达半个月,而且到了 6 月 24 日,另一款产品 Astra-Life Advice 也进入了美榜前 10,两款同类产品相继进入 Top 10,并双双持续在榜超 1 周的时间。

机会,就在1年后。"我97岁的爷爷去年冬天洗澡时突然双腿失去知觉,在厕所挣扎一整晚无人发现,差点危及生命。
最近,看到各大厂商,在不断地将自己的AI大模型进行开源。华为宣布开源:盘古7B稠密和72B混合专家模型。
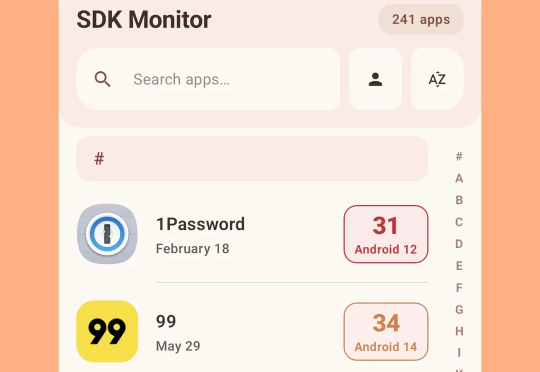
大约 7 年前,我发布了一个名为 SDK Monitor 的小工具应用,用来监控设备上安装的所有应用使用的 targetSDK API 级别。当时正值 Google 开始强制推行 targetSDK 最低版本限制(现在要求至少是去年的版本),于是我的原始应用很快就变旧了。随着时间的推移,我甚至已经无法再打开 Android Studio 去维护它了——开发环境和技术体系早已焕然一新。

你有没有想过,为什么在这个云计算和AI横行的时代,PDF文档处理依然是企业最大的痛点之一?想象一下这样的场景:一份包含数百页的贷款申请文档躺在银行系统里,等待人工审核,而申请人只能苦苦等待几天甚至几周才能知道结果。与此同时,医院里的医疗记录还在用打印机输出,然后手工传递给下一个医生。