

速递| “AI并购整合者”诞生:Multiplier获Lightspeed领投A轮2750万美元,重塑6万亿专业服务市场
速递| “AI并购整合者”诞生:Multiplier获Lightspeed领投A轮2750万美元,重塑6万亿专业服务市场2022 年底,前 Stripe 亚太区业务负责人 Noah Pepper 创立了 Multiplier,这家初创公司最初旨在向税务会计师销售软件。
来自主题: AI资讯
9695 点击 2025-06-19 15:27
2022 年底,前 Stripe 亚太区业务负责人 Noah Pepper 创立了 Multiplier,这家初创公司最初旨在向税务会计师销售软件。
42,这个来自《银河系漫游指南》的「生命、宇宙以及一切问题的终极答案」已经成为一个尽人皆知的数字梗,似乎就连 AI 也格外偏好这个数字。

AI上瘾堪比「吸毒」!MIT最新研究惊人发现:长期依赖大模型,学习能力下降、大脑受损,神经连接减少47%。AI提高效率的说法,或许根本就是误解!

45岁的湾区HR,本来拿着7万美元年薪干得顺风顺水,忽然有一天就被优化了;年薪15万美元的全栈工程师,正帮老板优化AI工具呢,忽然就被AI取代了……亚马逊CEO全员信的曝光,再一次证实硅谷AI裁员潮真来了,Dario Amodei的预言,含金量还在上升。
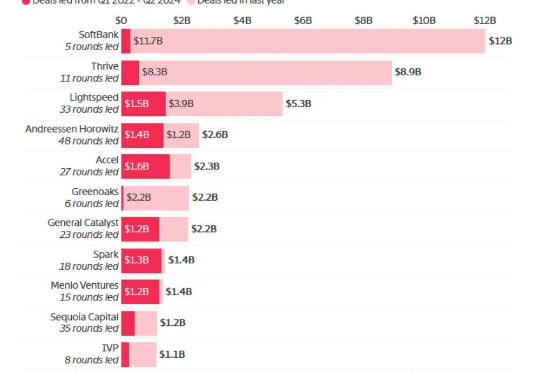
软银、Thrive Capital领跑AI投资狂潮。 智东西6月18日消息,外媒The Information统计了其生成式AI数据库中,自2022年Q1至2024年Q2,507家初创企业的融资轮次,盘点出15家向生成式AI企业投资金额最高的风投机构。
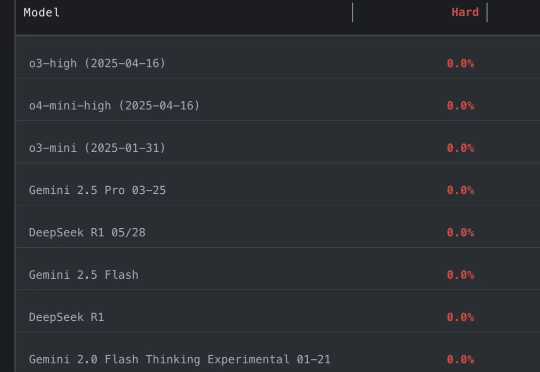
好夸张…… 参赛大模型全军覆没,通通0分。 谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1一众模型全都难倒。

AI想替代谁?谁愿意被替代?北大校友的研究首次揭示数据真相!

xAI正以每月10亿美元的惊人速度烧钱。面对激烈的AI军备竞赛,xAI通过43亿美元的股权融资和50亿美元的债务融资,押注自建基础设施和X平台数据优势,力争2027年实现盈利。这场高风险的豪赌,能否让马斯克再次改写科技史?
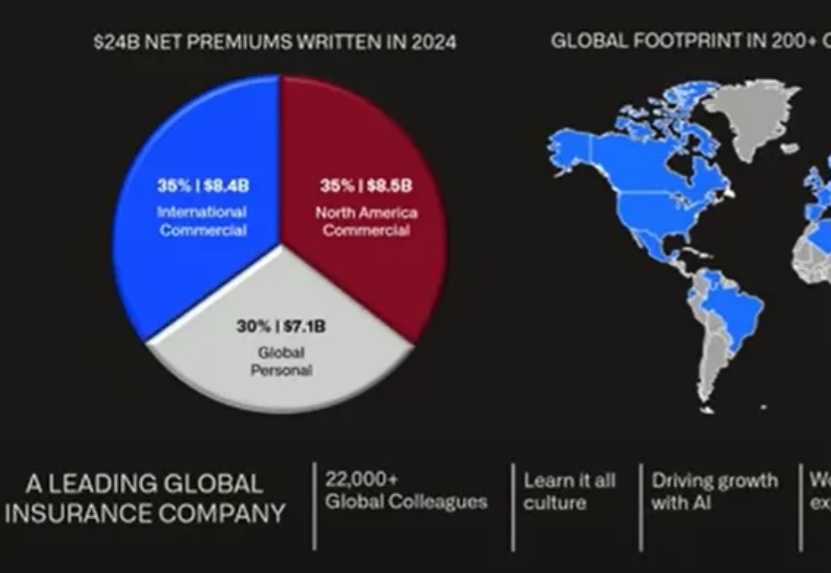
AI应用股王Palantir在6月举办的7thAIP Conference公布了最新一批Agent用例,Palantir公布Agent新用例,不止于next level|AIPCon7介绍了3家医疗客户用例,今天介绍的金融Agent,客户实践出来的企业AI落地原则非常有意义。

近日,德国AI学习平台Knowunity宣布完成2700万欧元B轮融资,融资总额达4500万欧元。本轮融资将用于进一步开发AI学伴产品,并继续拓展国际市场。