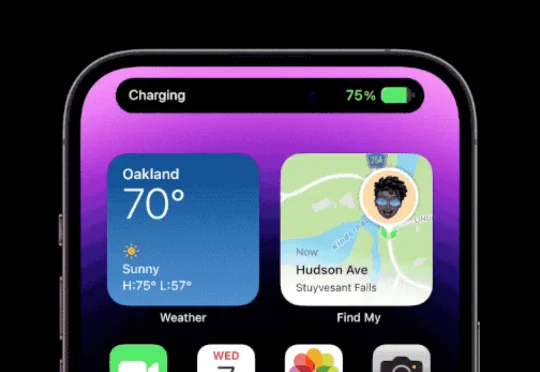
灵动岛,正在成为 AI 时代的新门面
灵动岛,正在成为 AI 时代的新门面真正把灵动岛推上风口的,是 6 月以来接连发生的几件事。6 月 8 日的 WWDC 2026,苹果发布了全新的 Siri AI。Federighi 在台上的原话是,苹果要「带来下一代 Apple Intelligence,并推出 Siri AI,一个明显更聪明、更博学、也更能干的 Siri」。
来自主题: AI资讯
7982 点击 2026-06-20 10:25
 搜索
搜索
真正把灵动岛推上风口的,是 6 月以来接连发生的几件事。6 月 8 日的 WWDC 2026,苹果发布了全新的 Siri AI。Federighi 在台上的原话是,苹果要「带来下一代 Apple Intelligence,并推出 Siri AI,一个明显更聪明、更博学、也更能干的 Siri」。
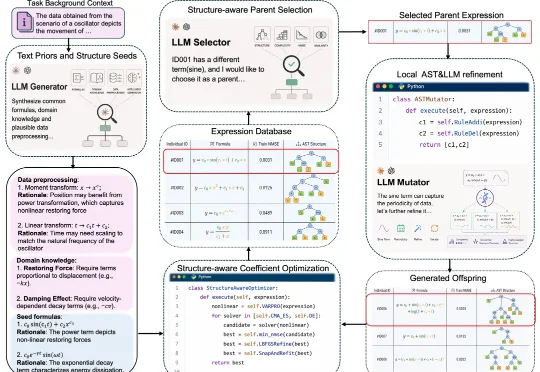
来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;

据英国《金融时报》昨日报道,美国AI独角兽、世界模型创企Odyssey获得3.1亿美元(约合人民币20.96亿元)融资,本轮融资落地后,该公司投后估值将达14.5亿美元(约合人民币98.05亿元)。
全员本科生! 刚刚,何恺明携本科生“军团”又放出一篇新论文。

今年618的关键词,无疑是AI。

Bessemer(投出过 Shopify、Twilio 那家老牌 VC)发了一篇讲 AI 时代怎么找 PMF(产品市场契合)的文章。开篇就把一个我们默认的错觉点破了:

6月初,优必选旗下的消费级人形机器人品牌优世界宣布将发布全球首款全尺寸超仿生人形机器人。目前,这款机器人已经开启预售,但还没有公布详细的参数。通过预售界面信息,我们能了解的是,这款超仿生机器人拥有和真人一样的尺寸,其中男款身高183cm、体重42kg,女款身高168cm、体重35.2kg。
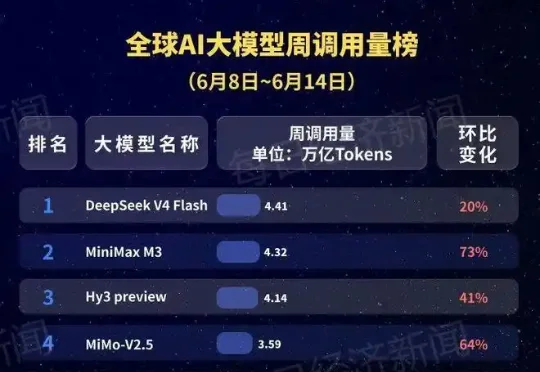
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。

卧槽,这事真的太抽象了。
《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。