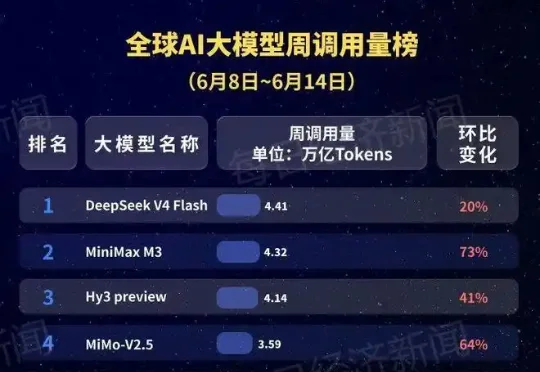
18.42万亿Token!中国AI大模型周调用量连续七周领跑:MiniMax M3升至第二
18.42万亿Token!中国AI大模型周调用量连续七周领跑:MiniMax M3升至第二根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
来自主题: AI资讯
9172 点击 2026-06-17 15:26
 搜索
搜索
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。

卧槽,这事真的太抽象了。
《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

逆矩阵计划于 2026 年底发布旗舰模型。
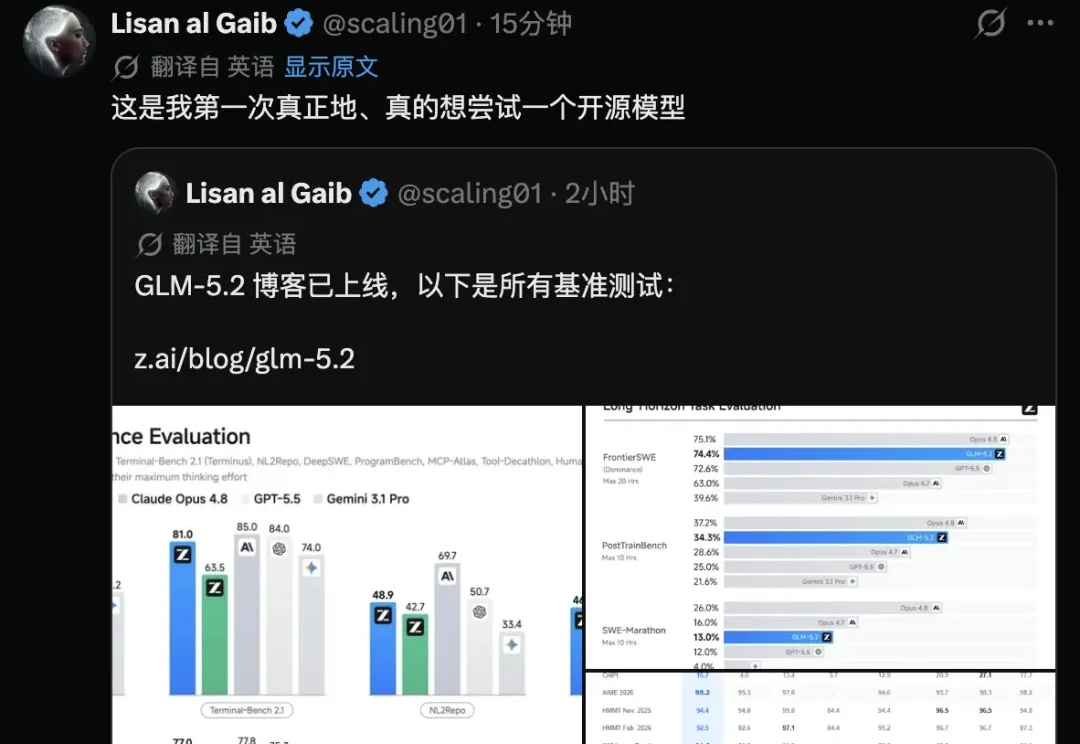
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
这是个一个月前的旧消息, 4月28日,达摩院联合广东省人民医院, 发布了一个叫DAMO COCA的, 肠癌筛查AI模型。
这绝对是近期把“反向创新”和“互联网幽默”玩到极致的一个案例,当整个 AI 行业都在比拼模型参数、Agent 框架、推理能力和算力规模时,一个 17 岁印度高中生却用一种近乎恶作剧的方式,创造了 2026 年最幽默的一个产品。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。