
谷歌科学家Nicholas Carlini:17个AI用法,让打工人效率翻倍
谷歌科学家Nicholas Carlini:17个AI用法,让打工人效率翻倍谷歌DeepMind 研究科学家 Nicholas Carlini,一位机器学习和计算机安全领域的大牛。以最贴近现实实用的角度,分享了他对大模型的看法,以及自己对大模型应用的50个案例。
来自主题: AI资讯
7966 点击 2025-03-05 08:49
 搜索
搜索
谷歌DeepMind 研究科学家 Nicholas Carlini,一位机器学习和计算机安全领域的大牛。以最贴近现实实用的角度,分享了他对大模型的看法,以及自己对大模型应用的50个案例。
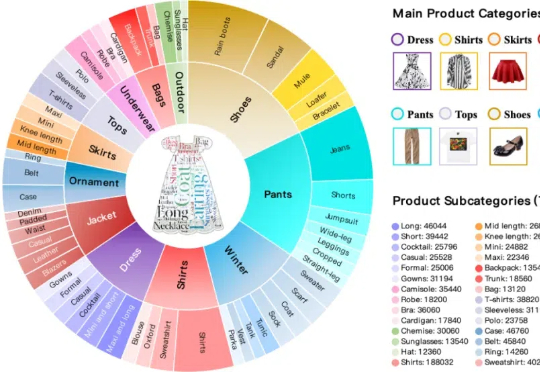
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。

随着 DeepSeek 问世,从春节至今,和AI有关的资讯与讨论已经让人有些疲劳。然而,相关讨论大都聚焦在产业、投资和技术方面,其中不乏优质信息,但仍缺少一个重要的视角——作为普通用户,我们如何看待并使用AI。

去年10月,家族元老41岁的孙子Kuok Meng Wei执掌的集团非上市子公司K2 Strategic在占地700英亩的塞德纳克科技园(Sedenak Tech Park)开设了一座60兆瓦的数据中心(容量以能耗计)。

刚刚,Claude背后公司Anthropic官宣新一轮融资: 35亿美元!投后估值达到615亿。 在Clauede-3.7发布后,此轮新融资便浮出水面,并在今天正式公布。
满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。

一年一度,今年的世界移动通信大会(MWC)如期在巴塞罗那开展。 不出所料,巴展无处不AI。 连没有前来参会的DeepSeek也有被cue到。

近日,开立医疗成功获得了国内首个产前超声人工智能医疗器械证。这一历史性的突破奠定了开立医疗在医疗行业智能化领域的先锋地位。
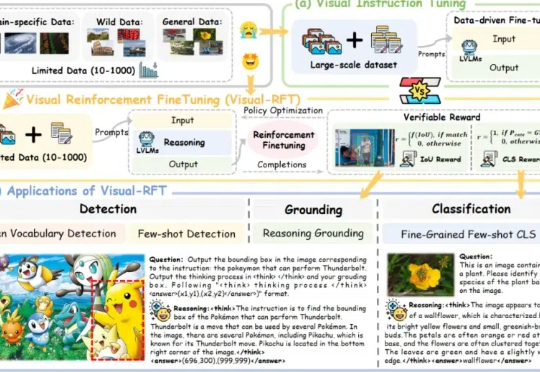
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!
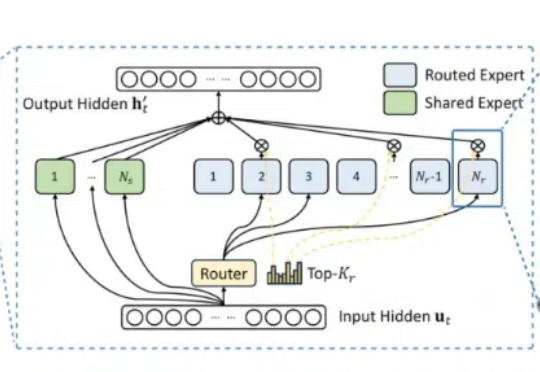
DeepSeek MoE“变体”来了,200美元以内,内存需求减少17.6-42%! 名叫CoE(Chain-of-Experts),被认为是一种“免费午餐”优化方法,突破了MoE并行独立处理token、整体参数数量较大需要大量内存资源的局限。