
行业洞察|AI独角兽的战略摇摆。
行业洞察|AI独角兽的战略摇摆。2024年11月29日,北京中关村某会议中心。智谱AI的技术开放日现场气氛热烈。CEO张鹏站在台上,面带微笑地说了一句话:"AutoGLM,帮我给现场观众发个红包。"
来自主题: AI资讯
9418 点击 2024-12-18 15:02
 搜索
搜索
2024年11月29日,北京中关村某会议中心。智谱AI的技术开放日现场气氛热烈。CEO张鹏站在台上,面带微笑地说了一句话:"AutoGLM,帮我给现场观众发个红包。"
《智能涌现》独家获悉,爱诗科技近期正式完成A2-A4轮融资,总额近3亿元人民币。投资方包括蚂蚁集团、北京市人工智能产业投资基金、国科投资及光源资本。

像一只毛绒绒的小拖鞋,能发出轻柔地「吱吱」叫,甚至能根据环境变化来表达自己的情绪,在日本留学的koko在官网蹲守几个月后,终于在mercari(日本二手商品应用)入手了这个名叫Moflin的AI玩具,过去一周来,她会带着Moflin去上课、吃饭,观察它的情绪变化。

OpenAI宕机因Kubernetes监控服务过载,承诺改进排障及预防措施。
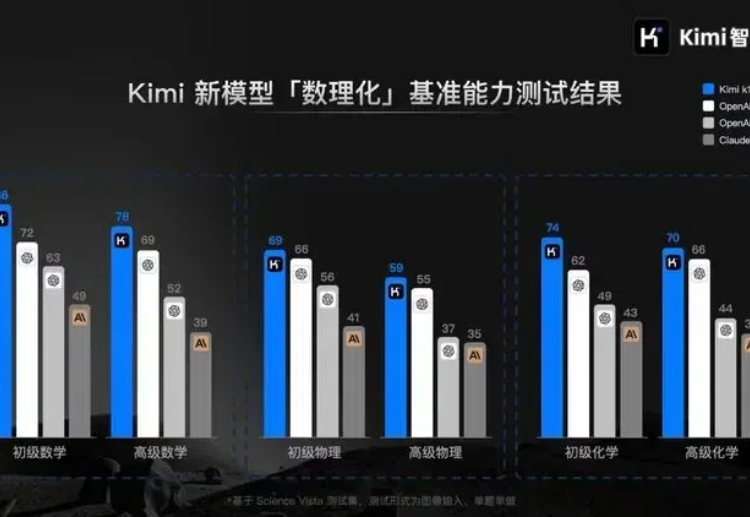
大洋彼岸的OpenAI系列春晚还在继续,连续发布会的第9天,OpenAI正式发布了o1模型的API。

12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。
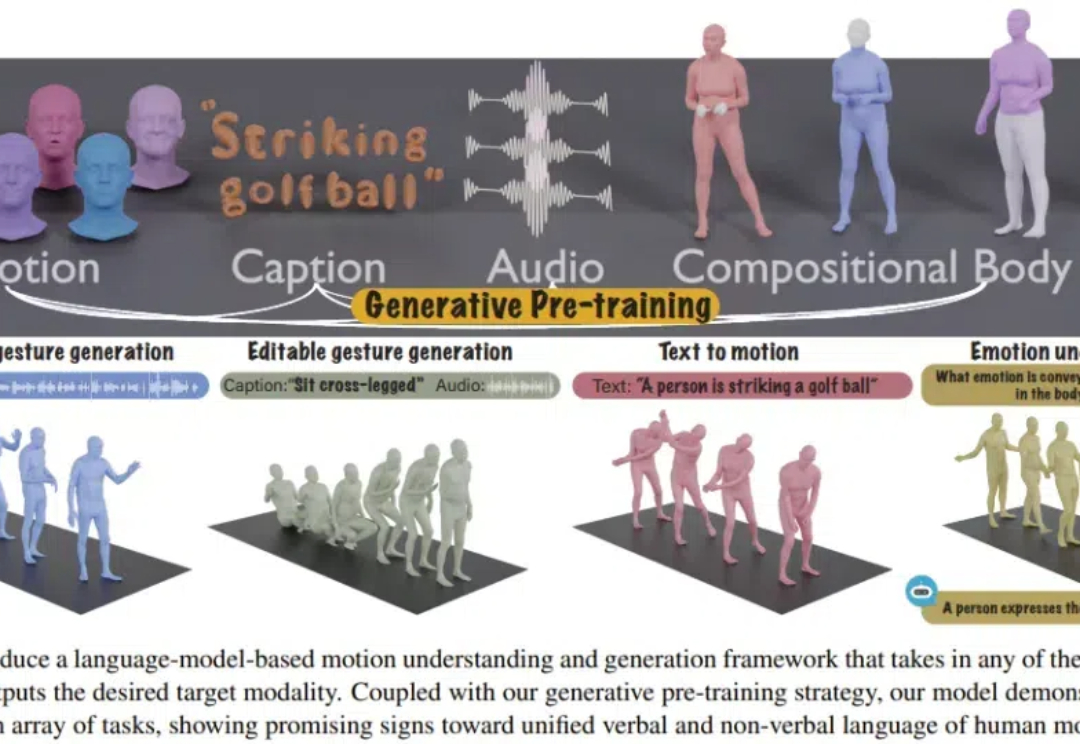
人类的沟通交流充满了多模态的信息。为了与他人进行有效沟通,我们既使用言语语言,也使用身体语言,比如手势、面部表情、身体姿势和情绪表达。
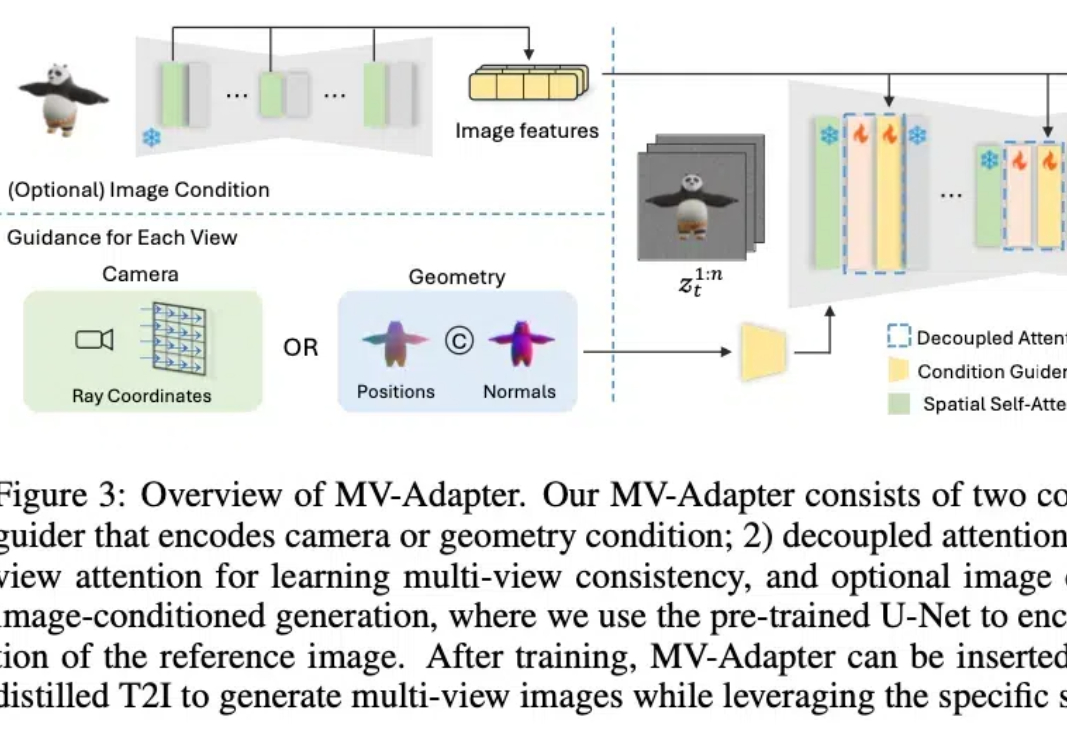
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。

明年的国际消费类电子产品展览会(CES 2025)将在北京时间 1 月 8 日至 11 日举行,包括英特尔、英伟达和 AMD 在内的各大 CPU、GPU 厂商将带着自家最新产品闪亮登场。
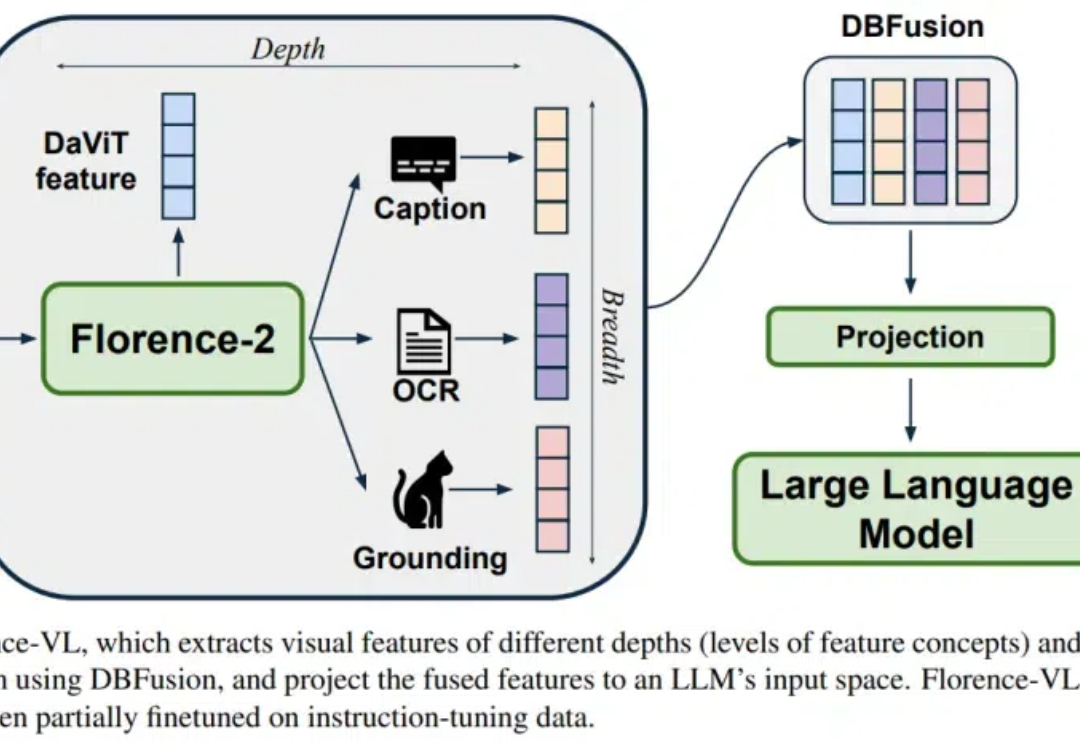
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。